
W wielu przypadkach ładowania danych w procesie ETL będziesz potrzebował/ła sparametryzować proces zasilania. Prawie każdy pipeline wymaga jakiś parametrów, np. nazwa tabeli, nazwa środowiska (dev, test, prod) ect.. Im bardziej skomplikowany pipeline tym więcej parametrów potrzeba. Jeśli parametrów jest kilka to możemy je nazwać pop prostu „parametrami” 😁, ale jak się pipeline komplikuje i trzeba 30 elementów obsłużyć to wtedy nazywa się to konfiguracja. Oto kilka propozycji jak to ogarnąć w Databricks:
Zanim dobierzesz konfigurację do swojego problemu ważne jest żeby przeanalizować dokładnie problem. Jak to zwykle bywa trzeba zadać kilka pytań, które doprowadzą cię do rozwiązania.
Jak często parametry będą aktualizowane. Jeśli będą one aktualizowane bardzo często to plik w repozytorium trzeba jakoś uaktualnić. Kwestia czy taka aktualizacja odbędzie się zgodnie z harmonogramem releasa. Są projekty gdzie kod jest wrzucany na prod raz na tydzień są też takie gdzie można go wrzucać codziennie. I teraz jeśli masz proces tygodniowy, a zmiany do konfiguracji klient chce robić trzy razy w tygodniu. To by oznaczało, że repo to nie najlepsze miejsce i trzeba wrzucić go gdzie indziej. to jest rzadki case, ale chcę zwrócić uwagę na sposób myślenia przy podejmowaniu decyzji. Polecam rozrysować sobie drzewko decyzyjne, które doprowadzi Cię do celu, przykład z artykułu o Big Data. Tip❗❗❗ i dobra praktyka trzymaj je w repo chyba, że jest jakaś wyjątkowa sytuacji gdzie nie możesz tego zrobić.
Oto kilka przykładów:
- Parametr notatnika
- Csv
- Tabela
- Json
- Słownik
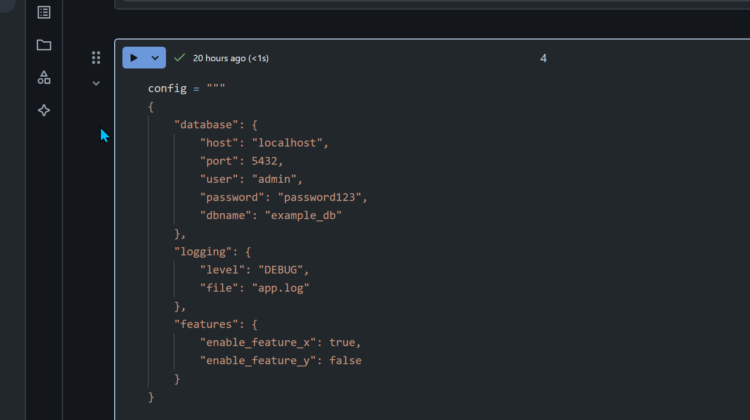
Parametry notatnika
To jest najbardziej oczywiste miejsce gdzie powinieneś stworzyć najważniejsze parametry. Tutaj wrzucasz te najważniejsze czyli środowisko, nazwa tabeli, to co jest niezbędne dla danego notatnika. Same parametry wrzucasz do komórki w notatniku. Ich ilość będzie ograniczona, nie zalecał bym ładowania nadmiernej ilości bo będzie bałagan i ciężkie do utrzymania. Najczęściej będą one pochodzić z narzędzie uruchamiającego notatnik np. Azure Data Factory. Przykład poniżej
