
Dataframe czyli ramka danych
Ramka danych jest obiektem istniejącym w pamięci RAM. Najłatwiej ją zobrazować jako tabelę, która posiada kolumny oraz rzędy danych. Każda kolumna tak jak w bazie danych posiada nazwę oraz typ danych. Dataframe jest kolekcją obiektu Row (RDD[Row]) i schematu. Taka 'tabelka’ w pamięci ma bardzo dużo zalet dla analityka. Łatwo z nią pracować, a dodatkowo masz całą masę dostępnych funkcji do pracy na wierszach i kolumnach. Dataframe są niezmienne, każda ramka w pamięci nie może być zmieniona, jeśli chcesz dodać lub usunąć wartości to musisz stworzyć nową. Nazwy kolumn możesz wyczytać ze źródła bądź co jest bardziej poprawne stworzyć ze schematu.

Dataframe nie tylko wspiera podstawowe typy danych ale również skomplikowane. Oto przykłady: maps, structs, dates, timestamp, fields. Lista wszystkich typów danych w Apache Spark Dataframe. Wszystkie typy danych są dostępne w paczce import org.apache.spark.sql.types._ lub dla pythona from pyspark.sql.types import *
| Data type | Value type in Scala | API to access or create a data type |
| ByteType | Byte | ByteType |
| ShortType | Short | ShortType |
| IntegerType | Int | IntegerType |
| LongType | Long | LongType |
| FloatType | Float | FloatType |
| DoubleType | Double | DoubleType |
| DecimalType | java.math.BigDecimal | DecimalType |
| StringType | String | StringType |
| BinaryType | Array[Byte] | BinaryType |
| BooleanType | Boolean | BooleanType |
| TimestampType | java.sql.Timestamp | TimestampType |
| DateType | java.sql.Date | DateType |
| ArrayType | scala.collection.Seq | ArrayType(elementType, [containsNull]) Note: The default value of containsNull is true. |
| MapType | scala.collection.Map | MapType(keyType, valueType, [valueContainsNull]) Note: The default value of valueContainsNull is true. |
| StructType | org.apache.spark.sql.Row | StructType(fields) Note: fields is a Seq of StructFields. Also, two fields with the same name are not allowed. |
| StructField | The value type in Scala of the data type of this field(For example, Int for a StructField with the data type IntegerType) | StructField(name, dataType, [nullable]) Note: The default value of nullable is true. |
Jak stworzyć Dataframe
Jest kilka metod żeby stworzyć Dataframe w Apache Spark.
Najczęściej będziesz to robił wczytując plik z dysku. Bądź pobierając dane z bazy lub z tabel Hive. Możesz też użyć metody createDataFrame(), bądź stworzyć ją z obiektu Row.
- JSON
- parquet
- JDBC
- ORC
- Tabele Hive lub bazę zgodną ze standardem JDBC
Schemat danych (schema)
Bardzo ważnym etapem przy przetwarzaniu danych jest walidacja pliku. Na tym etapie sprawdź czy nazwy kolumn i ich typy danych pasują do schematu. Schemat danych to nic innego jak lista kolumn jakie powinien mieć Dataframe oraz typ danych np. String, Integer, Array ect.
Jak stworzyć schemat danych
Są dwie najważniejsze metody do stworzenia schematu danych.
- Programatycznie przy użyciu skryptu
- Przy użyciu DDL (Data Definition Language)
- Wczytać schemat z pliku
%scala
import org.apache.spark.sql.types._
// 1. Tworzenie schematu z typu StructType
val schema = StructType(
Array(StructField("Spark Version",StringType,true),
StructField("Scala Version",StringType,true),
StructField("Repository",StringType,true),
StructField("Usages",IntegerType,true),
StructField("Date",StringType,true),
StructField("Updated",IntegerType,true)))
// 2. DDL
val schema2 = "`Date` STRING, `Repository` STRING, `Scala Version` STRING, `Spark Version` STRING, `Updated` INT, `Usages` INT"
// 3. Schemat można stworzyć z pliku np json
val schema3 = spark.read.format("json").option("multiline","true").load("/FileStore/tables/dataframe.json").schema
// 4. Jeśli zajdzie potrzeba możesz pobrać schemat z dysku w formie json, czsami jest to przydatne
val schema4 = spark.read.format("json").option("multiline","true").load("/FileStore/tables/dataframe.json").schema.json
%python
from pyspark.sql.types import *
# 1. Tworzenie schematu z typu StructType
schema = StructType([StructField("Spark Version",StringType(),True),
StructField("Scala Version",StringType(),True),
StructField("Repository",StringType(),True),
StructField("Usages",IntegerType(),True),
StructField("Date",StringType(),True),
StructField("Updated",IntegerType(),True)])
# 2. DDL
schema2 = "`Date` STRING, `Repository` STRING, `Scala Version` STRING, `Spark Version` STRING, `Updated` INT, `Usages` INT"
# 3. Schemat można stworzyć z pliku np json
schema3 = spark.read.format("json").option("multiline","true").load("/FileStore/tables/dataframe.json").schema
