
Jakość danych w Databricks DQX
Jak sprawdzić jakość danych w Databricks i to zautomatyzować. Nie martw się jest nowe narzędzie od Databricks i bardzo Ci pomoże w kontroli jakości. Bardzo ważny temat wchodzący w skład testowania. Samo testowanie to bardziej skomplikowany aspekt inżynierii, ale jakość danych to kawałek łatwy to ugryzienia. Na szczęście nowe narzędzie od Databricks wydaje się być…
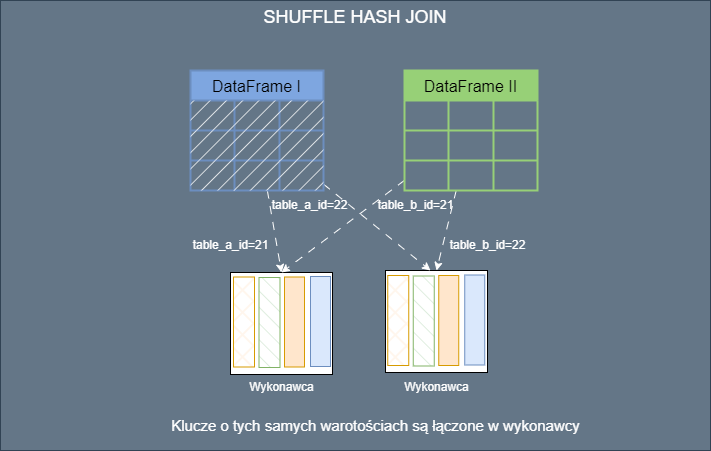
Jak Spark robi join?
Nie znam rozwiązania gdzie nie trzeba połączyć jakiś tabel. Możesz pracować przy różnych modelach architektonicznych takich jak Lakehouse czy Warehouse bądź innym cudzie technologii. W każdym przypadku pracując z Apache Spark będziesz łączył(ła) tabelę. Małe duże, rozproszone czy nie jakoś join trzeba zrobić. Najczęściej po prostu robisz join i nic innego Cię nie interesuje. Spark…