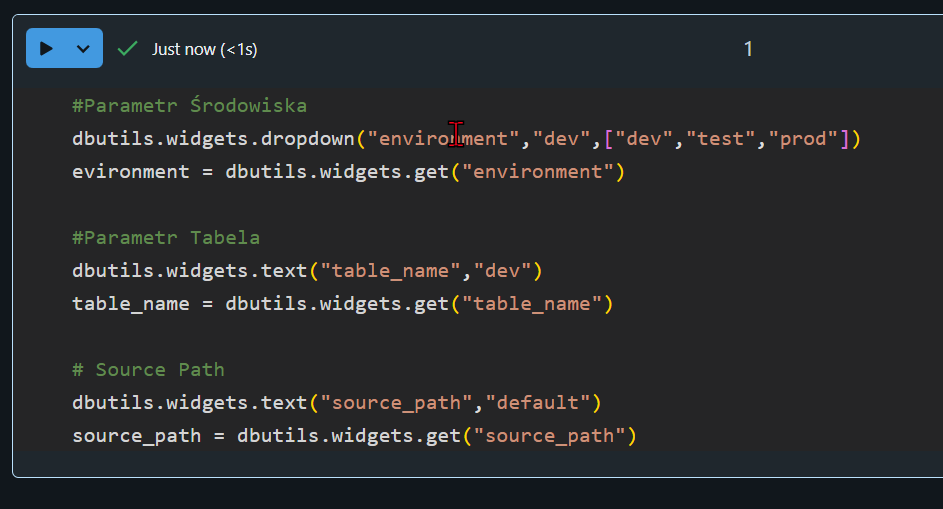
Csv
Jeśli masz potrzebę na kilkanaście bądź kilkadziesiąt parametrów to trzeba wykorzystać jakieś mocniejsze narzędzie. Ważne jest żeby parametry jak wszystko były w repozytorium. A plik csv jest łatwy to czytania i utrzymania. Można go otworzyć z Excela i tam zarządzać. Csv jest przydatny jeśli wystarczy płaska „dwu wymiarowa” struktura konfiguracji.
Działając w Databricks pliki z repozytorium są ładowane do Workspace podczas procesu CI/CD. Jeśli używasz Unity Catalog to dobrym miejscem są Volumes bądź Dbfs. Oczywiście może to być jakiś storage. Stamtąd twój proces wczyta plik wyciągnie niezbędne informacje i użyje ich w procesie. Możesz ich użyć bezpośrednio, chociaż ja bym polecał wrzucić do tabeli szczególnie jeśli jest ich dużo.
Warto dodać o czymś dość ważnym jak walidacji takich parametrów. Podczas czytania takiego pliku z konfiguracjami warto sprawdzić, czy wartości są zgodne z regułami. Bez walidacji może tam wpaść coś co popsuje dane, a tego byśmy nie chcieli.
Tabela
Bardziej pasuje do pliku csv, bo ma płaska strukturę. Sam plik csv możesz używać w procesie jeśli konfiguracja jest potrzebna w jednym miejscu bądź w kilku. A co jeśli dane konfiguracyjne są potrzebne w wielu pipelinach i cała masa procesów ciągle musi mieć dostęp do tego pliku. Wtedy sam csv i jego bezpośrednie użycie może być nie efektywne. W takim przypadku wczytujesz plik konfiguracyjny z dysku i ładujesz go to tabeli. Możesz użyć do tego dedykowanego notatnika, który będzie odpowiedzialny za ładowanie i walidacje danych konfiguracyjnych.
Zaletą tabeli jest jej dostępność w całym środowisku Databricks. Masz możliwość zadbania o jakąś historię czy wersjonowanie takiej konfiguracji. Można ją potraktować jak SCD (slowly changing dimentions) i przechowywać historię danych konfiguracyjnych.
