
Jeśli pracujesz w środowisku Databricks, to najprawdopodobniej będziesz potrzebował zautomatyzować część funkcjonalności, żeby ułatwić sobie życie. Nie mówię tutaj tylko o produkcji, ale o pracy na devie. Przygotowałem trochę kodu, z którego często korzystam. Są to elementy przydatne może nie na co dzień, ale od Świeta 🙂 więc warto o nich pamiętać. Może i tobie się przyda.
Dbutils
Jest to funkcjonalność dostarczona przez Databricks i ułatwia prace w notebookach. Pozwala na użycie wielu funkcji. Podstawowe ich opcje to:
- Praca z obiektami na koncie magazynu, czyli blob lub data lake.
- Łączenie wielu notebooków i przekazywanie parametrów pomiędzy nimi.
- Praca z sekretami
secretsstosuje się je do przechowywania kluczy lub haseł.
Szczegóły znajdziesz w dokumentacji.
Przeglądanie zawartości konta magazynu
Jeśli chcesz wiedzieć, jakie masz dostępne pliki, to możesz wyświetlić pełną zawartość folderów. Działa w sytuacji, kiedy użyłeś funkcji mount i połączyłeś workspace z kontem magazynu (Blob Storage lub Data Lake). Przykład mount znajdziesz w kolejnym akapicie. Fs.ls wyświetli wszystkie pliki w danej ścieżce.
display(dbutils.fs.ls("/mnt/source/"))

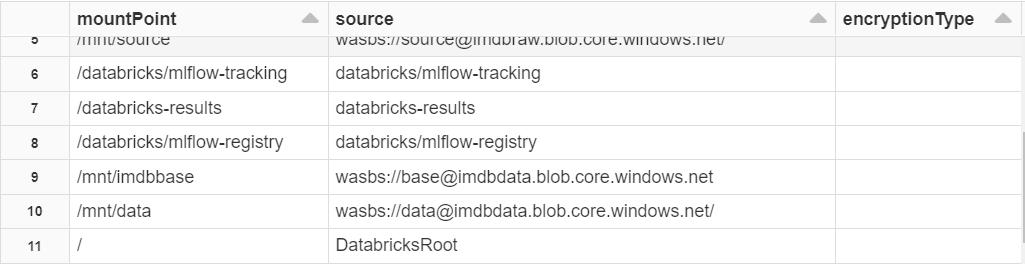
Przeglądanie połączonych kont magazynu
Dzięki tej funkcji możesz zobaczyć wszystkie połączone dyski (kontenery lub konta magazynu). Szczegóły dotyczące mount najdziesz w akapicie poniżej.
display(dbutils.fs.mounts)
Uruchamiani innych notatników
Jeśli chcesz stworzyć 'workflow’ czyli połączyć kilka notatników w jeden proces to masz możliwość ich uruchomiania z poziomu komórki ’cmd’. Na temat tworzenia workflows zrobię osobny wpis. Do tego potrzebujesz dbutils.notebook.run Pierwszy parametr to nazwa notatnika, drugi to timeout a trzeci to lista parametrów (w formacie klucz, wartość), jakie możesz przekazać do uruchamianego notatnika.
dbutils.notebook.run("nazwa-notatnika", 60, {"argument": "value1", "argument2": "value2", ...})
Łączenia notatników
Databricks daje Ci możliwość uruchomienia dodatkowego notatnika, który ma dostęp do tych samych zmiennych co notatnik wywołujący. Działa to odmiennie niż w przypadku dbutils.notebook.run. gdzie musisz przekazać zmienną w postaci parametru, niestety bezpośredni odczyt wartości zmiennych nie jest możliwy. Tutaj z pomocą przychodzi %run, który uruchomi drugi notatnik, ale scope zmiennych jest 'globalny’ – oba notatniki widzą swoje zmienne.
