
Apache Spark to silnik do przetwarzania danych. Zawiera całą masę bibliotek, których można używać do przetwarzania danych w klastrze komputerów. Najważniejszą korzyścią jest możliwość równoległego przetwarzania danych. Obecnie jest jednym z najpopularniejszych narzędzi do Big Data. Obsługuje wiele języków programowania (Python, SQL, Scala i R). Możesz rozwiązywać problemy na wiele sposobów, używając SQL, transmisji danych („data streaming”) i uczenia maszynowego.
Jest szeroko stosowany w inżynierii i nauce tam gdzie ilości danych uniemożliwiają użycie tradycyjnych metod przetwarzania danych. Jednym z ważniejszych użytkowników, który przychodzi mi do głowy, jest CERN, który mieli peta bajty danych i przetwarza je za pomocą Sparka. Można go używać w lokalnych klastrach, publicznej chmurze obliczeniowej lub klastrach rozproszonych. Może zarządzać ogromnymi ilościami danych.
Spark koordynuje wykonywanie zadań na danych w klastrze. Do zarządzania klastrem i jego zasobami potrzebuje dodatkowego narzędzia, takiego jak YARN lub Mesos. Narzędzia te przydzielają zasoby w klastrze takie jak CPU, pamięć RAM oraz zarządzanie zadaniami. Zasadniczo Spark to zestaw narzędzi, które współpracują ze sobą, zapewniając kompleksowe rozwiązanie do przetwarzania danych.
Równoległość Sparka
Najważniejszą zaletą Sparka jest równoległość wykonania przetważania.
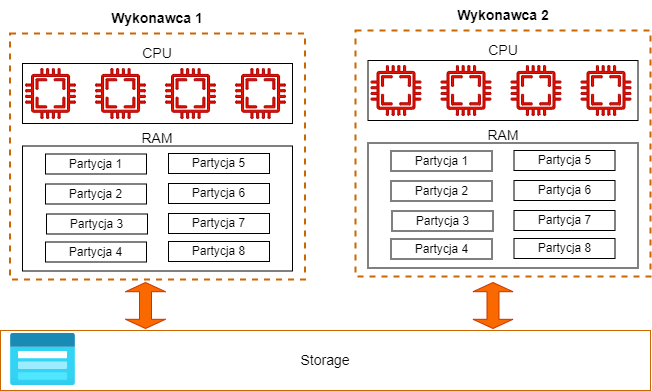
Na diagramie widać jak pojedyncza maszynka jest w stanie przetwarzać dane równolegle. Każdy rdzeń jest w stanie pracować na osobnej partycji danych w tym samym czasie co niesamowicie przyspieszy przetwarzanie danych. Kiedy dane będą zapisywane to na koncie magazynu pojawi się wiele plików.
Wyobraź sobie plik Excela, w którym jest 100 wierszy w tradycyjnym podejściu wszystkie wiersze będą przetwarzane sekwencyjnie jeden po drugim. Spark jest znacznie sprytniejszy i potnie dane na kawałki np. na 4 partycje i wtedy jest w stanie pracować na nich równolegle po 24 wiersze na każdym rdzeniu. Ten mechanizm jest trochę bardziej skomplikowany, ale go tutaj upraszczam żeby przedstawić podstawy działania Apache Spark.
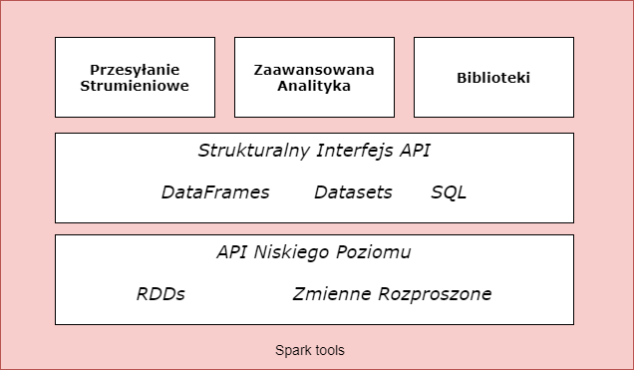
Zestaw narzędzi Apache Spark
Masz do dyspozycji cały pakiet narzędzi i bibliotek Sparka. Spark składa się z interfejsów API niższego poziomu i interfejsów API strukturalnych. możesz również uzyskać dostęp do szeregu bibliotek dla dodatkowej funkcjonalności. Możesz wykonywać dowolne działania związane z danymi. Może to być analiza wykresów, uczenie maszynowe lub strumieniowe przesyłanie danych.
