

Nadeszły nowe czasy i pojawił się nowy predator Data Lakehouse. Hurtownie danych są bardzo dojrzałym rozwiązaniem, jakie jest stosowane w wielu organizacjach na całym świecie. Przez wiele lat świat BI żył w bazach relacyjnych. Wszystkie dane z całej organizacji były łączone i wymodelowane tak, aby zarządzający mogli szybko znaleźć odpowiedź na podstawowe pytania.
- Jaka była sprzedaż za ostatni kwartał?
- Ile wynoszą długi firmy?
- Ile jest materiałów na magazynie?
Na podstawie danych w bazach relacyjnych managerowi mogą podejmować decyzje i zarządzać firmą. Dane są zbierane i integrowane z różnych systemów organizacji i połączone w taki sposób, aby ułatwić proces ich analizy. Dzięki narzędziom do wizualizacji danych takim jak Power BI łatwo znaleźć odpowiedź na podstawowe pytania. Aż tu nagle zaczęto zauważać problem; danych zaczęło przybywać w takim tempie, który był trudny do ogarnięcia.
Problem ilości
Coraz większa liczba systemów generuje olbrzymie ilości danych w przeróżnych formatach. Historycznie hurtownie były świetnym rozwiązaniem dla wielu firm. Nagłych wzrost niestrukturyzowanych danych z ich dużą różnorodnością i dużą ilością sprawił, że firmy borykają się z przetworzeniem danych na wartościowe informacje. Zadawanie pytań staje się coraz bardziej kosztowne . Dla wielu zespołów deweloperskich wydłuża się czas wprowadzania i integrowania nowych danych. Hurtownie danych przestały pasować do tego modelu i stały się powoli przeżytkiem i w pewnych sytuacjach są nieefektywne a tym samym nieopłacalne.
Na szczęście na każdy problem znajdzie się rozwiązanie. Powstały więc Data Lakes a znich Data Lakehouse.
Co to jest Data Warehouse ?
Pomijając różne technologie używane w hurtowniach danych, jest to wzorzec architektoniczny. Jest to rozwiązanie polegające na zebraniu danych z organizacji i połączeniu ich w jednych miejscu. Trzeba zintegrować dane z odrębnych systemów i połączyć je w logiczną całość. Ta logiczna całość to model danych, jest to on tak stworzony, żeby odzwierciedlał reguły firmy i jej strukturę działania. Tak uporządkowane dane w jednych centralnym punkcie są gotowe do wizualizacji a tym samym analizy.
Hurtownie danych możemy implementować używając różnych technologii. Sam pracowałem na hurtowniach danych opartych na SQL Server. Oczywiście są inne technologie, które oferują podobna funkcjonalność. Pomimo, że jest to bardzo dojrzała i zaawansowana architektura ma ona swoje mankamenty.
Problemy hurtowni danych
- Jednym z problemów, który przychodzi mi do głowy, jest ograniczony zasób RAM i CPU, jeśli nie jesteśmy w chmurze. Pracując on premise dochodzi do momentu, gdzie wszystko zaczyna mulić i zespół nie ma co optymalizować, bo jest tak dużo danych i model jest na tyle skomplikowany, że optymalizacja nie daje dużych rezultatów. Takie hurtowanie Danych stają się wielkimi monolitycznymi rozwiązaniami. Są problematyczne w utrzymaniu i nie spełniają wielu wymagań dzisiejszego biznesu.
- Drugim problemem jest model danych. Żeby hurtownia odpowiednio wspierała firmę, trzeba dane wymodelować i połączyć w skomplikowane zależności. Dzięki temu odpowiedzi na pytania organizacji będą spójne z jej zasadami. Niestety jest to mozolny i skomplikowany proces i do tego kosztowny. Tak stworzony model jest dość 'sztywny’ tzn. sprawdza się dobrze w danych scenariuszu. Utrudnia on zaawansowaną analizę przez to, że dane są silnie powiązane w specyficzny sposób.
Co to jest Data Lakehouse?
W pierwszej fazie cirka 10 lat temu, kiedy chmura publiczna stała się nowością, pojawił się nowy zwrot Data Lake. Jest to nic innego jak miejsce, gdzie business trzyma dane różnego typu. Tworząc takie rozwiązanie ładujemy dane ustrukturyzowanie i te, które nie mają żadnej struktury do jednego 'jeziora’. Data Lake jest to repozytorium nieprzetworzonych danych bez utrzymania schemy czy struktury. Nie ma tutaj sztywnych relacji jak w hurtowni danych.
