
| OPTYMALIZACJA Jak wiesz optymalizacja jest ważnym elementem pracy z Big Data. Poniżej kilka tipów od czego zacząć.1. Skalowanie partycji: Domyślna wartość spark.sql.shuffle.partitions (200) nie jest optymalna dla przetwarzania dużych ilości danych (> 20GB). Rekomendacje dotyczące partycji do wymieszania (shuffle): Rozmiar partycji do wymieszania powinien wynosić między 100MB a 200MB.Zmniejsz ilość partycji używając filtr na kolumnie wykorzystanej do partycji Hive – pamiętaj partycja Hive to nie to samo co partycja Spark.Liczba partycji do shuffle powinna być równa rozmiarowi danych wejściowych etapu lub docelowemu rozmiarowi partycji. Jeśli liczba partycji jest mniejsza niż liczba dostępnych rdzeni, ustaw liczbę partycji na równą liczbie rdzeni. Rozważ dostosowanie wartości spark.sql.files.maxPartitionBytes jeśli chcesz zwiększyć równoległość: W przypadku gdy dane wejściowe zawierają zagnieżdżone pola lub powtarzające się dane. Generujesz dane za pomocą nie wektorowych UDF-ów. Uważaj na repartition szczególnie w pewnych etapach. Sprawdź czy możesz użyć Coalesce. 2. Joins:Najszybszy BroadcastJoin pamiętaj zajmie dużo pamięci musisz mieć na to miejsce. Skew Joins – możesz dać hint do Sparka i powiadomić go że Dataframe jest krzywa (skewed) i podać klucze, które pomogą w optymalizacji.Uważaj przy groupBy kiedy dane są nierównomiernie