Strukturalny interfejs API
Strukturalne API nazywane są zestawami danych („dataset”). Możesz ich używać do pisania statycznego kodu w Javie lub Scali. Ten zestaw danych nie jest dostępny w języku Python lub R, ponieważ są to języki dynamiczne. Interfejs API zestawu danych umożliwia przypisywanie Java / Scala do rekordów w DataFrame i manipulowanie nimi jako kolekcją obiektów. Ta elastyczność zestawu narzędzi ułatwia korzystanie z interfejsu API wyższego poziomu do prostej analizy danych. Jeśli masz bardziej złożony problem, możesz go rozwiązać za pomocą interfejsów API niższego poziomu, takich jak zestawy danych („datasets”) lub RDD. zapewniają bezpieczną manipulację danymi.
Przesyłanie strumieniowe
Jest to interfejs API wysokiego poziomu do przesyłania strumieniowego struktur zamiast przetwarzania wsadowego. Może to pomóc w zmniejszeniu opóźnień i umożliwić przetwarzanie przyrostowe. Największą zaletą jest szybkie wydobycie wartości ze strumienia praktycznie bez zmian kodu. Możesz rozpocząć od zadania wsadowego, a następnie przekonwertować go na streaming. W ten sposób poprzez stopniowe przetwarzanie danych masz pełną kontrolę nad całym procesem.
Nauczanie maszynowe
Obecnie uczenie maszynowe jest bardzo ważne i pomaga w automatyzacji trudnych zadań. Spark ma bibliotekę MLlib, która umożliwia przetwarzanie, szkolenie modeli i dokonywanie prognoz. Masz dostęp do bardzo zaawansowanego interfejsu API, który pozwala na wykonanie kilku zadań, takich jak klasyfikacja, regresja, grupowanie lub głębokie uczenie się.
Interfejsy API niższego poziomu
Spark ma interfejsy API niższego poziomu, aby umożliwić dowolną manipulację obiektami Java i Python za pomocą Resilient Distributed Datasets (RDD). Prawie wszystko w Spark jest oparte na RDD. w przypadku podstawowych zadań zaleca się stosowanie DataFrames, które są interfejsami API wyższego poziomu. Oferują prostotę dla użytkownika. Oczywiście, jeśli potrzebujesz dostępu do fizycznego wykonania, takiego jak partycjonowanie, RDD mogą być lepszym wyborem.
SparkR
Jest to narzędzie do uruchamiania R na Spark. Ma takie same zasady jak inne interfejsy API języka Spark. Dobra wiadomość dla miłośników R jest taka, że prawie wszystko, co jest dostępne w Pythonie, jest dostępne w R. Społeczność stworzyła mnóstwo bibliotek, dostępnych jest ponad 300 pakietów spark-packages.org.
Strukturalny interfejs API
Strukturalne interfejsy API świetnie nadają się do manipulowania wszystkimi typami danych. Możesz zarządzać plikami nieustrukturyzowanymi, półstrukturalnymi plikami CSV i plikami strukturalnymi Parquet. Istnieją trzy rodzaje interfejsów API
- Zestawy danych
- DataFrames czyli ramka danych
- Tabele i widoki SQL
Dzięki strukturalnym interfejsom API można uruchamiać zarówno zadania wsadowe (batch), jak i strumieniowe (streaming). Przełączanie między wsadem a przesyłaniem strumieniowym jest bardzo proste. Zadania rozpoczynają się od wykonania wykresu instrukcji. Są one podzielone na etapy. Logiczną strukturą, którą można manipulować za pomocą przekształceń (transformations) i działań (actions), są ramki danych i zestawy danych. Trzeba pamiętać że akcje wywołują transformacje.
