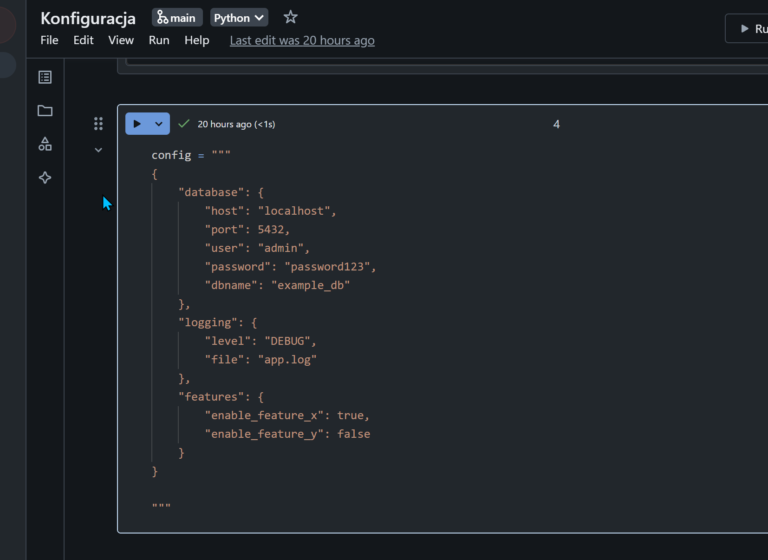
W wielu przypadkach ładowania danych w procesie ETL będziesz potrzebował/ła sparametryzować proces zasilania. Prawie każdy pipeline wymaga jakiś parametrów, np. nazwa tabeli, nazwa środowiska (dev, test, prod) ect.. Im bardziej skomplikowany pipeline tym więcej parametrów potrzeba. Jeśli parametrów jest kilka to możemy je nazwać pop prostu "parametrami" 😁, ale jak się pipeline … [Więcej ...] oKilka pomysłów na konfigurację Databricks

Cegładanych
Dane - Databricks i Chmura Azura
Footer
Informacje Prawne
To jest nudna część lecz wymagana, wszystkie notki prawne o stronie znajdziecie tutaj.