rozłożone Możesz dodać randomowe dane żeby pomóc w prawidłowej dystrybucji. Najgorszy BroadcastedNestedLoopJoin – unikaj go jak ognia3. Porady dotyczące kodowania Unikaj zbędnego ponownego partycjonowania przed operacją groupByKey.Pamiętaj o odpowiednim buforowaniu (persisting) DataFrame’ów i wywołuj unpersist() po zakończeniu buforowania. Pamiętaj persist jest kosztowny.Do zapisu danych użyj wszystkich rdzeni, a nadmierną ilość plików skompresuj wykorzystując Databricks Delta Z-OrderingUważaj na Count() nie rób tego za często i nie nadużywaj na produkcji. Jest podobna alternatywa approcDistinctCount()DropDuplicates użyj przed groupBy or joinUżywaj wektoryzowanych funkcji spark.sql.functions, lub PandasUDFs. 4. Radzenie sobie z nieregularnościami (Skew): Filtruj niepotrzebne dane tak wcześnie, jak to możliwe. Wykorzystaj losowe rozczłonkowanie (random shuffling), aby równomiernie rozłożyć dane w partycjach do agregacji i połączeń. repartition() lub repartitionByRange() Rozważ podzielenie zapytań z nieregularnościami na dwie części, a następnie połączenie wyników dla bardziej zoptymalizowanych strategii połączeń typu broadcast. 5. Konfiguracja klastra: Nie ma jednej uniwersalnej konfiguracji. Wymaga to procesu iteracyjnego uwzględniającego czynniki takie jak rodzaj maszyn, organizację danych, ilość danych i konkretne zadanie. Rekomendacje