# 4. Jeśli zajdzie potrzeba możesz pobrać schemat do json, czsami jest to przydatne
schema4 = spark.read.format("json").option("multiline","true").load("/FileStore/tables/dataframe.json").schema.json
Tworzymy ramki danych z pliku
Najczęściej spotykana metoda to tworzenie ramki danych z pliku, w zależności od formatu (json, csv, avro, parquet, text, orc) możesz do tego użyć klasy DataFrameReader
%scala
val file = spark.read.format("json")
.option("multiline","true")
.schema(schema)
.load("/FileStore/tables/dataframe.json")
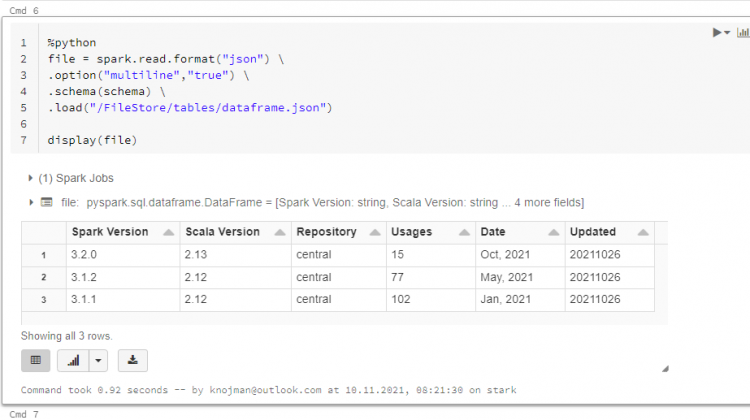
%python
file = spark.read.format("json") \
.option("multiline","true") \
.schema(schema) \
.load("/FileStore/tables/dataframe.json")
Tworzymy Dataframe używając metod createDataFrame() i toDF()
%scala
val kolumny = Seq("Spark Version","Scala Version", "Repository", "Usages", "Date", "Updated")
val dane = Seq(
("3.2.0", "2.13", "central", 15, "Oct, 2021", 20211026),
("3.1.2", "2.12", "central", 77, "May, 2021", 20211026),
("3.1.1", "2.12", "central", 102, "Jan, 2021", 20211026))
val df = spark.createDataFrame(dane).toDF(kolumny:_*)
%python
kolumny = ["Spark Version","Scala Version", "Repository", "Usages", "Date", "Updated"]
dane = [("3.2.0", "2.13", "central", 15, "Oct, 2021", 20211026),
("3.1.2", "2.12", "central", 77, "May, 2021", 20211026),
("3.1.1", "2.12", "central", 102, "Jan, 2021", 20211026)]
df = spark.createDataFrame(dane).toDF(*kolumny)
Tworzenie ramki danych z tabeli SQL Server
%scala
val user = "sqladminuser..."
val password = "Password..."
val jdbc = "jdbc:sqlserver://acmeservercentral.database.windows.net:1433;database=db_sqlmain;slProtocol=TLSv1"
val driver = "com.microsoft.sqlserver.jdbc.SQLServerDriver"
val listOfTables = spark.read
.format("jdbc")
.option("url", jdbc)
.option("user", user)
.option("password", password)
.option("driver", driver)
.option("query",s"SELECT * FROM information_schema.tables'")
.load()
%python
user = "sqladminuser..."
password = "Password..."
jdbc = "jdbc:sqlserver://acmeservercentral.database.windows.net:1433;database=db_sqlmain;slProtocol=TLSv1"
driver = "com.microsoft.sqlserver.jdbc.SQLServerDriver"
listOfTables = spark.read \
.format("jdbc") \
.option("url", jdbc) \
.option("user", user) \
.option("password", password) \
.option("driver", driver) \
.option("query",s"SELECT * FROM information_schema.tables'") \
.load()
Tworzenie Pandas DataFrame przy użyciu Python
Pandas są obiektem występującym tylko w Pythonie, jeśli masz Pandas DataFrame to bardzo łatwo możesz go transformować do sparkowej ramki danych.
%python
import pandas as pd
dane = [["3.2.0", "2.13", "central", 15, "Oct, 2021", 20211026],
["3.1.2", "2.12", "central", 77, "May, 2021", 20211026],
["3.1.1", "2.12", "central", 102, "Jan, 2021", 20211026]]
kolumny = ["Spark Version","Scala Version", "Repository", "Usages", "Date", "Updated"]
pandasDF = pd.DataFrame(dane, columns=kolumny)
sparkDf = spark.createDataFrame(pandasDF)
display(sparkDf)
Tworzenie ramki danych przy użyciu Case Classes w Scali
%scala
case class Spark(sparkVersion: String, scalaVersion: String, repository: String, usages: Long, date: String, updated: Long)
val dane = Seq(Spark("3.2.0", "2.13", "central", 15, "Oct, 2021", 20211026),
Spark("3.1.2", "2.12", "central", 77, "May, 2021", 20211026),
Spark("3.1.1", "2.12", "central", 102, "Jan, 2021", 20211026))
val df = spark.createDataFrame(dane)
Tworzenie ramki danych z obiektu Row
%scala
import org.apache.spark.sql.Row
import org.apache.spark.sql.types._
val rows = Seq(
Row("3.2.0", "2.13", "central", 15, "Oct, 2021", 20211026),
Row("3.1.2", "2.12", "central", 77, "May, 2021", 20211026),
Row("3.1.1", "2.12", "central", 102, "Jan, 2021", 20211026))
val auctions = spark.createDataFrame(spark.sparkContext.parallelize(rows), schema)
%python
from pyspark.sql import Row
rows = [Row("3.2.0", "2.13", "central", 15, "Oct, 2021", 20211026),
Row("3.1.2", "2.12", "central", 77, "May, 2021", 20211026),
Row("3.1.1", "2.12", "central", 102, "Jan, 2021", 20211026)]
data = spark.createDataFrame(spark.sparkContext.parallelize(rows), schema)
Tutaj możesz pobrać notatnik Databricks DataFrame.dbc z przykładami.
Stworzenie obiektu Dataframe jest raczej łatwe, a kiedy jest w pamięci to już prosta droga do wykonania operacji analitycznych takich jak filtrowanie, liczenie, agregowanie, grupowanie ect. Dzięki takiej strukturze danych praca analityka jest znacznie łatwiejsza ponieważ przy mniejszej ilości kodu możesz osiągnąć więcej. W tym artykule znajdziesz trochę przydatnego kodu.