%run "./Notatnik 2"
Ustawianie parametrów notatnika i ich pobieranie
Ta funkcja jest bardzo przydatna, kiedy chcesz przekazać zmienną do notatnika. Najczęściej korzystam z tego, kiedy używam Data Factory do uruchomienia notatnika w Databricks. W samym notatniku użyję widgets żeby odczytać wartość przekazywanego parametru i przypisać do zmiennej.
dbutils.widgets.text("argument","wartość","nazwa")
val przykład = dbutils.widgets.get("argument")
Mount Drive
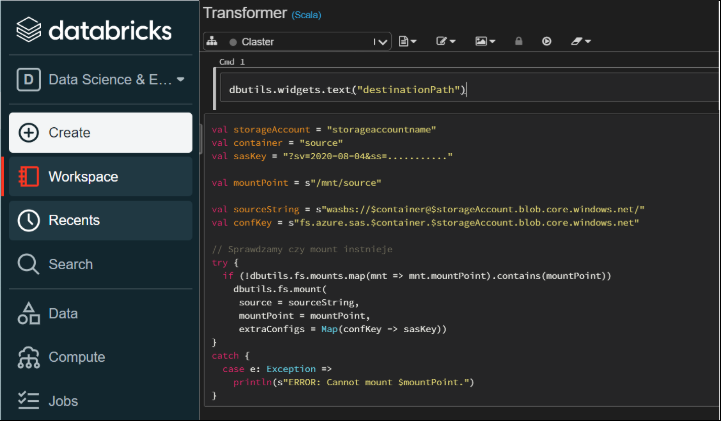
Jeśli chcesz korzystać z danych zapisanych w magazynie danych tj. Blob storage lub Data Lake, to masz możliwość połączenia się bezpośrednio z Databricks workspace. Poniżej jest przykładowy kod, który stworzy mountPoint. Jeśli chcesz go wykorzystać, to musisz podać dane ze swojej grupy zasobów. Możesz połączyć się do całego konta magazynu i mieć dostęp do zawartości wszystkich kontenerów lub przypisać mountPoint tylko do jednego kontenera.
Ważne !!!
Nie powinno się udostępniać klucza SAS i do tego ścieżki do konta magazynu, wtedy każdy może się do niego dostać. Produkcyjnie powinniśmy ukryć wszystkie poufne informacje w key vault i użyć Databricks Secrets.
Poniżej przykład jak użyć mount z kluczem SAS, można też użyć klucza konta magazynu, ale to jest znacznie mniej bezpieczne. SAS ma datę ważności, po której wygaśnie jego ważność.
//mount disk
val storageAccount = "nazwakontamagazynu"
val container = "source"
val sasKey = "?sv=2020-08-04&ss=..........."
val mountPoint = s"/mnt/source"
val sourceString = s"wasbs://$container@$storageAccount.blob.core.windows.net/"
val confKey = s"fs.azure.sas.$container.$storageAccount.blob.core.windows.net"
// Sprawdzamy czy mount instnieje
try {
if (!dbutils.fs.mounts.map(mnt => mnt.mountPoint).contains(mountPoint))
dbutils.fs.mount(
source = sourceString,
mountPoint = mountPoint,
extraConfigs = Map(confKey -> sasKey))
}
catch {
case e: Exception =>
println(s"ERROR: Cannot mount $mountPoint.")
}
JDBC i SQL Server
Poniżej znajdziesz przykład jak połączyć się z bazą w Azure i wykonać zapytanie TSQL. Zwrócone dane będą w Spark DataFrame i gotowe do użycia.
Ważne !!!
Jak w powyższym przykładzie powinienem użyć Databricks secrets, żeby trzymać nazwę użytkownika i hasło, ale nie jest to produkcja, więc mogę poszaleć 🙂
val user = "sqladminuser..."
val password = "Password..."
val jdbc = "jdbc:sqlserver://acmeservercentral.database.windows.net:1433;database=db_sqlmain;slProtocol=TLSv1"
val driver = "com.microsoft.sqlserver.jdbc.SQLServerDriver"
val listOfTables = spark.read
.format("jdbc")
.option("url", jdbc)
.option("user", user)
.option("password", password)
.option("driver", driver)
.option("query",s"SELECT * FROM information_schema.tables'")
.load()
Następny przykład zapisze Dataframe do bazy
listOfTables.write
.format("jdbc")
.option("url", jdbc)
.option("dbtable","dbo.stg_tablename")
.option("user", user)
.option("password", password)
.option("driver", driver)
.option("batchssize",2000)
.option("numPartitions",10)
.mode("append")
.save()
SQL-Spark-Connector dla SQL Server i Azure SQL
Niedawno pojawił się wysokowydajny łącznik, który umożliwia korzystanie z danych transakcyjnych w analizie Big Data i utrwala wyniki dla zapytań ad hoc lub raportowania. Łącznik umożliwia używanie dowolnej bazy danych SQL, lokalnej lub w chmurze, jako źródła danych wejściowych lub ujścia danych wyjściowych dla zadań Spark. Jest kompatybilny ze Spark 3.0. Od Lipcja jest w GA. Szczegóły na Github.