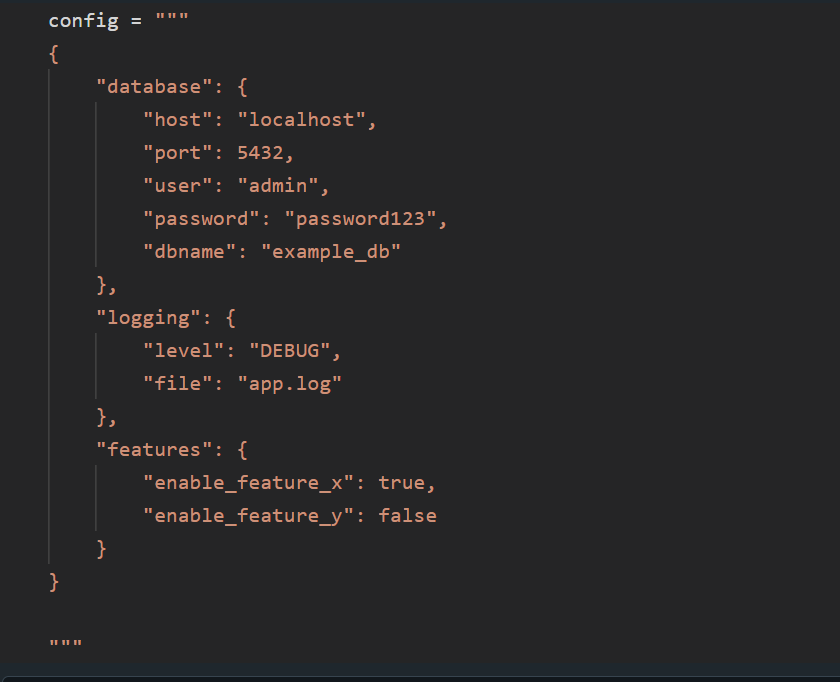
Json
Jeśli proces jest bardziej skomplikowany i trzeba trzymać zależności w konfiguracjach. Możesz potrzebować hierarchiczności w procesie wtedy wkracza mój ulubiony plik czyli json. Jest powód dlaczego jest tak popularny bo ma wielką moc, możesz tam zbudować całą skomplikowaną drzewiastą strukturę. A jego zaletą jest łatwość czytania, każdy język programowania ma jakąś bibliotekę do obróbki jsona. Z tym problemów raczej nie ma.
Takiego jsona ładujemy do repo i wyciągamy w procesie CI/CD. Powinien znajdować się jak najbliżej procesu gdzie będzie używany – Databricks. Zasada taka sama jak w csv wrzuć go do Volues lub Dbfs ewentualnie storage.
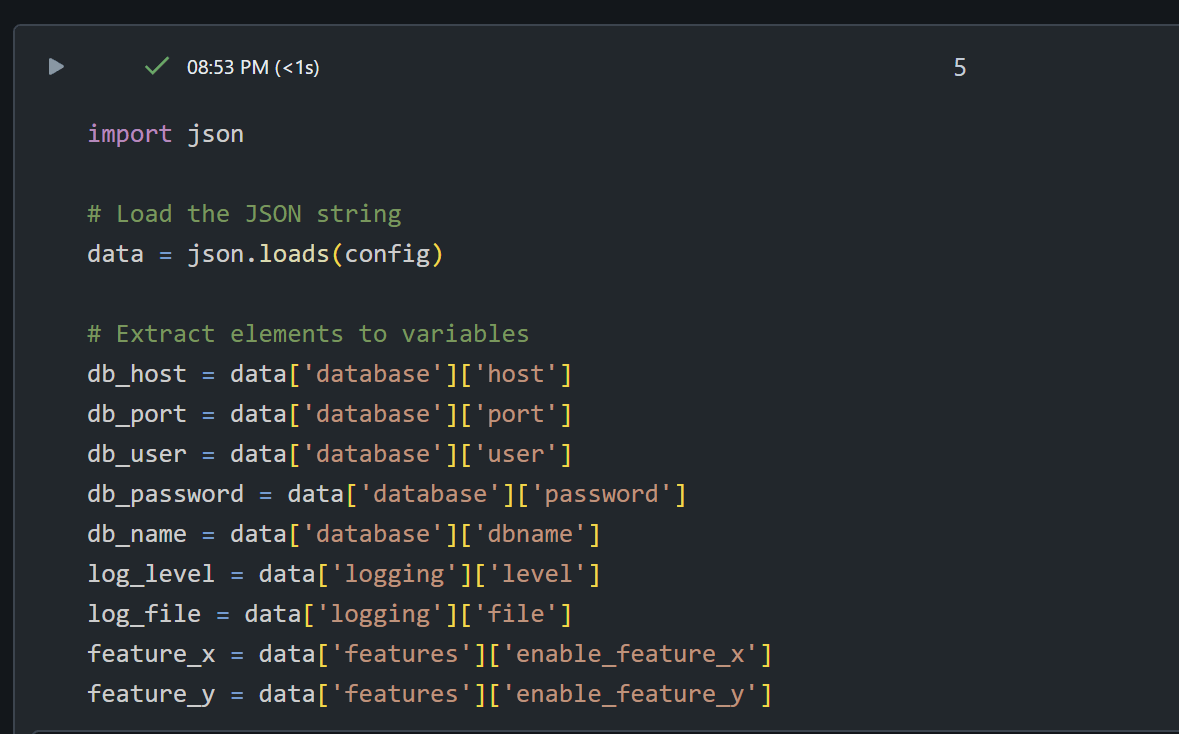
Słownik
Dla pewnych konfiguracji najwygodniej może być przetrzymywanie ich w dedykowanym notatniku. Tworzysz sobie notatnik tam wrzucasz słownik czyli prosty obiekt Pythonowy. Jeśli nie masz zbyt skomplikowanych wymagań to taki słowniczek może się świetnie sprawdzić.
Zaletą jest prostota rozwiązania i możliwość wrzucenia sporej ilości elementów. Wadą jest nie efektywny format dla bardziej skomplikowanej hierarchicznej struktury. Coś takiego możesz rozważyć jeśli pozostałe metody wydają się nie dostateczne. Możesz go użyć bezpośrednio w kodzie bądź zasilić dedykowaną tabelę. Mogą tam być wartości dla każdego środowiska, niech ogranicza Cię tylko twoja wyobraźnia.
