Sterownik (sparkcontext)
Bardzo ważnym elementem Sparka jest Sparkcontext, jest to główny obiekt aplikacji. Zajmuje się on koordynacją procesów aplikacji. W bezpośrednim tłumaczeniu jest to główny ‘sterownik’, który jest niezbędny w całym cyklu życia aplikacji w klastrze. Każda aplikacja ma własne procesy wykonujące zadania.
Kierownik klastra
Nasz Sparkcontext łączy się z kilkoma managerami klastra:
Ich zadaniem jest przypisanie zasobów dla aplikacji. Do przetwarzania danych spark potrzebuje programów wykonawczych (Executorów), które zajmują się obliczeniami i mają dostęp do danych (w Azure Databricksy są oparte na wirtualnych maszynach), które zajmują się przetwarzaniem danych.
Typy menedżera klastrów
- Standalone – prosty menedżer klastrów dołączony do Spark.
- Apache Mesos – ogólny menedżer klastra, który może również uruchamiać Hadoop MapReduce.
- Hadoop YARN – menedżer zasobów w Hadoop 2.
- Kubernetes – system typu open source do automatyzacji wdrażania, skalowania i zarządzania aplikacjami kontenerowymi.
Wykonawcy (Executors)
Sterownik wysyła zadania do uruchomienia. Klaster manager komunikuje się z programami wykonawczymi i przydziela im zasoby. Spark również komunikuje się bezpośrednio z węzłami klastów (nodes). Każdy wykonawca jest odpowiedzialny za uruchomienie kodu i raportowanie stanu wykonania do sterownika.
Izolacja
Każda aplikacja ma swój własny proces wykonawczy działający wielowątkowo. Trzeba dodać, że aplikacje działają w izolacji. Każdy sterownik planuje swoje własne zadania. Po stronie wykonawczej każda aplikacja działa na osobnej maszynie JVM. Zapewnia to izolacje aplikacji i procesów a tym samym ma wpływ na stan systemu i jego osiągi.
Niezależność
Spark jest niezależny od głównego menedżera klastra. Może się on komunikować z wykonawcami.
Sieć
Sterownik musi być w ciągłej komunikacji z wykonawcami, a tym samym z siecią węzłów roboczych. Najkorzystniej jest, aby sterownik był w tej samej sieci lokalnej.
Interfejs Spark
Każdy program sterownika ma swój własny interfejs, dostępny na porcie 4040. Pozwala on monitorować wykonywane zadania. Można użyć przeglądarki i pod adresem http://<driver-node>:4040 będą dostępne dane z interfejsu. Jest to dostępne w lokalnej instalacji Spark. w Databricks mamy już dostępny interfejs webowy.
W Databricks jest on dostępny po wejściu na zakładkę “Clusters” otwieramy dostępny klaster. W górnej części pojawią się taby – kliknij na Spark UI, tam będą dostępne aktualne informacje o Sparku.
Tutaj mamy dostępne następujące elementy.
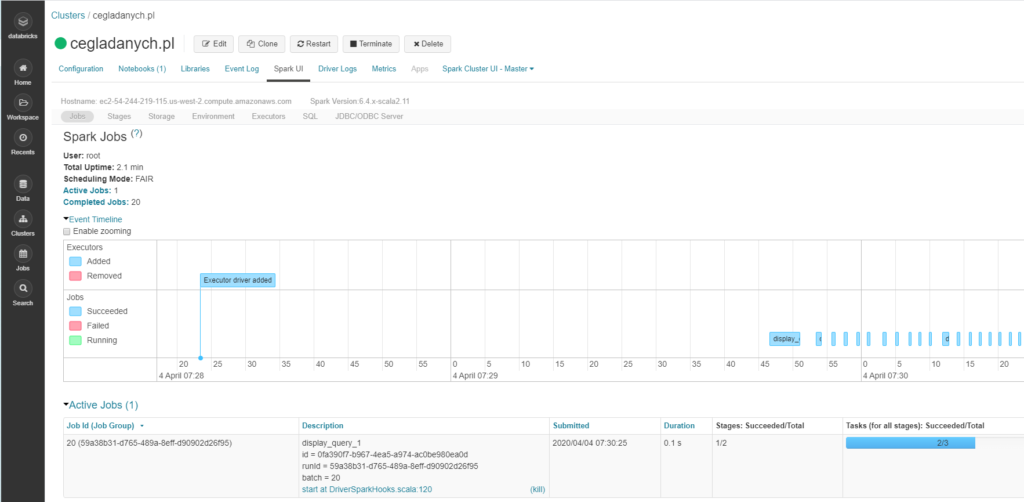
Jobs (zadania)
Tutaj widać zadania na osi czasu. Pokazuje zdarzenia w aplikacji Spark. Zadania są uruchamiane przez akcje, a nie transformacje. Akcję to np count(), saveAsTextFile(). Będziemy tutaj widzieć zadania równoległe, jakie są przetwarzanie przez wykonawców. Widok pozwala na wgląd w dane dla trzech różnych statystyk.