Lista narzędzi AI dla każdego inżyniera, które warto znać
Skoro ten świat pożerany jest przez AI, to warto mieć pod ręką trochę narzędzi. Każdego dnia przybywa ich coraz więcej, i chcę rzucać się na każde, ale obserwuje. Najbardziej użyteczne przejdą próbę czasu i obronią swoją wartość. Poniżej lista kilku narzędzi dzięki którym możesz być bardziej produktywny. GitHub Copilot Uzupełnianie i generowanie kodu: Wrzuci sugestie…
Continue Reading Lista narzędzi AI dla każdego inżyniera, które warto znać
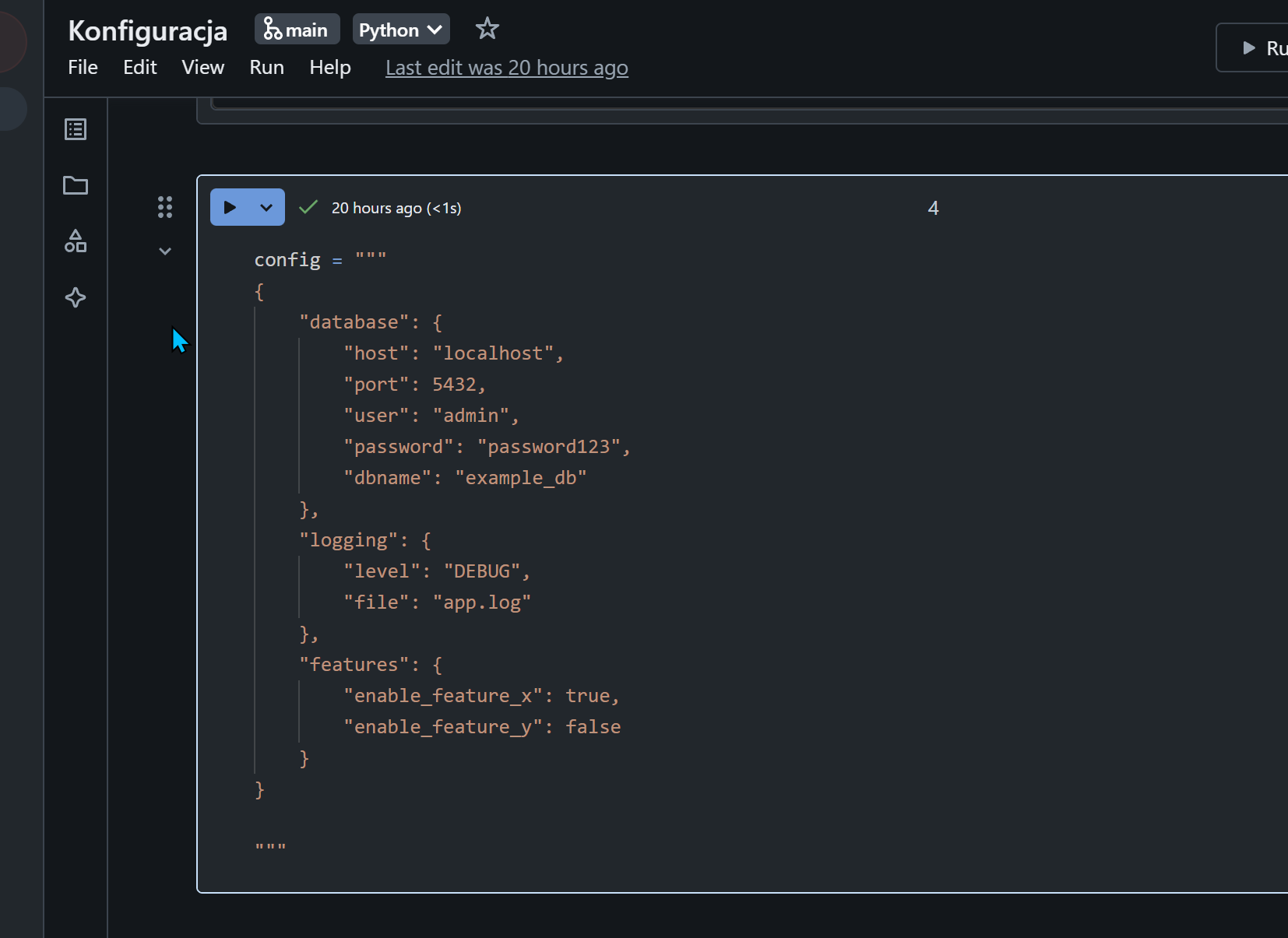
Kilka pomysłów na konfigurację Databricks
W wielu przypadkach ładowania danych w procesie ETL będziesz potrzebował/ła sparametryzować proces zasilania. Prawie każdy pipeline wymaga jakiś parametrów, np. nazwa tabeli, nazwa środowiska (dev, test, prod) ect.. Im bardziej skomplikowany pipeline tym więcej parametrów potrzeba. Jeśli parametrów jest kilka to możemy je nazwać pop prostu „parametrami” 😁, ale jak się pipeline komplikuje i trzeba…