Zalety Date Lake
- Elastyczność, analitycy mają możliwość tworzenia zapytań i analizy bezpośrednie na surowych danych
- Centralizacja, wszystkie dane są w jednym miejscu
- Tanie rozwiązanie, nie wymaga skomplikowanych procesów ETL, dodatkowo możemy użyć technologiii open source
- Łatwość analizy przez to, że dane nie są modelowane analitycy mają możliwość większej swobody w tworzeniu zapytań czy aplikowania nauczania maszynowego.
Te nieustrukturyzowane repozytoria danych mają swoje mankamenty. Jednym z nich jest brak wsparcia dla transakcji. Utrudniają utrzymanie dobrej jakości danych. Jest znacznie trudniej łączyć dane różnego typu. Organizacje chciałyby również mieć możliwość przetwarzania danych na kilka sposobów tj przetwarzanie strumieniowe lub partiami. Pojawiła się potrzeba bardziej elastycznego wydajnego systemu. Ze względu na dużą różnorodność typów danych utrudnione jest też tworzenie systemów zarządzania. Jeśli chodzi o taką formę przetrzymywania danych to utrudnione mamy również system monitorowania.
Nowy termin
Żeby ulepszyć powyższe rozwiązanie z terminów Data Lake + Data Warehouse powstał nowy termin Lakehouse, który ma łączyć zalety obu rozwiązań. Nie jest to nowy termin, istnieje on już od jakiegoś czasu, chodź obecnie zyskuje na popularności. Ten rodzaj architektury jest już w użyciu takich firm jak Databricks, Snowflake czy Amazon.
Ideą Data Lakehouse jest połączenie zalet hurtowni danych oraz data lake. A więc mamy struktury danych i model zarządzania tak jak przy hurtowni. Lakehouse jest bardziej atrakcyjny dla analityków (Data Scientist), ponieważ daje więcej możliwości i elastyczności w analizie danych. Ta elastyczność ułatwi wykorzystanie nauczania maszynowego. Drugim plusem jest koszt, takie dane trzymane w luźnej formie kosztują znacznie mniej niż relacyjna baza danych.
Zalety Data Lakehouse
- Równoległe przetwarzanie danych przy użyciu technologii Big Data
- Wsparcie dla schematów danych i mechanizmów zarządzania
- Bezpośredni dostęp do wszystkich danych
- Izolacja danych od warstwy obliczeniowej
- Wsparcie dla wielu formatów danych: json, parquet, avro, csv, binary
- Wsparcie dla danych IoT
- Możliwość przetwarzania strumieniowego
- Migracja pomiędzy technologiami
- Luźne dane są łatwiejsze w zarządzaniu retencją
Databricks
Databricks opisuje swoje rozwiązanie jako ujednoliconą platformę analityczną. Z tego opisu można wywnioskować, że robi wszystko i da się zastąpić hurtownię danych lakehousem. Czy aby na pewno. Wszystko zależy od kontekstu i wymagań biznesowych. Databricks pomimo wielu zalet i nowinek technologicznych jest innym narzędziem i nie każda funkcjonalność da się zastąpić tak jak w SQL Server. Podstawowa różnica leży w narzędziach developerskich i metodach pracy. W Databricks musisz więcej pisać kodu co z jednej strony jest zaletą a z drugiej komplikuje rozwiązanie. SQL Server ma pełen pakiet narzędzi zarządzającym procesem ETL tj SSIS, który jest w pełni zintegrowany z narzędziami SQL Server. Databricks ma dużą przewagę w możliwościach przetwarzania dużych ilości danych, i dodatkowe opcje np. streaming.
Azure
Jeśli popatrzymy na to z innej perspektywy to moc, jaką daje nam chmura publiczna Azure, przewyższa możliwości zestawu narzędzi jakim jest SQL Server. Databricks jest warstwą obliczeniową, co sprawia, że w modelu Lakehouse dane są odizolowane od warstwy obliczeniowej. Przez to, że nasz silnik obliczeniowy jest zupełnie w innym miejscu, wielu użytkowników może równocześnie procesować te same dane. Taki model daje nam możliwość standaryzacji różnych formatów danych. Mamy możliwość lepszej kontroli dostępu do plików. Dla analityków jest dostęp do różnych narzędzi i języków; Python, Skala czy R.
Nie chcę tutaj porównywać Databricks i SQL Server, bo są to odmienne narzędzia. Trzeba pamiętać, że chmura daje nam niesamowite możliwości tworzenia bardzo wyrafinowanej architektury. Nie ograniczajmy się tylko do jednego rozwiązanie, ale sprawdźmy czy hybryda da lepsze rezultaty i zaspokoi więcej potrzeb biznesu.