Widok pokazuje wszystkie zadania, i ich etapy. Najważniejszym elementem są zadania aktywne i wykonane. Możesz dowiedzieć się o tym, jak Spark wykonuje zadania aplikacji. Ten element jest bardzo ważny podczas debugowania / monitorowania aplikacji. Pozwala dowiedzieć się o poszczególnych etapach zadania. Jeśli wystąpią jakieś nieudane etapy, to powinno nas to zaalarmować.
Job Id (Job Group) – unikatowy ID zadania. Dzięki temu możemy go śledzić, a właściwie jego cykl życiowy
Description – tutaj są dodatkowe informacje pozwalające znaleźć więcej informacji o poszczególnych elementach zadania
Submitted – data i czas kiedy zadanie się rozpoczęło
Duration – czas wykonania
Stages: Succeeded/Total – ilość etapów, wszystkich i tych które ukończyły poprawnie
Tasks (for all stages): Succeeded/Total – zadania dla każdego etapu
Najnowsza wersja Spark wyświetla DAG wykonania dla każdego zadania. DAG – Direct Acyclic Graph czyli Bezpośredni Wykres Acykliczny. Tutaj link do wyjaśnienia procesu. Ten artykuł jest oparty na darmowej wersji Databricks Community Edition, która nie daje takiej opcji.
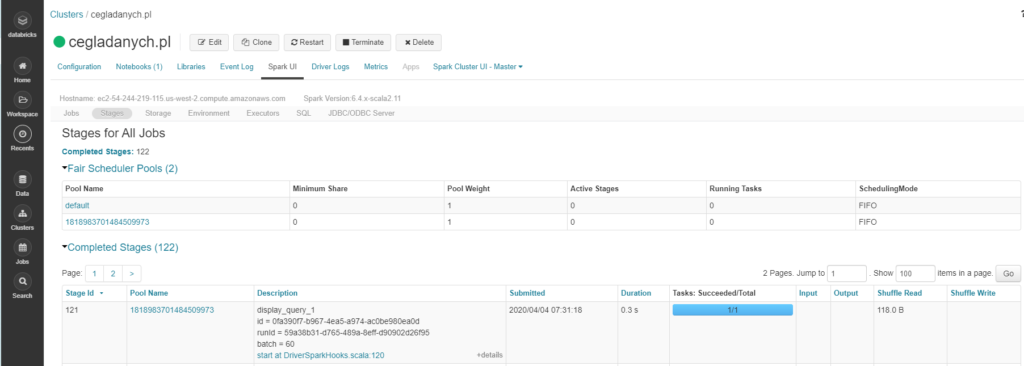
Stages (etapy)
Zadania dzielą się na etapy. Tutaj zobaczymy pojedyncze etapy każdego z zadań. Będzie widać jak, rozmieszczone są partycje na różnych komputerach. Ten widok pokaże nam, ile zadań jest przetwarzanych przez wykonawców. To pozwoli nam podjąć decyzje czy zwiększyć ilość rdzeni. Każdy nieudany etap powinien być alarmujący.