Dobre praktyki
Zebrałem taką krótka listę dobrych praktyk. Żeby o nich nie zapomnieć i mieć ściągawkę na przyszłość. Są to ogólne zasady, które będą lepiej już gorzej pasować do większości scenariuszy. Aczkolwiek musisz pamiętać, że czasami występują odstępstwa od reguły. Jak zwykle w życiu trzeba dokładnie przemyśleć każdą decyzję. Planowanie Proces planowania na piśmie: Nie muszę chyba…
7 rzeczy do optymalizacji Apache Spark
Apache Spark jest narzędziem bardzo skomplikowanym, i nie wielu z nas ma czasu na czytanie kodu źródłowego. Tego wszystkiego jest za dużo. Również podczas projektu nie ma za wiele czasu na dogłębna analizę. Zadbaj o to żeby uprościć sobie życie. Chciałem tutaj zebrać najważniejsze elementy z procesu optymalizacji. Mają one Ci pomóc w jak najszybszym…
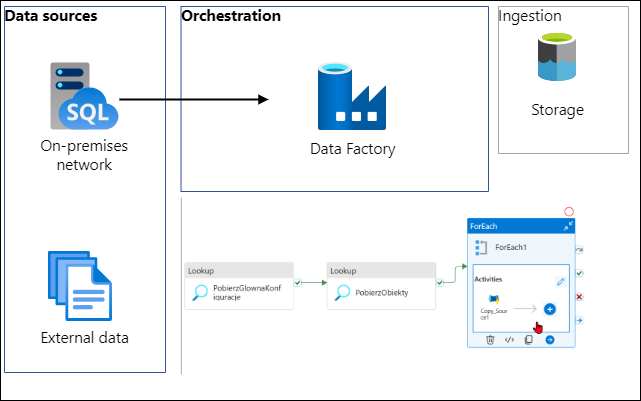
Jak pobrać dane z on-prema używając ADF
Jak to zwykle bywa na początku projektu zanim rozpoczniesz używać magiczną technologię Big Data to najpierw musisz jakoś te dane pobrać. A jak je pobrać używając narzędzi Azure? Najlepszym narzędziem jest Azure Data Factory czyli kombajn do wszystkiego. 😁 no dobra trochę przesadzam, ale to solidne narzędzie do orkiestracji pobierania danych i do tego działa.…

Co warto wiedzieć o pamięci wykonawcy (executor)
Dwa podstawowe problemy z jakimi się często spotykam związane są z osiągami jakie jestem w stanie uzyskać w Spark. Tobie też może się to przydarzyć jeśli już się nie wpadłeś w podobną pułapkę. proces działa bardzo wolno występują błędy OOM (out of memory errors) Z mojego punktu widzenia to najczęstsze co mi się przydarza. Aplikacja…
Continue Reading Co warto wiedzieć o pamięci wykonawcy (executor)

Tabele Delta jak działa płynne kastrowanie (Liquid Clustering)
Partycjonowanie danych Partycjonowanie powstało po to żeby posegregować dane. Jeśli masz milion plików i chcesz wyciągnąć konkretną informację, to chwilę będziesz musisz poczekać. I ta chwila może potrwać sporo czasu i do tego przepalisz sporo kasy. Tutaj wkracza partycjonowanie, czyli pogrupowanie danych według jakiegoś klucza. Żeby dobrze dobrać partycję musisz wiedzieć jakie są twoje główne…
Continue Reading Tabele Delta jak działa płynne kastrowanie (Liquid Clustering)
Apache Spark operacje na kolumnach
Kolumny Kolumny w Spark Dataframe maja taką samą charakterystykę, jak w przypadku Pandas czy R DataFrames, na pewno znasz je z excela, bądź bazy relacyjnej. Koncepcja jest taka sama. Możesz dokonywać różnych operacji na wybranych lub wszystkich kolumnach. Operacje te będą zależeć od typu danych kolumny. W Sparku możesz odnieść się do kolumny na kilka…

Jak walidować schemat danych w Apache Spark
Walidacja schematu danych jest bardzo ważnym etapem, w każdym projekcie z danymi. Jest to klucz do sukcesu i należy go potraktować poważnie. Poniżej znajdziesz przykłady jak walidować schemat danych i jakie masz dostępne narzędzia w Apache Spark i Databricks. Oczywiście możesz zrobić znacznie więcej dla jakości danych, ale to są podstawy dla pierwszej wersji twojego…
Continue Reading Jak walidować schemat danych w Apache Spark