CI/CD
Bardzo ważna część, wspominałem już o tym, ale chcę to podkreślić, cały proces zasilania konfiguracji musi być zautomatyzowany. To proces CI/CD przenosi pliki z repozytorium do miejsca docelowego. To już zależy od użycia, ale ogólna zasada ładuj go do Databricsa żeby był jak najbliżej procesu, w którym będzie użyty.
Podsumowanie
Każda z tych rozwiązań ma swoje wady i zalety. Dla każdego rozwiązania jedna z nich może być mniej lub bardziej optymalna. Musisz sprawdzić co jest najłatwiejsze w implementacji i utrzymaniu. Ma być solidne żeby nie dało się czegoś popsuć. Tutaj przypomina mi się zasada Poka-yoke. Wymyślna została przy produkcji samochodów przez Toyotę i to nic innego jak zabezpieczanie przed błędami użytkownika. Jak coś projektujesz to postaraj się żeby nie dało się czegoś popsuć przez przypadek. Przykład walidacji konfiguracji żeby była zgodna z regułami biznesu. Docelowe miejsce takiej konfiguracji musi być ściśle kontrolowane przez proces i nie dostępne dla zwykłego użytkownika.
Daj znać gdzie trzymasz i jak zarządzasz konfiguracją ?
ja wole hocon i czytanie przez dacite
Dzięki za informacje, nie słyszałem o tym, na dzień dzisiejszy wszyscy w zespole znają json lub yml i na tym działamy, nie trzeba dodatkowych narzędzi. Na pierwszy rzut oka jest prościej. Musiałbym zobaczyć w czym to jest lepsze, czy ma jakieś dodatkowe funkcjonalności.