Stage Id – unikatowe id etapu
Pool Name – id pool
Description – jak w przypadku zadań są tutaj bardziej szczegółowe informacje dotyczące poszczególnych etapów. Można je odnaleźć po id, runid
Submitted – data i czas wykonania
Duration – czas wykonania
Tasks: Succeeded/Total – ilość poszczególnych tasków w etapie.
Input – ilość danych wejściowych wczytanych z dysku
Output – ilość danych wyjściowych zapisanych na dysk
Shuffle Read – liczba bajtów z wczytanych rekordów, dane lokalne i ze zdalnych wykonawców (proces tasowania 'shuffle’ )
Shuffle Write – bajty i rekordy zapisane na dysk, które będą użyte w procesie tasowania 'shuffle’
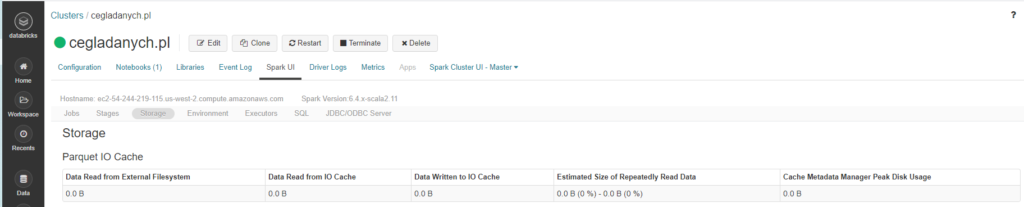
Storage (dysk)
Informacje dotyczące danych. Witać że na tym klastrze wiele nie ma. Ale to da się zmienić.
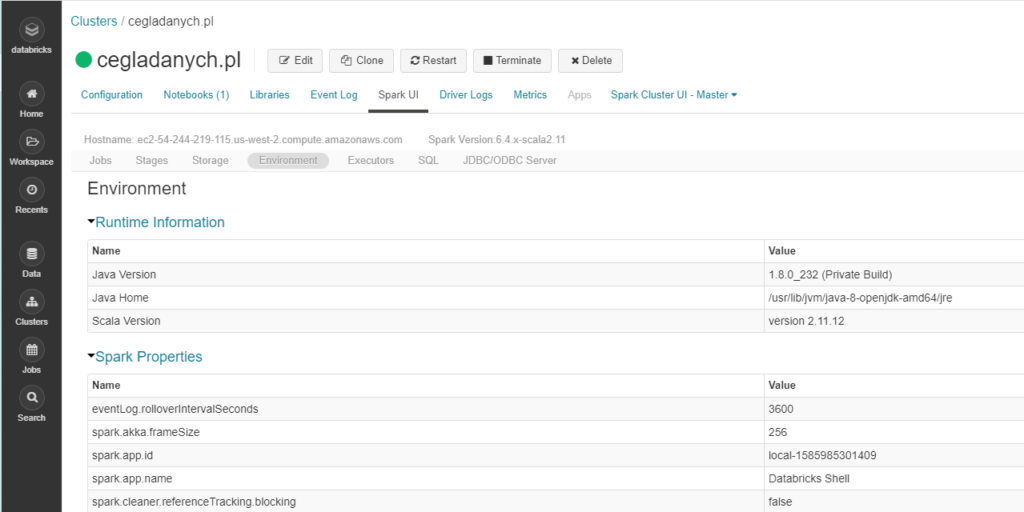
Environment (środowisko)
Ta strona zawiera informacje o środowisku węzłów wykonawczych. Czyli najważniejsze informacje wersja Java, Scala i dane Spark.