obejmują ustawienie 4-8 rdzeni na executor oraz alokację pamięci w oparciu o dostępną pamięć węzła i liczbę wykonawców na węźle. Zrozumienie sprzętu i uwzględnienie ilości dostępnej pamięci, dysków, przepustowości sieci.Wykorzystaj Delta.io cache Apache Spark Core—Deep Dive—Proper Optimization Daniel Tomes Databricks |
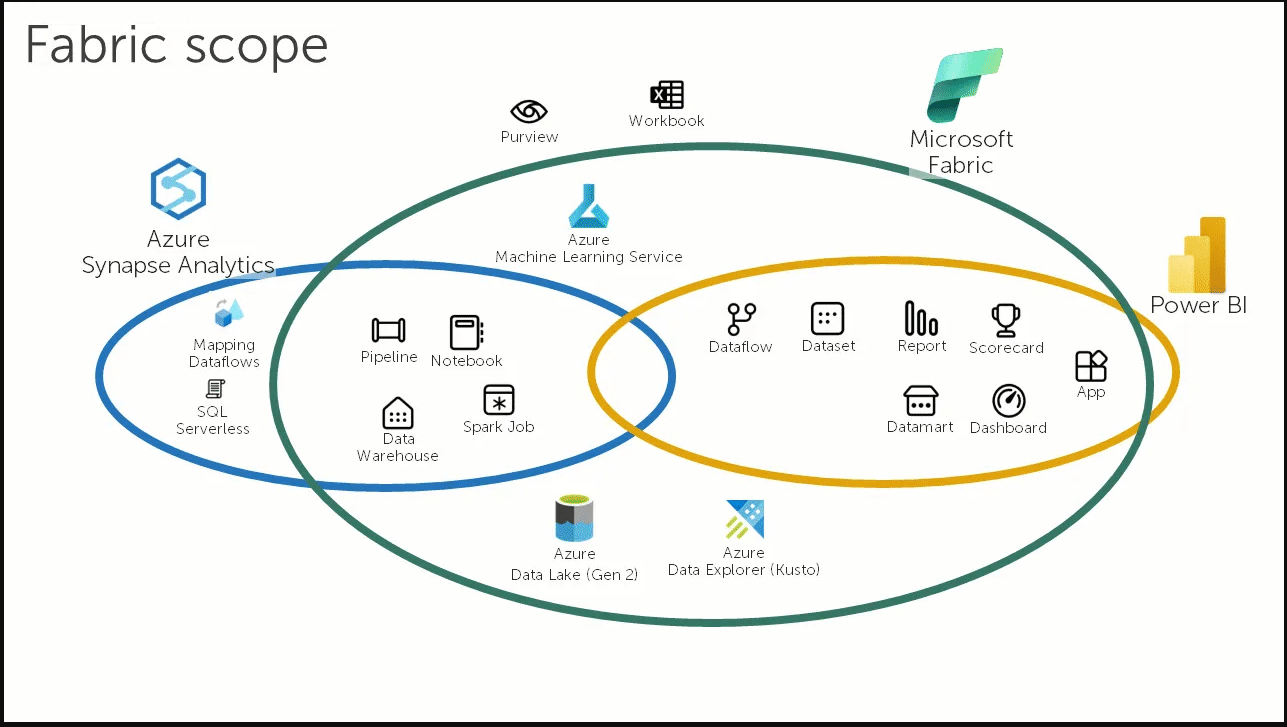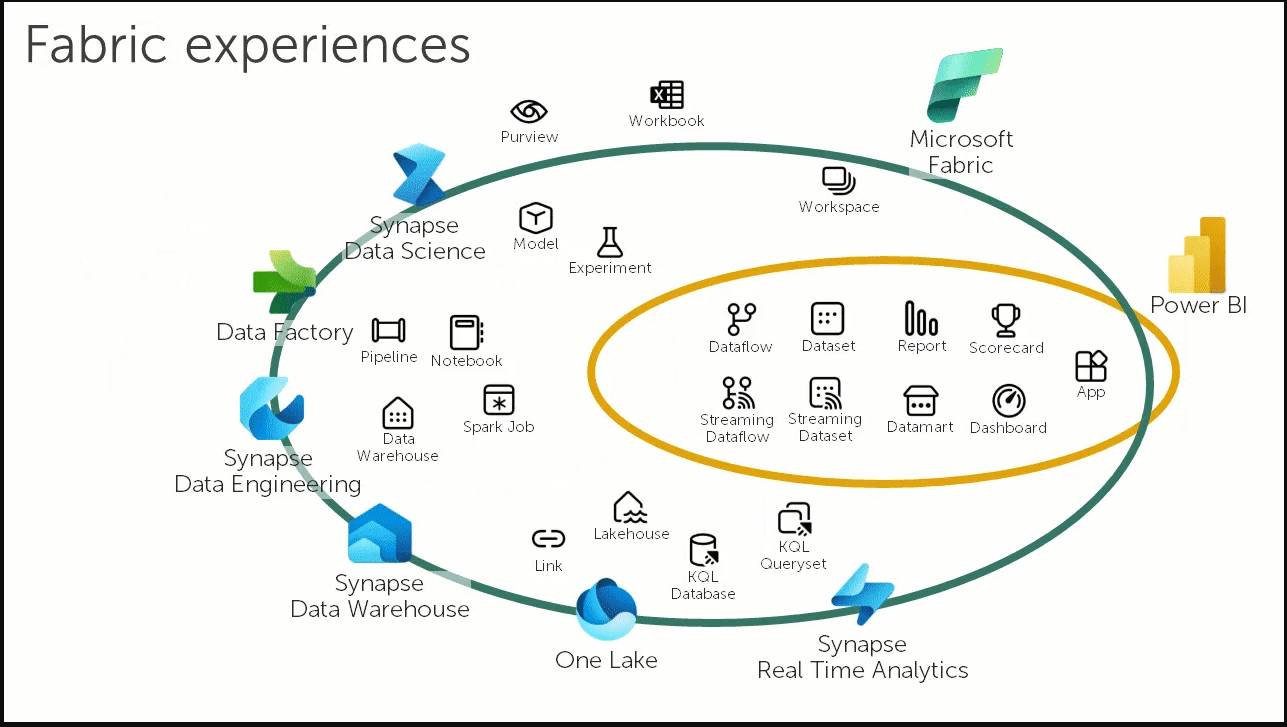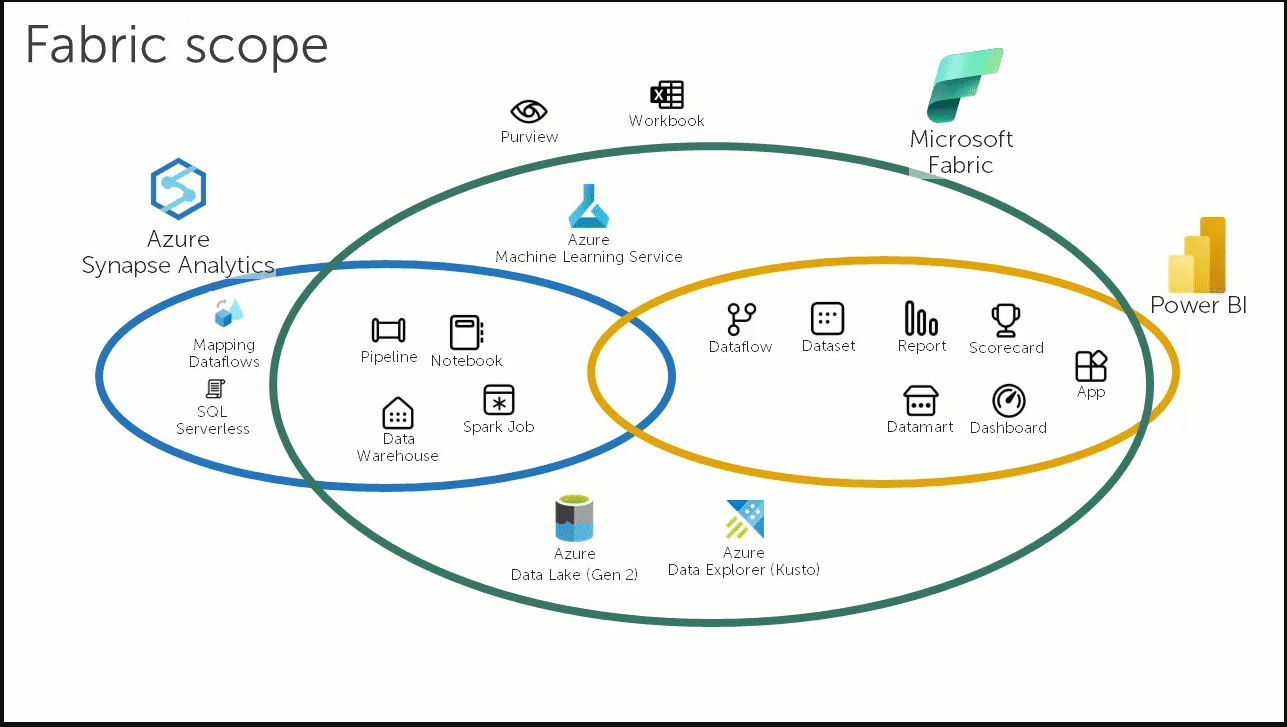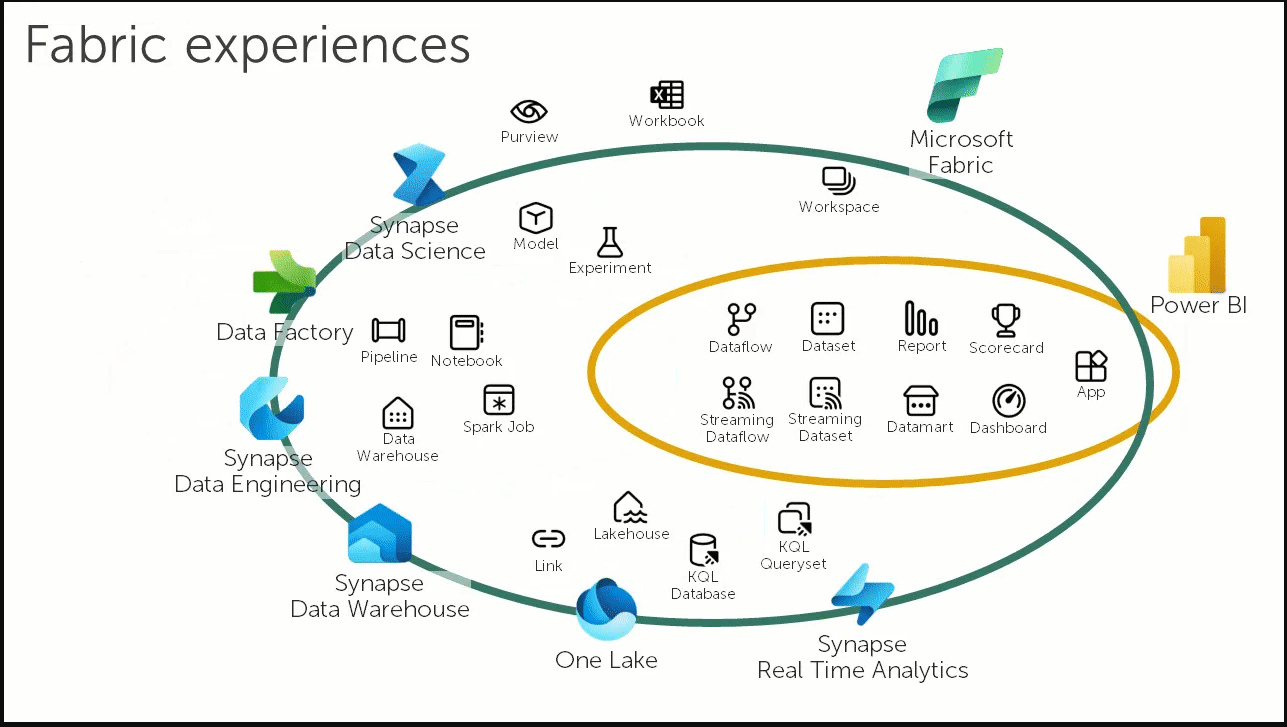 |
MICROSOFT FABRIC No i stało się MS wziął się za dane i stworzył coś nowego. Powstał nowy portal dedykowany dla Fabric, jest to zestaw narzędzi do ładowania, transformacji i analizowania danych. W nowym portalu znajdziesz wiele znanych Ci narzędzi Azure: Data Factory, Notatniki, Synapse Data Science, Synapse Warehouse. Microsoft zcentralizował wszystkie komponenty potrzebne do stworzenia hurtowni danych w jednym miejscu. Jest to usługa typu SAAS więc mniej zarządzania. Koncepcyjnie jest to jedna usługa, ale pod spodem zintegrowali ADF i Synapse dla większej wygody i standaryzacji pracy.Co zawieraData Factory czyli nowy integrator danych. Zobaczymy czy będzie miał te same bajery.Synapse Data Engineering: Lakehouse, Notatniki, Spark JobsSynapse Data Warehouse: Nowe wydanie Synapse SQL Dedicated PoolsSynapse Data Science: Synapse ML i Azure Machine Learning