Wybór odpowiedniego typu compute w Databricks to jedna z kluczowych decyzji wpływających na koszt, wydajność i wygodę pracy. Nic tak nie frustruje jak gapienie się na monitor w oczekiwaniu wyników. ☹️
W tym wydaniu rozkładamy na czynniki pierwsze wszystkie opcje klastrów w Azure Databricks — od Serverless, SQL Warehouse Classic i Pro po Standard Job Compute.
Serverless Compute — przyszłość jest teraz
Serverless compute to flagowa rekomendacja Databricks dla większości workloadów. Co warto wiedzieć:
Zero zarządzania infrastrukturą — zasoby są provisionowane i zarządzane przez Databricks w serverless compute plane. Infrastrukturą zarządza Databricks więc cześć problemów jest po ich stronie.
Błyskawiczny start — eliminacja czekania na rozgrzewanie klastrów, to akurat bardzo lubię bo czekać kilka minut na start jest czasami wkurzające.
Automatyczne skalowanie — zasoby dopasowują się do obciążenia więc nie musisz planować jaki klaster wybrać i ile RAMu będzie potrzebne.
Versionless — zawsze najnowszy runtime, automatyczne upgrady i patche.
Wspierane workloady: notebooki, jobs/workflows, Lakeflow Spark Declarative Pipelines. Ogólnie wszystko czego potrzebujesz na codzień. Możliwość wyboru środowiska ilość RAM i dodania zależnych bibliotek.
Wymagania:
Unity Catalog musi być włączony
Workspace w wspieranym regionie Azure
Brak włączonego PCI-DSS w profilu compliance
Ograniczenia:
Źródła danych tylko przez Lakehouse FederationBrak pełnej kontroli nad konfiguracją klastra
Koszty
