
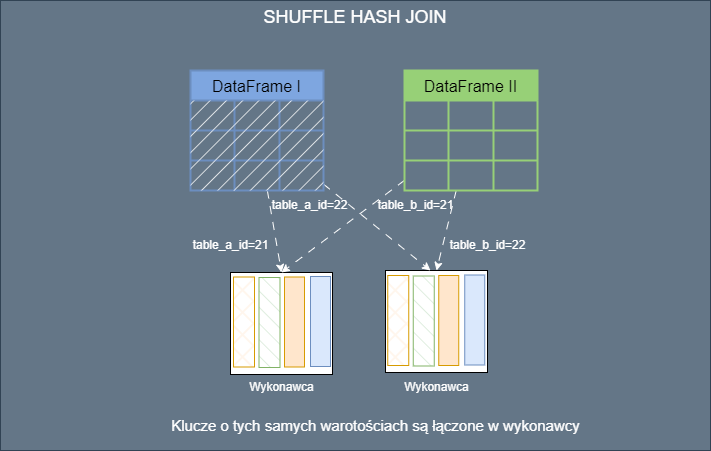
Nie znam rozwiązania gdzie nie trzeba połączyć jakiś tabel. Możesz pracować przy różnych modelach architektonicznych takich jak Lakehouse czy Warehouse bądź innym cudzie technologii. W każdym przypadku pracując z Apache Spark będziesz łączył(ła) tabelę. Małe duże, rozproszone czy nie jakoś join trzeba zrobić. Najczęściej po prostu robisz join i nic innego Cię nie interesuje. … [Więcej ...] oJak Spark robi join?
Spark
7 rzeczy do optymalizacji Apache Spark
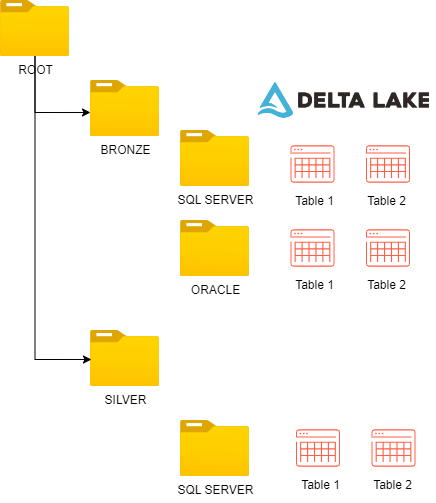
Apache Spark jest narzędziem bardzo skomplikowanym, i nie wielu z nas ma czasu na czytanie kodu źródłowego. Tego wszystkiego jest za dużo. Również podczas projektu nie ma za wiele czasu na dogłębna analizę. Zadbaj o to żeby uprościć sobie życie. Chciałem tutaj zebrać najważniejsze elementy z procesu optymalizacji. Mają one Ci pomóc w jak najszybszym podkręceniu procesu. Czasami … [Więcej ...] o7 rzeczy do optymalizacji Apache Spark
Co warto wiedzieć o pamięci wykonawcy (executor)

Dwa podstawowe problemy z jakimi się często spotykam związane są z osiągami jakie jestem w stanie uzyskać w Spark. Tobie też może się to przydarzyć jeśli już się nie wpadłeś w podobną pułapkę. Z mojego punktu widzenia to najczęstsze co mi się przydarza. Aplikacja zaczyna mulić lub pada z wielkim hukiem. 😁 Recept jest pewnie tyle ile jest problemów, ale chciałbym się … [Więcej ...] oCo warto wiedzieć o pamięci wykonawcy (executor)
Tabele Delta jak działa płynne kastrowanie (Liquid Clustering)

Partycjonowanie danych Partycjonowanie powstało po to żeby posegregować dane. Jeśli masz milion plików i chcesz wyciągnąć konkretną informację, to chwilę będziesz musisz poczekać. I ta chwila może potrwać sporo czasu i do tego przepalisz sporo kasy. Tutaj wkracza partycjonowanie, czyli pogrupowanie danych według jakiegoś klucza. Żeby dobrze dobrać partycję musisz … [Więcej ...] oTabele Delta jak działa płynne kastrowanie (Liquid Clustering)
Apache Spark operacje na kolumnach