Synapse Real Time Analytics: Nowe Eventstreams podobne do Azure Stream Analytics Power BI: W pełni zintegrowany z FabricData Activator: Event driven narzędzie do przetwarzanie strumieni danych zintegrowany z Power BI i Event HubsWadyBrak SQL Serverless – nie odczytasz danych z data lake przy użyciu SQL, do tego są tylko notatniki i SparkBrak Mapping Data Flows – nie zostały przeniesione do Fabric, Brak Spark .Net – chyba uznali że nie jest to takie ważne i w Fabric go nie będzie.Zalety Standaryzacja formatu danych, wszystkie dane są w formacie delta. Możliwość łatwego podpięcia się z Power BIDedykowany portal z dostępem do wszystkich narzędzi. Personas: w zależności od tego co robisz bądź jaki masz cel, portal daje ci możliwość personalizacji. W UI zobaczysz narzędzie pod Data Science lub pod Inżynierię Danych. OneLake: Czyli centralne repozytorium danych, idea wzięta z OneDrive, wszystkie dane w jednym formacie w jednym miejscu. Dzięki temu łatwiej nimi zarządzać i mieć dostęp z poziomu różnych aplikacji.Wygląda to jak konkurencja dla Databricks, jeden duży kombajn do wszystkich zadań. Wygląda ciekawie w praktyce wyjdzie czy rzeczywiście będzie to sukces. Advancing Fabric – A Quick Microsoft Fabric Tour A 10 minute Tour Around Microsoft FabricIntro to Microsoft FabricAzure Synapse Analytics versus Microsoft FabricWhat is OneLake? |