To co ważne to monitorowanie kosztów, bo można sobie przepalić trochę kasy. Szczególnie uczulam na osobiste konta bo u klienta jeśli jest blokada to powinna być ustawiona żeby zabezpieczyć skarbiec firmy.Informacje o tym ile przepaliłeś/łaś $$$ oprócz portalu znajdziesz w tabeli system.billing.usage tam są szczegóły ile i na co.
Classic Compute — pełna kontrola w Twoich rękach
Classic compute to zasoby deployowane bezpośrednio w koncie chmurowym klienta. Czyli runtime który wybrałeś jest w VM na twoim koncie. Tutaj płacisz Databricks za moc obliczeniową i Azure na VMkę. Dwa tryby dostępu:
Standard Access Mode (rekomendowany)
- Wielu użytkowników może współdzielić jedno compute
- Iizolacja kodu przez Lakeguard — pełne bezpieczeństwo
- Wsparcie: Python ✅ | SQL ✅ | Scala ✅ | R ❌
Dedicated Access Mode
- Compute przypisany do jednego użytkownika/grupy
- Wymagany dla: RDD API, rozproszony ML, GPU, język R
Kto może tworzyć?
Admini — bez ograniczeń
Użytkownicy z entitlementem „Unrestricted cluster creation”
Pozostali — tylko przez przypisane compute policies
SQL Warehouse — potęga dla analityków
SQL Warehouse to compute zoptymalizowany pod zapytania SQL, dashboardy i integracje z narzędziami typu BI.
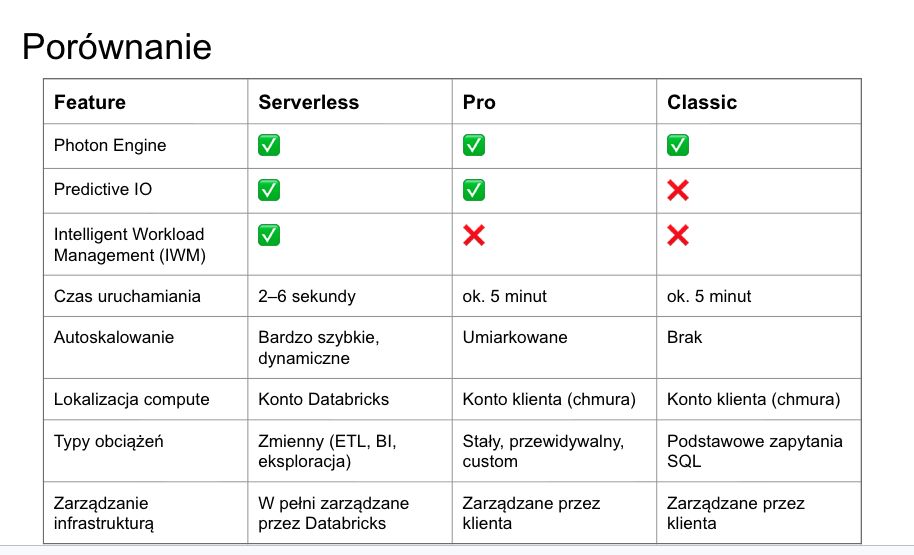 |
Kluczowe cechy:
Auto-restart — zatrzymany warehouse startuje automatycznie przy zapytaniu
Integracje: Power BI, Tableau, JDBC/ODBC, Python SQL Connector, DataGrip, DBeaver
Starter Warehouse — tworzony automatycznie w nowym workspaceMożna podłączyć notebook do Pro lub Serverless SQL Warehouse
Wspiera tylko SQL
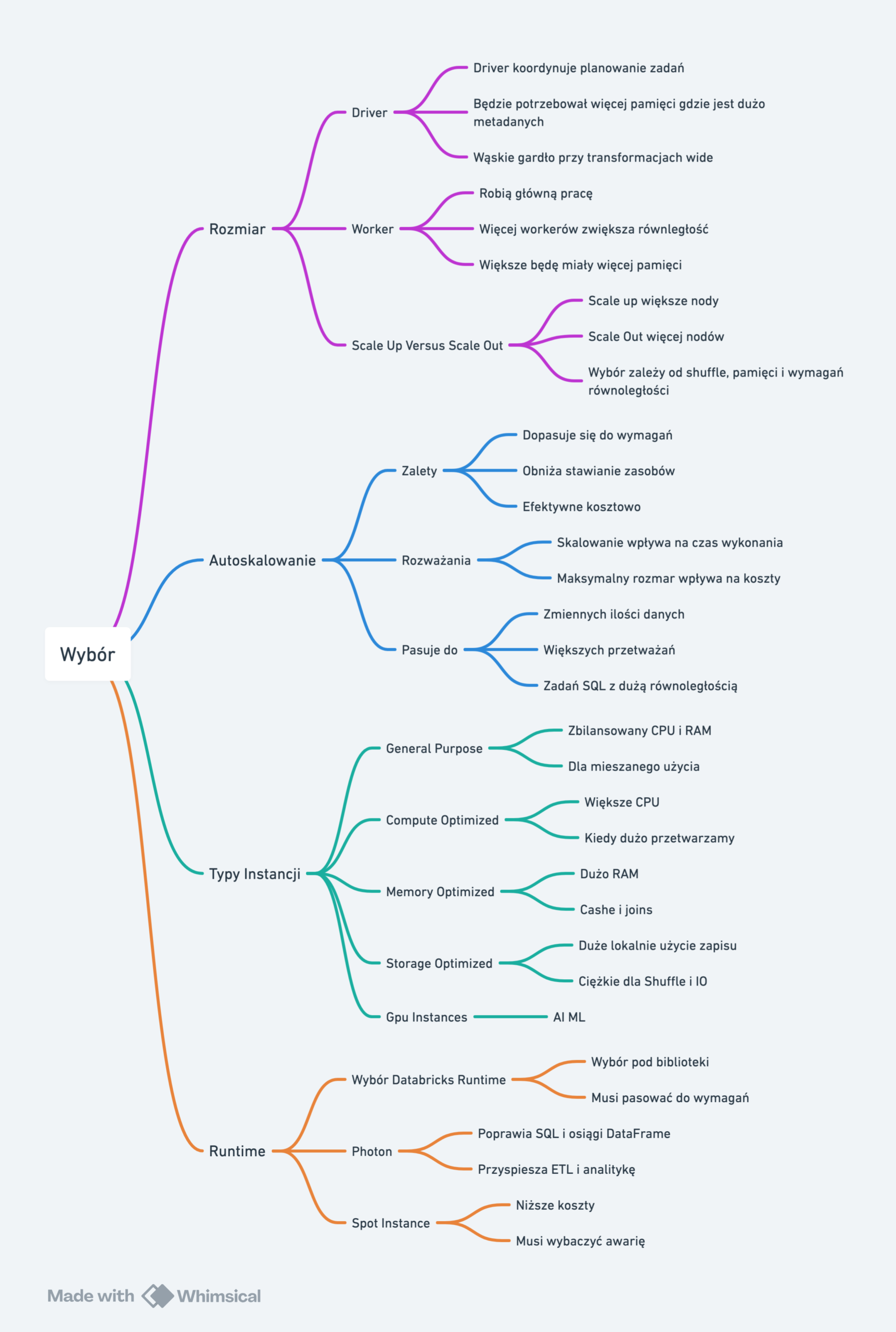