DataFrame i zestawy danych
Są to kolekcje strukturalne reprezentujące kolekcje tabelaryczne z wierszami i kolumnami (Excel jest dobrą analogią). Są niezmienne, co oznacza, że nie możesz ich zmienić po stworzeniu. Są takie same jak tabele i widoki dla Spark SQL. Kiedy mówimy o tej kolekcji, dobrze jest poznać koncepcję schematu. Schemat („schema”) wymusza nazwy kolumn i typy danych, takie jak ciąg lub liczba całkowita. Typy Spark są mapowane bezpośrednio na interfejsy API różnych języków.
Typy DataFrames są weryfikowane przez Spark i środowisko wykonawcze. Z drugiej strony typy zestawów danych są sprawdzane w czasie kompilacji. Zestawy danych są dostępne tylko dla języków opartych na JVM, takich jak Java lub Scala.
Ramki danych to po prostu zestawy danych typu Row czyli takie kolumny i rzędy jakie widzimy w excelu. Ramki są wewnętrzną reprezentacją zoptymalizowanego formatu Sparka do obliczeń. Kolumna reprezentuje prosty typ, taki jak ciąg znaków lub liczba całkowita.
Agregacje
Kiedy coś agregujesz, ostatecznie zbierasz podsumowania danych. Jest to fundament analityki Big Data. W agregacji określisz klucz lub grupę i funkcję agregacji. W ten sposób określisz, jak chcesz przekształcić jedną lub więcej kolumn. W większości przypadków agregujesz, aby podsumować dane liczbowe za pomocą pewnego grupowania. Dzięki Spark możesz agregować dowolne wartości do tablicy, listy lub mapy.
Dość często wykonujesz jakieś obliczenia na podstawie grup danych. Istnieje kilka rodzajów grupowania dostępnych w Spark:
- Proste grupowanie („Simple grouping”): podsumowanie DataFrame poprzez wykonanie agregacji w instrukcji select.
- Grupuj według klucza („Group by”): określ jeden lub więcej kluczy i jedną lub więcej agregacji, aby przekształcić kolumny wartości.
- Okno („Window”): jest podobne do grupy, ale wiersze wprowadzone do funkcji są w jakiś sposób powiązane z bieżącym wierszem.
- Zestaw grupujący („Grouping set”): można stosować agregację na wielu różnych poziomach. Są one dostępne jako operacje podstawowe w SQL oraz poprzez pakiety zbiorcze i kostki w DataFrames.
- Zestawienie („Rollup”): określ jeden lub więcej kluczy i jedną lub więcej agregacji, aby przekształcić kolumny wartości, które zostaną podsumowane hierarchicznie.
- Kostka („Cube”): określ jeden lub więcej kluczy i jedną lub więcej agregacji, aby przekształcić kolumny wartości, które zostaną podsumowane we wszystkich kombinacjach kolumn.
Dostępnych jest kilka funkcji agregujących, takich jak count, countDistinct, count_distinct, first and last, min i max, sum, ect.
Jeśli chcesz wykonać pewne agregacje, które nie są dostępne, możesz je samodzielnie zdefiniować, nazywane są UDFs. Możesz tworzyć niestandardowe formuły lub reguły biznesowe.
Łączniki czyli Joins
Podczas pracy z danymi bardzo często pojawia się problem, kiedy trzeba będzie połączyć różne zestawy danych. Na tym właśnie polegają połączenia (joins), łączą dwa zestawy danych lub więcej. Ten mechanizm porównuje lewy i prawy zestaw danych na jednym lub większej liczbie kluczy i określa, czy Spark powinien połączyć lewy zestaw z prawym zestawem.
Najczęstszym jest equi-join porównuje, czy określone klucze w lewym i prawym zestawie danych są równe. Jeśli są one równe, Spark połączy lewy i prawy zestaw danych.