Data lakehouse nie ma takiej samej funkcjonalności jak relacyjna baza danych. Brak pełnego audytu, jeśli chodzi o dostęp do danych, brak zarządzania dostępem na poziomie rzędów danych czy dynamiczne maskowanie danych. Oraz wiele innych funkcji wymaganych przez organizacje. Jest to kolejny dowód na to, że są to odmienne narzędzia i architektury. Nie starajmy się ich porównać, lecz sprawdźmy, czy jedno uzupełnia drugie. Databricks to narzędzie Big Data z całą masą bibliotek i funkcjonalności, jakiej nie ma w SQL Server. Wszystko zależy od wymagań organizacji, będą oczywiście scenariusze, kiedy wystarczy nam jedno narzędzie, a w innej sytuacji trzeba postawić lakehouse i hurtownie danych. Uważam, że dzięki odmienności tych narzędzi będą się one uzupełniać.
Modern Data Warehouse
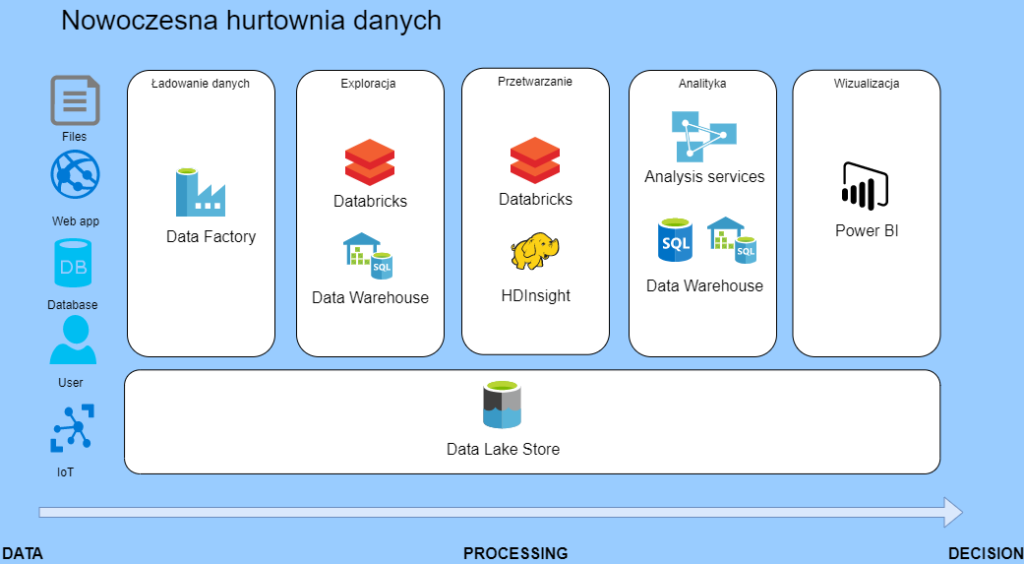
Azure Synapse
Oto kolejne narzędzie, które jak twierdzi Microsoft, jest pełną platformą, ma nam zapewnić zalety obu rozwiązań. Te dwa światy to hurtownia danych w połączeniu z technologią big data (Spark) oraz silnik T-SQL. Są tutaj możliwości integracji, a właściwie orkiestracji danych bez użycia kodu. to sprawia, że Synapse może stać się kompletną platformą, która dostarczy pełnego rozwiązania. Jest to narzędzie konkurujące z Databricks, ale cały czas oferuje trochę inne doznania. Jestem przekonany, że wielu klientów będzie opierało swoje rozwiązania na obu narzędziach niż tylko na jednym. Obecnie jestem w projekcie, w którym używamy tylko Databricks, a hurtownia danych jest klientowi nie potrzebna, przynajmniej jak narazie. Polecam blog seequality.net gdzie jest dużo informacji o Azure Synapse.
Funkcje Azure Synapse
- Synapse Studio; integracja danych nie wymaga programowania
- Zintegrowane silniki Apache Spare i SQL
- Działa jako jezioro danych lub hurtowania danych
- Możliwość tworzenia zapytań bezpośrednio na danych nierelacyjnych
- Możliwość wyboru języka: T-SQL, Python, Scala, Spark SQL, and .Net
- Autoryzacja Power BI
- Autoryzacja dostępu na poziomie kolumny lub rzędu danych
- Łatwa integracja z usługami Azure Machine Learning, Azure Cognitive Services, i Power BI.
Czy Lakehouse zastąpi Hurtownie Danych ?
Przyszłość
Patrząc z perspektywy mojego doświadczenia, nie ma jednego narzędzia, które potrafi wszystko. Jestem za modelem hybrydowym, czyli coś, co mógłbym określić mianem Modern Data Warehouse. Jest to połączenie kilku narzędzi, które nawzajem się uzupełnią. Jeśli tworzysz architekturę to, pamiętaj że jest wiele możliwości i na dzień dzisiejszy połącz kilka technologii, żeby stworzyć kompletne rozwiązanie.
