
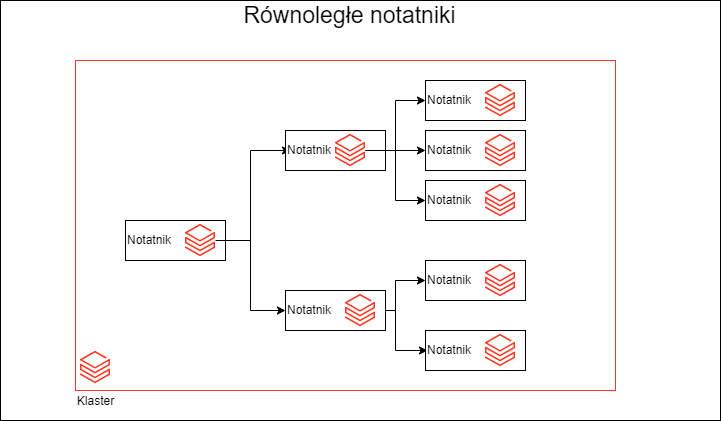
Jak wiesz Spark jest stworzony do przetwarzania równoległego. Nie o tym jednak chcę dzisiaj napisać, ale o równoległym wykonaniu notatników Databricks. Stanąłem oko w oko przed problemem orkiestracji wielu kolekcji danych. I pojawił się problem ich ilości, w tradycyjnym podejściu musiałbym uruchomić kilkadziesiąt notatników jeden po drugim. Co nie jest zbyt efektywne.
Mam kilkanaście kolekcji do przeładownia, a każda z kolekcji ma po kilka do kilkunastu elementów. Wiec nie chciałem tego przetwarzać szeregowo, bo klaster będzie się męczył, a ja muszę na to patrzeć i czekać, a tego nie lubię.
Wątki
Wyobraź sobie, że musisz przetwarzać dane dla kilkunastu miast w Polsce. Ważne jest, aby traktować każde miasto jako całość. Będziesz przetwarzać całą listę kolekcji mającą powiązania hierarchicznie (rodzic, dziecko). Chciałbyś to robić jak najszybciej i nie przetwarzać jednego miasta po drugim, lecz wszystkie naraz. Jeśli jest problem z przetwarzaniem w jednym z zadań na poziomie dzielnic, to cała kolekcja powinna zostać wstrzymana. Pojawia się pytanie jak uruchomić notatniki równolegle, czy jest mechanizm, który to ogarnie. Na szczęście jest 🙂 tutaj podpowiedź w dokumentacji. Trzeba użyć wielu wątków, czyli Threads lub Futures. Jest to dostępne w obu najważniejszych językach Python i Scala.
Całość przykładowego rozwiązania to dwa notatniki i pliki konfiguracyjne. do pobrania na GitHub.
Planowanie zadań
Na poziomie Sparka zadania mogą zostać zgrupowane („pools”) i każda grupa może dostać inną porcję zasobów. Tzn. że dla poszczególnej grupy możesz przypisać więcej zasobów. Ta metoda pozwala potraktować różne grupy z odmiennym priorytetem. W obrębie grupy zadania będą miały dostęp to tych samych zasobów i będą potraktowane jako równe.
Sprawdź ustawienia Sparka czy Fair Scheduler Pool jest ustawiony: spark.conf.get("spark.scheduler.mode") powinieneś otrzymać wartość 'FAIR’ jeśli nie to ją ustaw spark.conf.set("spark.scheduler.mode", "FAIR")
Nowe zadania są przekazywane do domyślnej puli. Pule zadań można ustawić, dodając „spark.scheduler.pool” do SparkContext w wątku, który je przesyła.
sc.setLocalProperty("spark.scheduler.pool", "pool1")
Ważne
Notatniki wykonane w ten sposób będą dzieliły zasoby klastra. W razie braku zasobów lub błędów w jednym notatniku może dojść do awarii wszystkich. Pamiętaj o tym. Ważne jest, abyś pamiętaj o kontekście, w jakim stosujesz rozwiązanie. To rozwiązanie może być efektywne w pewnych sytuacjach, ale nie w każdej. Jeśli okaże się, że rozwiązanie jest niestabilne można część np Miasta wykonać w ADF lub użyć Jobs API, a dzielnice wykonać równolegle w notatnikach.