Dostępnych jest kilka rodzajów złączeń
Połączenia wewnętrzne (inner joins): zachowaj rzędy z kluczami, które wychodzą po lewej i prawej stronie
Połączenia (outer join) zewnętrzne: zachowuje wiersze istniejące w lewym lub prawym zestawie danych
Lewe połączenia zewnętrzne (left outer join): zachowaj wiersze z kluczami w lewym zestawie danych
Prawe połączenia zewnętrzne (right outer join): przechowuj wiersze z kluczami w prawym zbiorze danych
Lewe pół-złączenia (left semi join): trzymaj wiersze po lewej, a tylko po lewej, gdzie klucz pojawia się w prawym zbiorze danych
Lewy łącznik anty (left anti join): trzymaj wiersze po lewej i tylko po lewej stronie, gdzie nie pojawiają się w prawym zbiorze danych
Połączenia naturalne (natural join): wykonaj połączenie, domyślnie dopasowując kolumny między dwoma zestawami danych o tych samych nazwach
Złączenia krzyżowe (cross join): dopasowuje każdy wiersz w lewym zbiorze danych z każdym rzędem w prawym zbiorze danych.
Podczas wykonywania złączeń występują pewne trudności. Chociaż mogą się zdarzyć w rzadkich okolicznościach, powinieneś o nich wiedzieć.
Jedną trudną rzeczą jest zduplikowana nazwa kolumny. W DataFrame każda kolumna ma unikalny identyfikator w silniku Spark SQL – Catalyst. Ten identyfikator jest wewnętrzny i nie można się do niego odwoływać. W niektórych przypadkach, jeśli dwa zestawy mają takie same nazwy kolumn, możesz mieć mały problem. Istnieją dwa sposoby rozwiązania tego problemu.
- Jeśli istnieją dwie kolumny o takich samych nazwach kluczy, najłatwiejszym sposobem jest zmiana wyrażenia łączenia z wartości logicznej na ciąg znaków. Spowoduje to automatyczne usunięcie zduplikowanej kolumny z zestawu.
- Możesz usunąć kolumnę po dołączeniu.
- Zmień nazwę kolumny przed złączeniem.
Źródła danych
Spark zapewnia funkcjonalność gotową do pracy z różnymi źródłami danych. Społeczność ma sześć podstawowych źródeł danych i setki źródeł zewnętrznych. Podstawowymi źródłami danych Sparks są
- CSV
- JSON
- Parkiet
- ORC
- Połączenia JDBC / ODBC
- Zwykłe pliki tekstowe
Społeczność zapewnia znacznie więcej połączeń, takich jak Cassandra, HBase, AWS Redshift, XML ect.
Odczyt interfejsu API wygląda następująco
DataFrameReader.format(...).option(" key", "value").schema(...).load()
Podstawowa struktura zapisu danych jest następująca:
DataFrameWriter.format(...). option(...). partitionBy(...).bucketBy(...).sortBy( ...).save()
Jednym z najpotężniejszych narzędzi do jakiego możemy się połączyć jest SQL Server, który jest bardzo popularny. Możesz również połączyć się z MySQL, PostgreSQL. Tutaj dam ci wskazówkę, ponieważ Spark nie może tłumaczyć wszystkich własnych funkcji na funkcje dostępne w bazie danych SQL, zaleca się przekazanie całego zapytania do SQL. Zwróci wynik w postaci DataFrame.
Spark SQL
To bardzo ważna funkcja, która ułatwi Ci życie. Dzięki Spark SQL możesz uruchamiać zapytania SQL względem widoków lub tabel. Spark zapewnia funkcje do analizy planów zapytań w celu optymalizacji obciążeń. To integruje się bezpośrednio z DataFrames i Datasets API.
W wersji 2.0 Spark obsługuje zarówno zapytania ANSI-SQL, jak i HiveQL. Moc Spark SQL jest w stanie wykorzystać w dowolnym przepływie danych. Jego interfejs API pozwala na ekstrakcję danych za pomocą SQL zmanipulowanego jako DataFrame. Następnie możesz przekazać go do MLlib, a następnie użyć go jako innego źródła danych. Należy pamiętać, że ten język został zaprojektowany do pracy z obciążeniami OLAP, a nie bazami danych OLTP o niskim opóźnieniu.
Spark SQL i Hive
Kolejną dobrą wiadomością jest to, że Spark SQL ma dobre relacje z Hive. Hive przechowuje informacje o tabelach do użytku między sesjami w „metastore”. Jest to przydatne dla użytkowników pracujących w niektórych starszych systemach Hadoop. Musisz pamiętać, że istnieje kilka wymagań, które musisz spełnić, aby uzyskać dostęp do magazynu Hive.