Są dwie wersje dostępne w Maven dla Scali 2.11 i 2.12
| Connector | Maven Coordinate | Scala Version |
|---|---|---|
| Spark 2.4.x compatible connnector | com.microsoft.azure:spark-mssql-connector:1.0.2 | 2.11 |
| Spark 3.0.x compatible connnector | com.microsoft.azure:spark-mssql-connector_2.12:1.1.0 | 2.12 |
Poniżej przykładowy kod odczytu i zapisu, więcej na Github.
val server_name = "jdbc:sqlserver://acmeservercentral.database.windows.net"
val database_name = "db_sqlmain"
val url = server_name + ";" + "databaseName=" + database_name + ";"
val table_name = "Persons"
val username = "admin...."
val password = "Password.....!"
//Odczyt
val jdbcDF = spark.read
.format("com.microsoft.sqlserver.jdbc.spark")
.option("url", url)
.option("dbtable", table_name)
.option("user", username)
.option("password", password)
.load()
//Zapis
dff.write
.format("com.microsoft.sqlserver.jdbc.spark")
.mode("append")
.option("url", url)
.option("dbtable", table_name)
.option("user", username)
.option("password", password)
.save()
Prosta metoda na schemat
Schemat danych jest dość ważny i dobrze mieć metodę, żeby go stworzyć i potem użyć podczas wczytywania danych. Jedna z prostych metod przedstawiam poniżej, oczywiście jest dość surowa i czasami trzeba schemat dostosować, ale zawsze ułatwia pracę.
W przypadku plików json czy csv ten kod wygeneruje schemat danych, który potem możesz użyć.
val file = spark.read.format("json")
.load("/mnt/source/shows.json")
file.schema.json
{"type":"struct","fields":[{"name":"_c0","type":"string","nullable":true,"metadata":{}}]}
Niby nic skomplikowanego ale zawsze pomoże.
Schemat możesz wczytać w pliku i załadować go jako `StructType`
import java.io.File
import java.nio.file.{Paths,Files}
import java.nio.charset.StandardCharsets
import org.apache.spark.sql.types._
val schemaFileName = Paths.get("/dbfs/mnt/source/shows-schema.json")
val schemaContent = new String(Files.readAllBytes(schemaFileName ), StandardCharsets.UTF_8)
val schema = DataType.fromJson(schemaContent).asInstanceOf[StructType]
Bezpieczne ładowanie danych
W pracy z danymi ważne jest, żeby złe dane nie przedostały się ze źródła do celu. I tutaj Spark daje Ci kilka opcji. Są to tzw 'Read Modes’, czyli opcje jakie masz podczas odczytu danych.
Typy
PERMISSIVE: Jeśli atrybuty nie mogą zostać wczytane Spark zamienia je na nuleDROPMALFORMED: wiersze są usuwaneFAILFAST: proces odczytu zostaje całkowicie zatrzymany
// Opcja 1 dane odrzucone podczas walidacji schematu zostaną zapisane w osobnym folderze
val filewithschema = spark.read.format("json")
.option("schema",schema)
.option("badRecordsPath", "/mnt/source/badrecords")
.load("/mnt/source/shows.json")
//Opcja 2
val filewithschema = spark.read.format("json")
.option("schema",schema)
.option("mode", "PERMISSIVE")
.load("/mnt/source/shows.json")
//Opcja 3
val filewithschema = spark.read.format("json")
.option("schema",schema)
.option("mode", "DROPMALFORMED")
.load("/mnt/source/shows.json")
// Opcja 4
val filewithschema = spark.read.format("json")
.option("schema",schema)
.option("mode", "FAILFAST")
.load("/mnt/source/shows.json")
Sprawdzanie Nulls
Nulle są ważne i dobrze jest widzieć ile ich jest. Dzięki sprytowi Sparka można łatwo sprawdzić, czy Dataframe ma nulle i ile ich jest w poszczególnych kolumnach. Poniżej przykład
import org.apache.spark.sql.functions.{col, when, count}
val countNulls = df.select(file.columns.map(c => {count(when(col(c).isNull,c)).alias(c)}): _*)
display(countNulls)

Daj znać czy jest to przydatne i czy masz coś ciekawego na swojej liście?