Przykładowy plik konfiguracyjny
{
"wersja": "1.0.0",
"miasto": "Kraków",
"dzielnice": [
{
"wejscie": "/mnt/miasta/krakow/Kazimierz",
"wyjscie": "/mnt/miasta/przetworzone/krakow/Kazimierz",
"dzielnica" : "Kazimierz"
},
{
"wejscie": "/mnt/miasta/krakow/Łagiewniki",
"wyjscie": "/mnt/miasta/przetworzone/krakow/Łagiewniki",
"dzielnica" : "Łagiewniki"
},
{
"wejscie": "/mnt/miasta/krakow/Dębniki",
"wyjscie": "/mnt/miasta/przetworzone/krakow/Dębniki",
"dzielnica" : "Dębniki"
}
]
}
Notatniki Databricks
Oto najważniejsza część kodu odpowiedzialnego za wywołanie notatników. Tutaj użyje dbutils.notebook.run(). Każde wykonanie notatnika to osobne zadanie (Jobs). Poniżej kod w scali odpowiedzialny za wykonanie zadań i mechanizm wielowątkowy.
//Uruchomi notatkini równolegle
import java.util.concurrent.Executors
import scala.concurrent.{Await, ExecutionContext, Future}
import scala.concurrent.duration.Duration
val pliki = dbutils.fs.ls("/Tmp/DataStore/dane")
val listsPlikow = pliki.map(_.path.replace("dbfs:","/dbfs"))
val argumenty = listsPlikow.map(x => Map("plikKonfiguracyjny" -> x))
val kontekst = dbutils.notebook.getContext()
val liczbaZadan = argumenty.size
implicit val executionContext = ExecutionContext.fromExecutorService(Executors.newFixedThreadPool(liczbaZadan))
try {
val futures = argumenty.zipWithIndex.map {case (args, i) =>
Future({
dbutils.notebook.setContext(kontekst)
sc.setLocalProperty("spark.scheduler.pool",s"pool${i % liczbaZadan}")
println(args)
dbutils.notebook.run("Zadania",timeoutSeconds = 0, args)
})}
Await.result(Future.sequence(futures),atMost = Duration.Inf)
} catch {
case e: Exception => {
}
} finally {
executionContext.shutdownNow()
}
Python
Poniżej kod w Pythonie, zasada działania jest podobna jak w scali.
%python
from concurrent.futures import ThreadPoolExecutor, ProcessPoolExecutor
sciezka = "/Tmp/DataStore/dane"
notatnik = "/Zadania/"
def wykonajNotatnik(liczbaZadan, plik):
dbutils.notebook.run(path = notatnik,
timeout_seconds = 300,
arguments = {"plikKonfiguracyjny": plik})
pliki = dbutils.fs.ls(sciezka)
# liczbaZadan = pliki
nazwaPliku = [(p.path).replace("dbfs:","/dbfs") for p in pliki ]
with ThreadPoolExecutor() as executor:
results = executor.map(wykonajNotatnik, nazwaPliku, nazwaPliku)
Drugi notatnik to przykład odczytu konfiguracji i pobrania parametrów.
dbutils.widgets.text("plikKonfiguracyjny","")
val plikKonfiguracyjny = dbutils.widgets.get("plikKonfiguracyjny")
import scala.io.Source
import org.json4s._
import org.json4s.jackson.JsonMethods._
val konfiguracja = Source.fromFile(plikKonfiguracyjny).mkString
val parametry = parse(konfiguracja)
val dzieliceKonfiguracja = for {JArray(dzielnice) <- parametry} yield dzielnice.size
val liczbaDzielic = dzieliceKonfiguracja(0)
val wersja = (parametry \\ "wersja").values.asInstanceOf[String]
val nazwa = (parametry \\ "miasto").values.asInstanceOf[String]
//Tutaj możesz wykorzystać ten sam mechanizm i przetwarzać dane równolegle zgodnie z tym co jest w konfiguracji lub sekwencyjnie
val rng = (1 to liczbaDzielic)
rng.zipWithIndex.map {
case (klucz,index) =>
val dzielice = (parametry \\ "dzielnice")(index).values.asInstanceOf[Map[String,String]]
val wejscie = dzielice("wejscie")
val wyjscie = dzielice("wyjscie")
val dzielnica = dzielice("dzielnica")
println(s"${wejscie},${wyjscie},${dzielnica}")
}
Daj znać czy używałeś czegoś podobnego i gdzie pojawiły się problemy ?
Szkoda ze nie wszystkie skrypty w python 🙁
Jest może jakiś konwenter scala to python ?
Zauważyłem ze odpalając cos w ThreadPoolExecutor() on nie zrzuca błędów nawet skladni
Cześć Karol
Też chciałbym mieć taki konwerter, jak masz czas to może coś stworzysz 🙂
Jak miałem notatnik to musiałem wszystko ręcznie przepisywać.
a jak obsłużyć błędy w ThreadPoolExecutor ?
Cześć Krzysztof. Pisząc notatniki z użyciem składni delta live tables można utworzyć joba w którym notatniki to poszczególne taski uruchamiane równolegle 🙂
Masz rację workflowy w Databricks są coraz mocniejsze i można robić bardzo ciekawą orkiestrację. To jest temat na osobny artykuł. Masz z tym jakieś problemy czy wszystko działa na medal?