Spark SQL CLI
Spark SQL CLI to wygodne narzędzie, za pomocą którego można wykonywać podstawowe zapytania Spark SQL w trybie lokalnym. Wszystko to jest dostępne w wierszu poleceń.
Aby uruchomić interfejs Spark SQL CLI, uruchom następujące polecenie w katalogu Spark: ./bin/spark-sql
Interfejs Spark SQL
Możesz wykonywać zapytania SQL za pomocą interfejsów API Spark SQL. Możesz to zrobić za pomocą metody sql na obiekcie „Spark session”, powoluje to DataFrame. Podobnie jak inne transformacje, zostanie to wykonane leniwie. Jest to wielka zaleta, ponieważ istnieją transformacje, które są o wiele prostsze do wyrażenia w kodzie SQL niż w DataFrames.
Przykład:
spark.sql(„SELECT 1 + 1”).show()
Spark zapewnia interfejs JDBC, za pomocą którego można połączyć się ze sterownikiem i wykonywać zapytania SQL.
Katalog
Katalog przechowuje metadane dotyczące tabel, a także inne pomocne rzeczy, takie jak bazy danych, funkcje i widoki. Jest on dostępny w pakiecie org.apache.spark.sql.catalog.Catalog i zawiera szereg pomocnych funkcji. Musisz owinąć cały kod w funkcję spark.sql.
Tabele
Aby efektywnie współpracować ze Spark SQL, musisz zdefiniować tabele. Tabele są logicznie równoważne ramkom danych o tej samej strukturze. Możesz wykonywać takie same operacje, jak agregacja, filtracja lub łączenia. Główną różnicą między nimi jest zakres, DataFrame są zdefiniowane w języku programowania, niezależnie od tego, czy tabele są zdefiniowane w bazie danych. Istnieje koncepcja domyślnej tabeli, w której będą przechowywane tabele, chyba że określisz, gdzie dokładnie powinny się znaleźć.
Musisz pamiętać, że tworząc tabelę z pliku, tworzysz tabelę niezarządzaną. Podczas tworzenia tabeli z DataFrame przy użyciu tworzona jest tabela zarządzana. Dla których Spark będzie śledził wszystkie istotne informacje.
Spark SQL jest w pełni kompatybilny z instrukcjami Hive SQL (HiveQL).
Zestawy danych
Zestawy danych („dataset”) to podstawowy typ strukturalnych interfejsów API. Są one dostępne tylko w JVM, co oznacza użycie Scala lub Java. Za pomocą zestawów danych możesz zdefiniować obiekt, który będzie zawierał każdy wiersz w swoich zestawach danych. Spark manipuluje dla Ciebie danymi obiektu wiersza
Podczas korzystania z interfejsu DataFrame API nie tworzy się ciągów ani liczb całkowitych, ale Spark manipuluje danymi za Ciebie, manipulując obiektem Row. To, czego potrzebujesz do typów, to koncepcja „Enkodera”. Zadaniem enkodera jest mapowanie typów danych języka na wewnętrzny typ Sparka. Aby dowiedzieć się, jakie są typy danych Spark, przejdź do dokumentacji Spark. Są one głównie użyteczne, gdy nie można wykonywać manipulacji na DataFrames, wówczas należy przełączyć się na zestawy danych. Ponadto API zestawów danych jest bezpieczne dla typu, co oznacza, że operacja zakończy się niepowodzeniem w czasie kompilacji, a nie w czasie wykonywania.
Partycjonowanie
Partycjonowanie to bardzo ważna koncepcja. Musisz dokładnie zrozumieć ten temat, aby zapewnić optymalne działanie aplikacji. Spark wykorzystuje partycje do przetwarzania danych w tym samym czasie. Pozwalają one na równoległe i oczywiście rozproszone przetwarzanie danych przy minimalnym ruchu w sieci. Jeśli zaczniesz wymieniać dane między procesami wykonawczymi, pojawi się duży narzut. Sieć zostanie obciążona dużą ilością danych a tym samym spowolni proces.