Rekomendacja?
Pisząc to, myślę o chmurze Azure i w tym kontekście nie chciałbym rekomendować, żadnego narzędzia. Sugerowałbym sprawdzić wymagania organizacji i na tej podstawie dobrać odpowiednią architekturę lakehouse lub/i hurtownię. Wszystko zależy od wymagań organizacji. Z jednej strony 'luźne’ dane łatwe do przetwarzania na wiele sposobów a z drugiej strony mamy pięknie wymodelowane dane a bazie relacyjnej. Każde rozwiązanie pasuje, ale w zależności na kogo patrzymy, konsumenta biznesowego czy analityka. Więc z tego by wynikało, że te dwa rozwiązanie są idealne, ale w zależności dla kogo? Jak wiele rzeczy w życiu zależy od kontekstu w jakim definiujemy problem.
Zaobserwowałem, że w pewnych okresach pewne narzędzia czy rozwiązania stają się modne. Czasami nie zastanawiamy się, czy model architektury faktycznie pasuje do wymagań. Możemy się złapać na tym że stosujemy coś tylko dlatego, że jest fajne i modne. Dbajmy o naszych klientów i oceniajmy technologie należycie.
Literatura
Dla zainteresowanych polecam dodatkową lekturę w postaci dwóch mięsistych artykółów.
Lakehouse: A New Generation of Open Platforms that Unify Data Warehousing and Advanced Analytics.
Delta Lake: High-Performance ACID Table Storage over Cloud Object Stores
Daj znać co myślisz na ten temat, czy masz podobne doświadczenia ?
W bricksach nie za fajnie pisze się w SQL a już w szczególności odpalając go jako spark.sql. ciężko później taki kod debugować. Masz może jakieś obejście tego problemu ?
Cześć Paweł
Zgadzam się z tobą, nie zbyt przyjemnie pracuje się z SQL w notatnikach szczególnie jeśli jest sporo kodu. Nie znam złotego środka. Starałbym się unikać dużych bloków, jeśli przekraczasz 100 linii kodu to pewnie jest go trochę za dużo i można by przemyśleć rozbicie na mniejsze kawałki. Taki pipeline można rozbić na kawałki i użyć innych języków. Jeśli nie musisz pracować na setach to może python lub scala pomoże. Jeśli chodzi o debugowanie to pewne elementy można wyłapać w Spark UI lub planie wykonania.
Miałeś może projekt przepisywania hurtowni na datalakehouse ?
Jak to robiłeś ?
Nie miałem takiej przyjemności jeszcze 🙂 Mogę się tylko domyślać czym się zmagasz. Właśnie jakie są największe bolączki?
Azure Synapse miażdży wydajnościowo databricksy nie rozumiem skąd taka fascynacja bricksami w ostatnim czasie ?
Cześć RafelG Dzięki za informację, muszę przyznać, że nie wiem jak wygląda porównanie osiągów Sparka; Synaps vs Databricks. Masz może jakiś link żeby przejrzeć case study ? Co do fascynacji to bardzo lubię Databricks i Sparka, świetnie mi się pracuje w ich środowisku. Databricksy są trochę bardziej popularne ponieważ są trochę dłużej na rynku i są bardziej generyczne, można ich użyć do szerszego spektrum problemów (i są dużo tańsze). Dla mnie to są dwa odrębne narzędzia i każdy jest dobry w swojej działce. W tej chwili u klienta powstaje cała platforma oparta na Databricks, tutaj Synapse nawet nie był rozważany… Dowiedz się więcej »
miałem na myśli azure sypnase klasycznego sql a nie sparka w synapsie(w kontekście dwh lakeHouse itp)
To samo w synapsie działa lepiej i taniej niż w bricksach.
Dziękuję za sprecyzowanie, masz rację wsparcie dla czystego SQL i relacyjnego modelu danych jest bezapelacyjnie lepsze w Synapse. Databricks został stworzony do czego innego, dlatego w tej konkurencji przegrywa z Synapse. Z tego, co obserwuję, to jest lekka tendencja odchodzenie od relacyjnego modelu. Do pewnego stopnia jest moda na AI/ML i Data Science i tutaj trzymanie danych w luźnej formie daje więcej elastyczności. Dlatego Databricks jako taki trochę „multitool” jest w stanie stworzyć alternatywę dla tradycyjnej hurtowni. Jeśli miałbym stawiać DW tylko pod raporty w PowerBI, to raczej bym nie wybrał Databricks, ale jeśli firma potrzebuje dodatkowo zaawansowanej analizy i… Dowiedz się więcej »