Kolumny Kolumny w Spark Dataframe maja taką samą charakterystykę, jak w przypadku Pandas czy R DataFrames, na pewno znasz je z excela, bądź bazy relacyjnej. Koncepcja jest taka sama. Możesz dokonywać różnych operacji na wybranych lub wszystkich kolumnach. Operacje te będą zależeć od typu danych kolumny. W Sparku możesz odnieść się do kolumny na kilka sposobów w … [Więcej ...] oApache Spark operacje na kolumnach
Jak walidować schemat danych w Apache Spark

Walidacja schematu danych jest bardzo ważnym etapem, w każdym projekcie z danymi. Jest to klucz do sukcesu i należy go potraktować poważnie. Poniżej znajdziesz przykłady jak walidować schemat danych i jakie masz dostępne narzędzia w Apache Spark i Databricks. Oczywiście możesz zrobić znacznie więcej dla jakości danych, ale to są podstawy dla pierwszej wersji twojego … [Więcej ...] oJak walidować schemat danych w Apache Spark
Co powinieneś wiedzieć o Spark Dataframe

Dataframe czyli ramka danych Ramka danych jest obiektem istniejącym w pamięci RAM. Najłatwiej ją zobrazować jako tabelę, która posiada kolumny oraz rzędy danych. Każda kolumna tak jak w bazie danych posiada nazwę oraz typ danych. Dataframe jest kolekcją obiektu Row (RDD[Row]) i schematu. Taka 'tabelka' w pamięci ma bardzo dużo zalet dla analityka. Łatwo z nią pracować, a … [Więcej ...] oCo powinieneś wiedzieć o Spark Dataframe
Apache Spark na Windowsie czy to możliwe?

Witam, do tej pory pisałem o Databricks jako o super narzędziu do Big Data. Jest on niewątpliwie bardzo użyteczny, ale do tego potrzeba przeglądarki i dostępu do chmury publicznej, Azure, AWS lub GCP. A co jeśli chcesz zacząć przygodę ze Apache Spark na Windowsie bez wydawania kasy na chmurę. Mam dla Ciebie dobre wieści jest to możliwe, żeby używać Big Data na kilku rdzeniach. … [Więcej ...] oApache Spark na Windowsie czy to możliwe?
Spark – Jakie ma komponenty ?

Sterownik (sparkcontext) Bardzo ważnym elementem Sparka jest Sparkcontext, jest to główny obiekt aplikacji. Zajmuje się on koordynacją procesów aplikacji. W bezpośrednim tłumaczeniu jest to główny ‘sterownik’, który jest niezbędny w całym cyklu życia aplikacji w klastrze. Każda aplikacja ma własne procesy wykonujące zadania. Kierownik klastra Nasz Sparkcontext … [Więcej ...] oSpark – Jakie ma komponenty ?
Czym jest Apache Spark
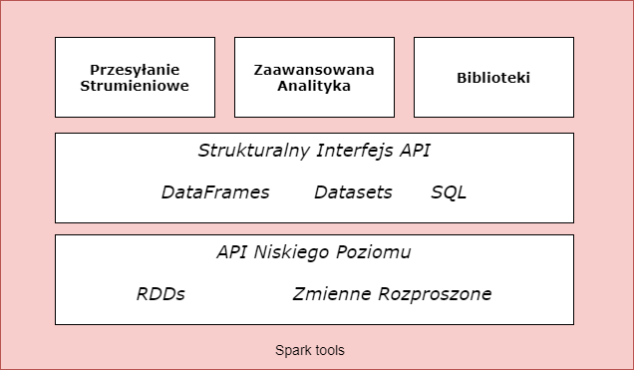
Apache Spark to silnik do przetwarzania danych. Zawiera całą masę bibliotek, których można używać do przetwarzania danych w klastrze komputerów. Najważniejszą korzyścią jest możliwość równoległego przetwarzania danych. Obecnie jest jednym z najpopularniejszych narzędzi do Big Data. Obsługuje wiele języków programowania (Python, SQL, Scala i R). Możesz rozwiązywać problemy na … [Więcej ...] oCzym jest Apache Spark