Efektywniejsza praca z Databricks CLI
Jeśli pracujesz z Databricks, to powinieneś znać Databricks CLI, służy do wydawania poleceń i kontroli środowiska roboczego w Databricks. Dzięki niemu jesteś w stanie zarządzać obszarem roboczym w Databricks, gdzie są hostowane klastry Apache Spark, notatniki biblioteki, joby, ect. Co to jest Databricks cli Jak wskazuje nazwa Command Line Interface jest narzędziem, które działa w…
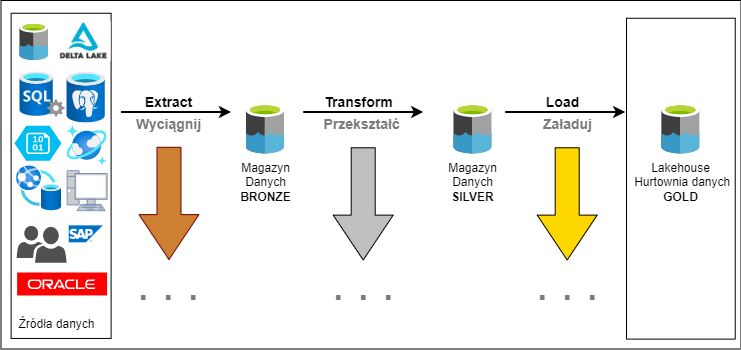
ETL – mechanizm, który napędza świat danych
Na pewno nie raz spotkałeś się z terminem ETL. Jest to akronim, jak się domyślasz pochodzi z angielskiego Extract Transform and Load. Jest to najpopularniejszy na świecie proces przetwarzania danych. Przetłumaczone na polski Wyciągnij, Przekształć i Załaduj. To wieloetapowy proces przetwarzania danych. Stosuje się go, kiedy organizacja chce stworzyć centralne repozytorium danych. Każdy z tych…
Continue Reading ETL – mechanizm, który napędza świat danych

7 rzeczy które musi umieć inżynier danych
Co robi inżynier Danych W największym skrócie inżynier Danych jest odpowiedzialny za przygotowanie i integrację danych. Dane trzeba przygotować do użycia bo surowe raczej są w słabej formie. A integracja to połączenie danych z wielu źródeł i form. Skąd biorą się dane w twojej firmie? Na samym początku źródła są ludzie, którzy te dane generują.…
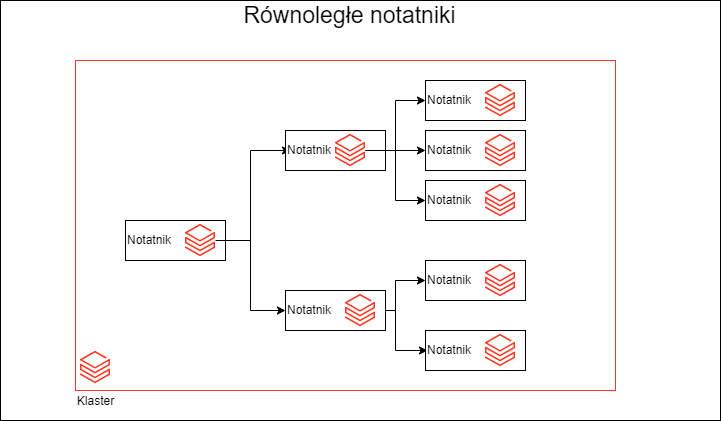
Czy można wykonać notatniki Databricks równolegle
Jak wiesz Spark jest stworzony do przetwarzania równoległego. Nie o tym jednak chcę dzisiaj napisać, ale o równoległym wykonaniu notatników Databricks. Stanąłem oko w oko przed problemem orkiestracji wielu kolekcji danych. I pojawił się problem ich ilości, w tradycyjnym podejściu musiałbym uruchomić kilkadziesiąt notatników jeden po drugim. Co nie jest zbyt efektywne. Mam kilkanaście kolekcji…
Continue Reading Czy można wykonać notatniki Databricks równolegle

Co przysienie rok 2022 dla Inżyniera Danych – 7 trendów
1. Cloud Jeśli jeszcze nie jesteście w temacie to niewątpliwie musisz pomyśleć o chmurze. Staje się ona nieodzowną częścią naszego świata IT. Coraz więcej firm myśli i zaczyna coraz mocniej cisnąć w chmurę. Oczywiście on-premises nie zniknie z pola widzenia i jeśli firma ma już jakieś rozwiązanie lokalnie, to zapewne będzie go utrzymywać. Obserwując rynek…
Continue Reading Co przysienie rok 2022 dla Inżyniera Danych – 7 trendów

