
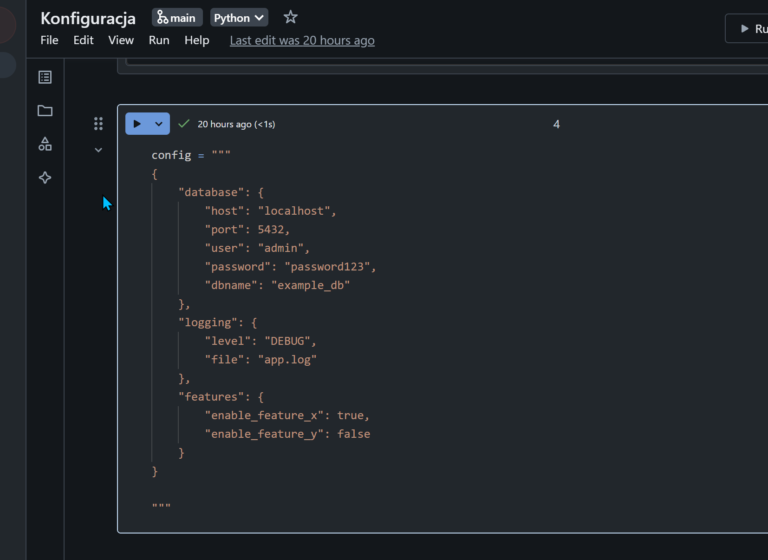
W wielu przypadkach ładowania danych w procesie ETL będziesz potrzebował/ła sparametryzować proces zasilania. Prawie każdy pipeline wymaga jakiś parametrów, np. nazwa tabeli, nazwa środowiska (dev, test, prod) ect.. Im bardziej skomplikowany pipeline tym więcej parametrów potrzeba. Jeśli parametrów jest kilka to możemy je nazwać pop prostu "parametrami" 😁, ale jak się pipeline … [Więcej ...] oKilka pomysłów na konfigurację Databricks
ETL
Jak oszczędziłem 8000 zł klientowi i nie użyłem Azure Data Factory
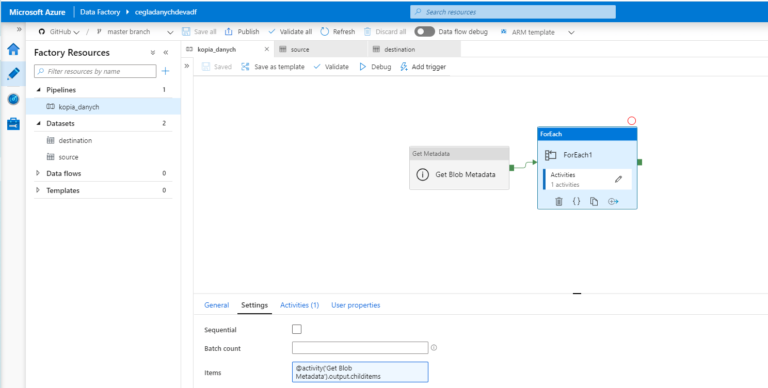
Pewnego pięknego dnia rozpoczął się sprint. Miałem bojowe zadanie do wykonania, mianowicie przekopiować trochę danych z jednego kontenera w blobie do drugiego. Żeby być precyzyjnym około 15 TB. Jest to już znacząca ilość danych i wymaga przemyślenia jak wykonać tę operację. Dane dotyczyły kilku źródeł danych, było ich 5. Każde z tych danych miały inną charakterystykę, trochę … [Więcej ...] oJak oszczędziłem 8000 zł klientowi i nie użyłem Azure Data Factory