Drzewko decyzyjne – różne typy compute
Polecam poczytać informację o tym jaki typ CPU i VM wybierasz to bardzo ważne.Sizes for virtual machines in Azure
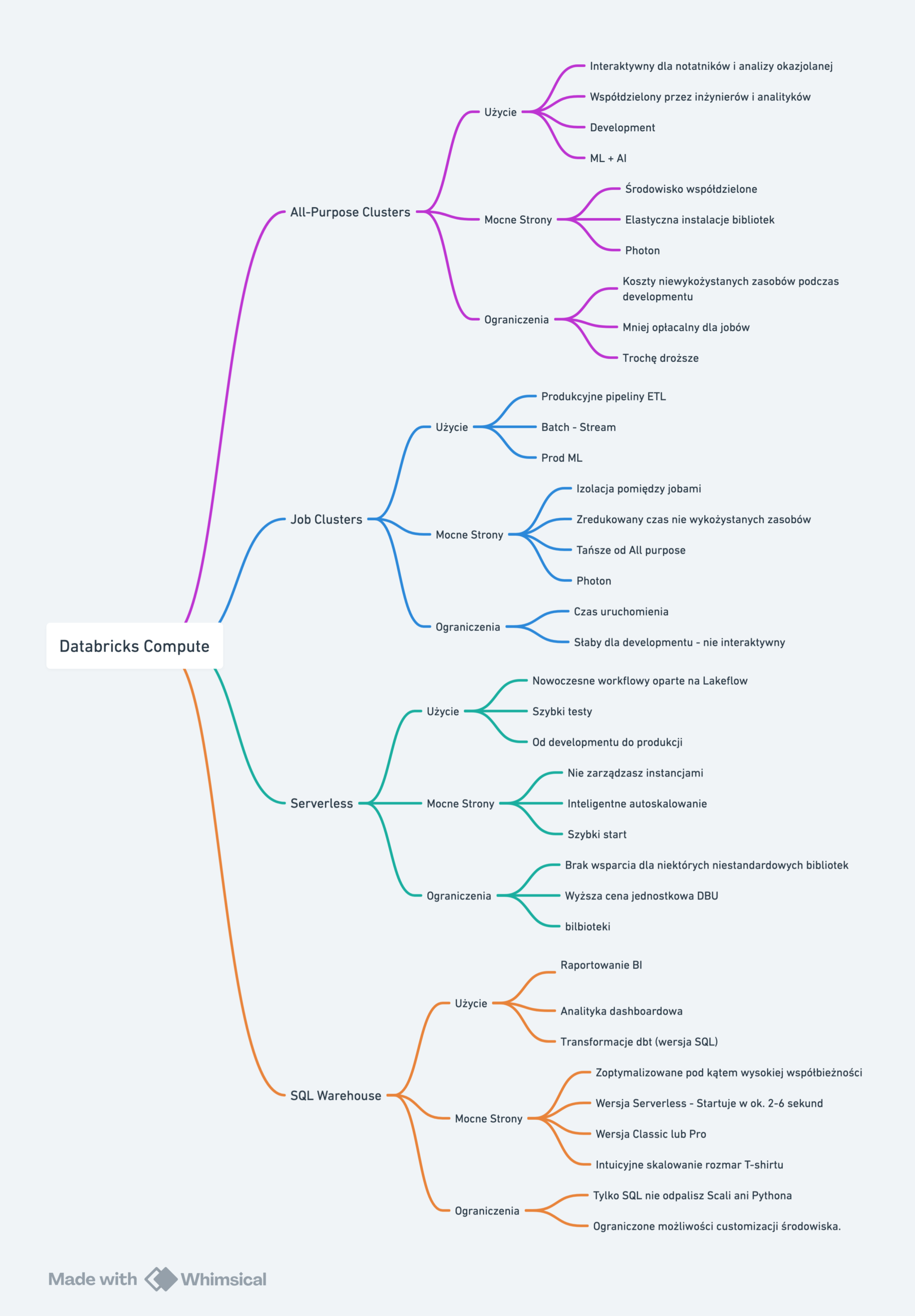
Jak wybrać? Tabela decyzyjna
Polecam nagranie na Akademia Big Data (Link poniżej⬇️) tam omawiam szczegóły jak podejść do wyboru jaki typ compute wybrać i kiedy.
| Twój scenariusz | Rekomendowany compute |
|---|---|
| Interaktywne notebooki (Python/SQL) | Serverless compute |
| SQL analytics i dashboardy | Serverless SQL Warehouse |
| Automatyczne joby i pipelinesProdukcja | Serverless computeJob Compute |
| Potrzebujesz RDD API, GPU lub R | Classic Dedicated compute |
| SQL | Pro SQL Warehouse |
| Współdzielony klaster dla zespołu | Classic Standard compute |
Ogólna zasada: zacznij od Serverless. Sięgaj po Classic tylko gdy potrzebujesz funkcji niedostępnych w serverless.
⚠️ UWAGA ⚠️
Kod który działa na zwykłym klastrze może nie zadziałać na Serverless, to dotyczy SQL i innych języków. Jest to spowodowane różnicą w wersjach bibliotek i innymi ustawieniami.
Osobiście skupił bym się na przemyśleniu czego potrzebuje.
Serverless jest najprostszym wyborem klikasz i nic nie musisz robić, wszystko się dzieje samo optymalnie. Sam przyznasz, że jako obietnica to trochę brzmi zbyt pięknie żeby było prawdziwie.
Trochę tak jest tyle że to kosztuje i może warto poświęcić trochę czasu i chociaż zrobić porównanie kosztów i czasu wykonania. Najlepsza decyzja to ta podjęta na podstawie danych, a nie opini.
Drzewko decyzyjne – wybór klastra