
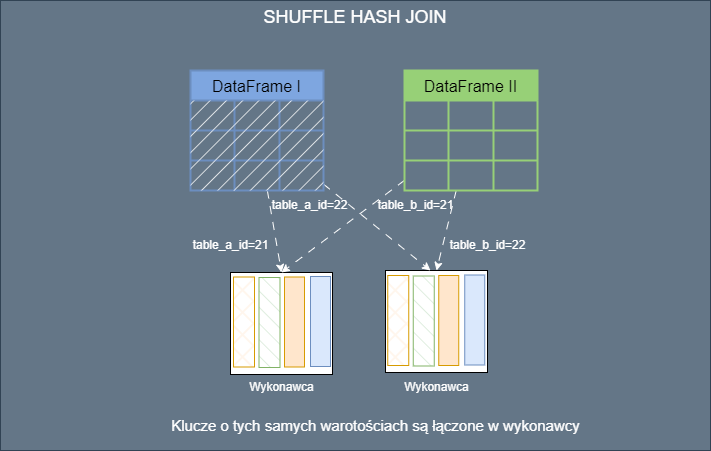
Nie znam rozwiązania gdzie nie trzeba połączyć jakiś tabel. Możesz pracować przy różnych modelach architektonicznych takich jak Lakehouse czy Warehouse bądź innym cudzie technologii. W każdym przypadku pracując z Apache Spark będziesz łączył(ła) tabelę. Małe duże, rozproszone czy nie jakoś join trzeba zrobić. Najczęściej po prostu robisz join i nic innego Cię nie interesuje. … [Więcej ...] oJak Spark robi join?
Spark
Apache Spark na Windowsie czy to możliwe?

Witam, do tej pory pisałem o Databricks jako o super narzędziu do Big Data. Jest on niewątpliwie bardzo użyteczny, ale do tego potrzeba przeglądarki i dostępu do chmury publicznej, Azure, AWS lub GCP. A co jeśli chcesz zacząć przygodę ze Apache Spark na Windowsie bez wydawania kasy na chmurę. Mam dla Ciebie dobre wieści jest to możliwe, żeby używać Big Data na kilku rdzeniach. … [Więcej ...] oApache Spark na Windowsie czy to możliwe?
Spark – Jakie ma komponenty ?

Sterownik (sparkcontext) Bardzo ważnym elementem Sparka jest Sparkcontext, jest to główny obiekt aplikacji. Zajmuje się on koordynacją procesów aplikacji. W bezpośrednim tłumaczeniu jest to główny ‘sterownik’, który jest niezbędny w całym cyklu życia aplikacji w klastrze. Każda aplikacja ma własne procesy wykonujące zadania. Kierownik klastra Nasz Sparkcontext … [Więcej ...] oSpark – Jakie ma komponenty ?
Jak za darmo bawić się Big Data
Domyślam się, że wielu z was chciałoby sprawdzić, jak działa ta magiczna technologia. I jest nadzieja dla wszystkich. Zupełnie za darmo jest dostępna platforma do Big Data, będąc bardzo precyzyjnym do Sparka. Zwie się ona Databricks Community Edition. https://community.cloud.databricks.com/login.html Jest to bezpłatna wersja Databricks, czyli zestawu narzędzi do … [Więcej ...] oJak za darmo bawić się Big Data
Czym jest Apache Spark
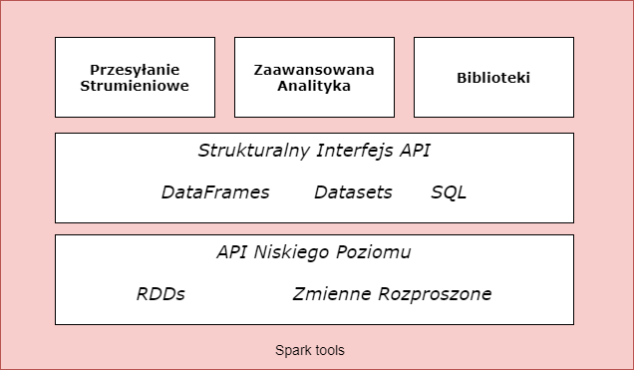
Apache Spark to silnik do przetwarzania danych. Zawiera całą masę bibliotek, których można używać do przetwarzania danych w klastrze komputerów. Najważniejszą korzyścią jest możliwość równoległego przetwarzania danych. Obecnie jest jednym z najpopularniejszych narzędzi do Big Data. Obsługuje wiele języków programowania (Python, SQL, Scala i R). Możesz rozwiązywać problemy na … [Więcej ...] oCzym jest Apache Spark