Co powinieneś wiedzieć o Spark Dataframe
Dataframe czyli ramka danych Ramka danych jest obiektem istniejącym w pamięci RAM. Najłatwiej ją zobrazować jako tabelę, która posiada kolumny oraz rzędy danych. Każda kolumna tak jak w bazie danych posiada nazwę oraz typ danych. Dataframe jest kolekcją obiektu Row (RDD[Row]) i schematu. Taka 'tabelka’ w pamięci ma bardzo dużo zalet dla analityka. Łatwo z…
Big data, czy wiesz kiedy użyć tej technologii?
Jeśli zadałeś sobie pytanie, „big data co to?”, to jesteś w dobrym miejscu. Postaram się wyjaśnić do czego służy ta technologia, i kiedy użyć tego zestawu narzędzi. Ten prosty model, powinien Ci pozwolić dobrać optymalną technologię, pasującą do twojego problemu. Big Data przetłumaczone z angielskiego oznacza dosłownie „duże dane” po polsku lepiej by brzmiało „dużo…
Continue Reading Big data, czy wiesz kiedy użyć tej technologii?

Apache Spark na Windowsie czy to możliwe?
Witam, do tej pory pisałem o Databricks jako o super narzędziu do Big Data. Jest on niewątpliwie bardzo użyteczny, ale do tego potrzeba przeglądarki i dostępu do chmury publicznej, Azure, AWS lub GCP. A co jeśli chcesz zacząć przygodę ze Apache Spark na Windowsie bez wydawania kasy na chmurę. Mam dla Ciebie dobre wieści jest…
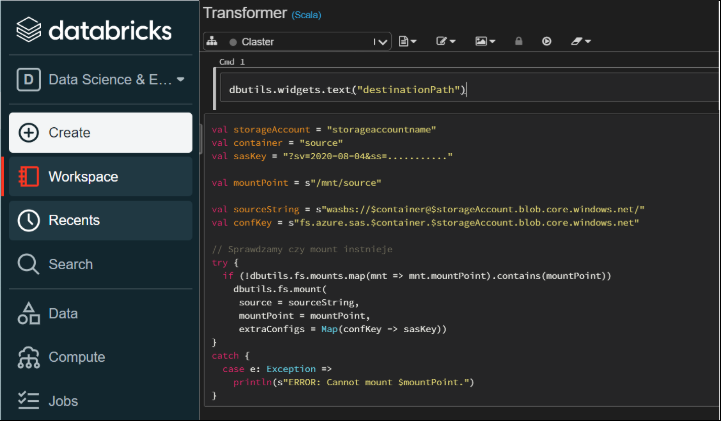
Ten kod może Ci się przydać…
Jeśli pracujesz w środowisku Databricks, to najprawdopodobniej będziesz potrzebował zautomatyzować część funkcjonalności, żeby ułatwić sobie życie. Nie mówię tutaj tylko o produkcji, ale o pracy na devie. Przygotowałem trochę kodu, z którego często korzystam. Są to elementy przydatne może nie na co dzień, ale od Świeta 🙂 więc warto o nich pamiętać. Może i tobie się przyda. Dbutils Jest to…

10 Blogów dla Inżyniera Danych, Które Warto Śledzić w 2021.
jaceklaskowski.gitbooks.io Jacek Laskowski jest programistą z wieloletnim stażem i dużym bagażem doświadczeń, który dzieli się wiedzą i za to go lubimy. Jacek napisał i wciąż pisze wspaniałą książkę o Sparku. Książka jest w wersji elektronicznej, dzięki temu jest dostępna online i łatwa w przeszukiwaniu. Jest to zestawianie dokumentacji z przykładami. Znajdziesz tam mnóstwo informacji o…
Continue Reading 10 Blogów dla Inżyniera Danych, Które Warto Śledzić w 2021.

11 Ciekawostek Databricks
1. Platforma analityczna Databricks to platforma analityczna oparta na Spark. Została założona przez twórców Sparka na uniwersytecie UC Berkeley w 2013, czyli już 8 lat na rynku. Databricks pracuje nad rozwojem Sparka, łącząc siły ze społecznością wpierającą ten projekt. Jako firma dodali więcej kodu do Sparka niż jakakolwiek inna organizacja. Ta firma płaci swoje rachunki…

Czy Data Lakehouse pożre Hurtownię Danych?
Czy hurtownie danych przejdą do lamusa a świat BI ogarnie nowa moda. Jest alternatywa dla hurtowni danych zwie się Data Lakehouse.