
Domyślam się, że wielu z was chciałoby sprawdzić, jak działa ta magiczna technologia. I jest nadzieja dla wszystkich. Zupełnie za darmo jest dostępna platforma do Big Data, będąc bardzo precyzyjnym do Sparka. Zwie się ona Databricks Community Edition. https://community.cloud.databricks.com/login.html
Jest to bezpłatna wersja Databricks, czyli zestawu narzędzi do przetwarzania danych (Big Data). Zachęcam do otworzenia konta i zapoznania się z jej możliwościami. Oczywiście dodam na wstępie, że mamy do dyspozycji tylko podstawową funkcjonalność i jest dość okrojona. Więc proszę się nie rozczarować, gdy zobaczycie tylko cluster z jednym driverem. Będzie dostępne 6GB ramu i 10 GB dysku na dane. Wiem, może to się wydać za mało na prawdziwe Big Data. Cluster bez maszyn wykonawczych to jak laptop bez monitora :). Niemniej jednak masz dostęp do Sparka i środowiska wykonawczego Databricks. Dzięki temu możesz się sporo nauczyć. Będę starał się tego dowieść, ile tak naprawdę można się nauczyć, używając darmowego narzędzia.
Po założeniu konta wystarczy się zalogować już świat Big Data jest otwarty.
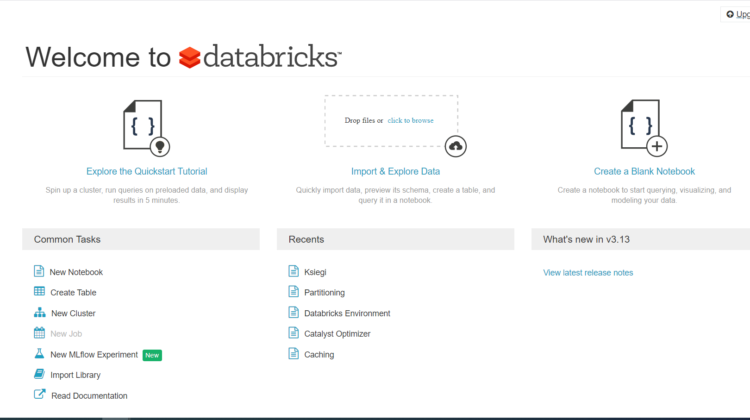
Po zalogowaniu zobaczysz taką stronę. Jest to miłe powitanie. I tego miejsca możemy już zacząć działać.
Wystarczą 3 proste kroki do rozpoczęcia tworzenia aplikacji w Sparku.
Krok 1 Tworzymy Klaster
Najważniejszy element ze wszystkich to oczywiście klaster, na którym możemy uruchamiać nasze aplikacje. Dobrze by było, jakby ktoś dołożył parę procesorów. Dzięki Databricks Community jest taka opcja. Po lewej stronie klikamy na “Clusters”. Pokaże się strona, na której stworzymy klaster.

W tym miejscu możemy stworzyć własny klaster. W porównaniu do pełnej wersji mamy tylko kilka opcji.
Wybieramy
- Nazwa kalstra
- Środowisko Wykonawcze: Tutaj jest kilka opcji, w zależności jaką wersję chcemy. Są dostępne najnowsze wersje beta i różne wersje Sparka i Scali. Daje to możliwość przetestowania najnowszych wersji.
- Region (Databricks używa AWS i mamy do wyboru 3 regiony)
I to wszystko co potrzeba do uruchomienia środowiska wykonawczego.

Po wybraniu naszych opcji klikasz na “Create Cluster” i już za kilka chwil działasz.
Krok 2 Dane
Kolejnym ważnym elementem jest dostęp do danych, a właściwie możliwość dodania danych do analizy. Tutaj musimy pamiętać że mamy ograniczenie – 10 GB.
Wybieramy ikonę “Data”

Potem wybieramy opcję “Add Data”

Tutaj wybieramy pliki i przekazujemy je do Databricksów.
“DBFS” tab daje Ci możliwość wglądu do wszystkich folderów jakie zostały stworzone oraz stworzenia tabeli.

“Create Table with UI” ta opcja daje możliwość wyboru klastra i stworzeniu tabeli używając interfejsu.
“Create Table in Notebook” ta opcja otwiera notebook, w którym są przykładowe skrypty, dzięki którym możemy stworzyć tabele.
Krok 3 Pierwszy notebook
Możemy wszystko stworzyć od podstaw lub wykorzystać gotowe notebooki. Jest ich mnóstwo. Systematycznie będę dodawał przykładowe notebooki do githuba. Na razie możesz się posiłkować gotowcem od Databricksów.
Klikamy na “Databricks” i tutaj mamy link “Explore Quickstart Tutiorial” do przykładowego szablonu, w którym są instrukcje jak korzystać z notebooka.
Ważnym elementem, którego będziemy często używać jest “Workspace” jest to główne miejsce służącym do nawigacji. W codziennej pracy tworzy się sporo notebooków i trzeba między nimi skakać.
Gorąco zachęcam do poznania i zabawy.