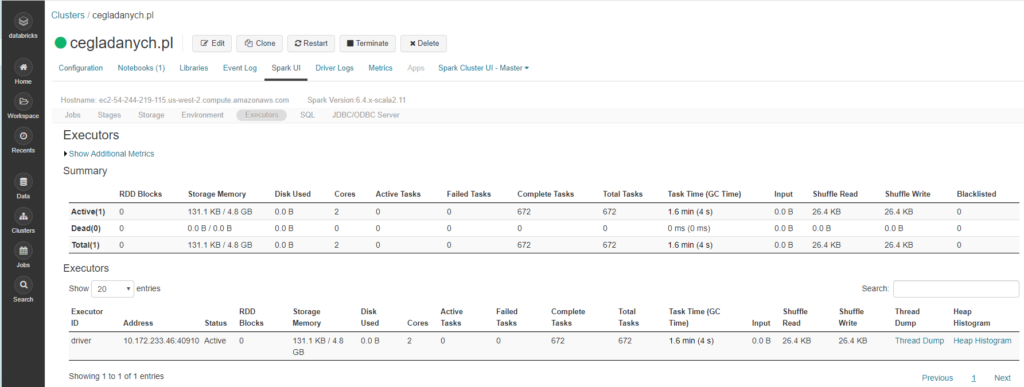
Executors (wykonawcy)
Tutaj są dostępne informacje o węzłach wykonawczych. Każdy węzeł jest opisany i widać jakie ma zasoby.
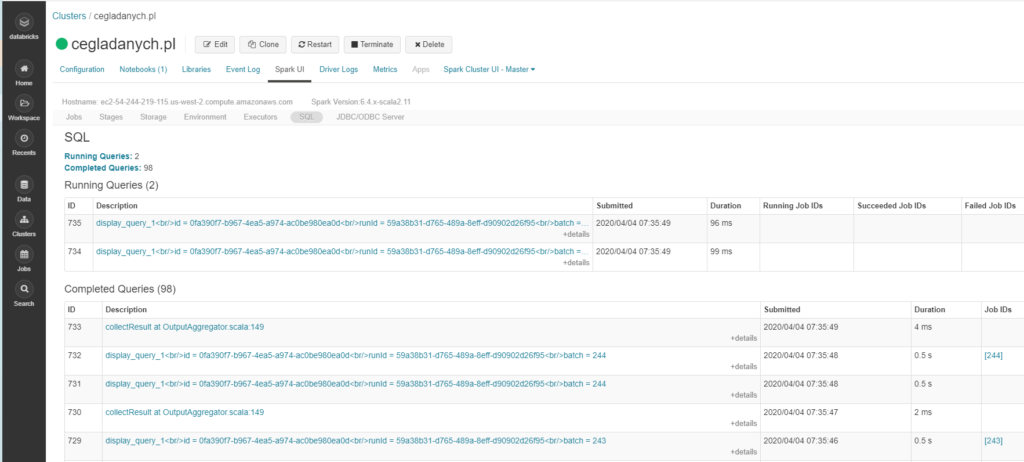
SQL
W tym miejscu sprawdzisz plan jakim jest wykonany przez silnik SQL.
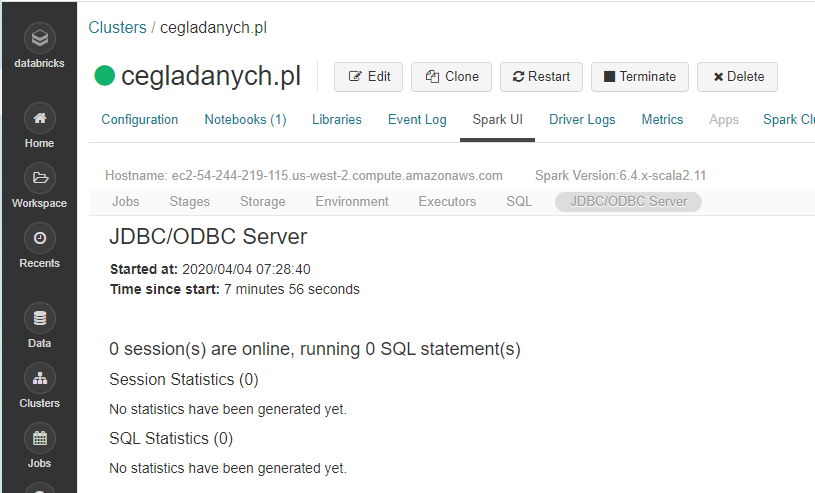
JDBC/ODBC Server
Tutaj znajdziesz wszystkie dane dotyczące aktualnych połączeń JDBC. Na poniższym obrazku widać że nie mam żadnych połączeń.