
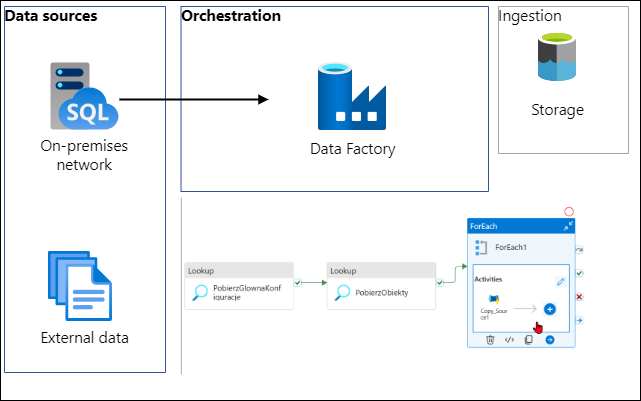
Jak to zwykle bywa na początku projektu zanim rozpoczniesz używać magiczną technologię Big Data to najpierw musisz jakoś te dane pobrać. A jak je pobrać używając narzędzi Azure? Najlepszym narzędziem jest Azure Data Factory czyli kombajn do wszystkiego. 😁 no dobra trochę przesadzam, ale to solidne narzędzie do orkiestracji pobierania danych i do tego działa.
Chciałem się tutaj skupić na najważniejszych elementach ADF, które warto mieć w skrzynce narzędziowej. Nie będę opisywał wszystkich możliwych opcji ponieważ jest ich za dużo, ale ten przykład możesz wykorzystać w swoim projekcie. Jest to wzorzec projektowy, który będzie pasował do części projektów, ale nie do wszystkich. Tutaj bądź sceptyczny i polegaj na swojej wiedzy i dogłębnej analizie, żeby potem nie płakać. 😄
W tym wzorcu projektowym najważniejsza jest jego konfigurowalność i dynamika. Jeden pipeline potrafi obsłużyć wiele źródeł i jest w pełni konfigurowalny. Wszystkie etapy są w pełni automatyczne i pobierają konfiguracje z jednego źródła. Zalety takiego rozwiązania to prostota, tanie i łatwe utrzymanie, oraz elastyczna konfigurowalność.
Konfiguracje
Możesz zbudować prosty pipeline bez konfiguracji, ale to jest mało efektywne. W realnym świecie będziesz potrzebował czegoś znacznie solidniejszego. Zakładam najgorsze, a tym samym, że masz mnóstwo źródeł. Gdzież musisz trzymać listę tabel, parametrów potrzebnych podczas ładowania. Najprostszym, a zarazem najsolidniejszym narzędziem jest relacyjna baza danych. Ilości danych do konfiguracji nie będą duże i to tego możesz je obudować w procedury co ułatwia utrzymanie. Zaletą procedur jest możliwość dodawania parametrów, a tym samym kontroli tego co jest pobierane. Takie rozwiązanie jest konfigurowalne i łatwo je rozszerzyć o nową funkcjonalność.
Najważniejsze będą dwie tabele jedna z listą konfiguracji potrzebnych dla potrzeb pipelina, poniżej przykład takiej tabeli
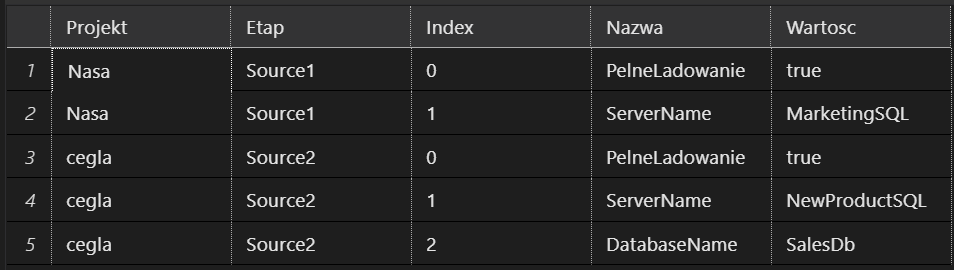
Druga z listą obiektów do pobrania, mogą to być tabele w systemach źródłowych bądź lista folderów ect.

Procedury
Jeśli użyjesz relacyjnej bazy danych to najlepszym interfejsem do komunikacji jest procedura. Do każdej tabeli potrzebujesz jedną procedurę do zapisu i jedną do odczytu danych. Całą bazę konfiguracyjną pakujesz w projekt SQL i będzie gotowa do deploymentu i propagacji do reszty środowisk w procesie CI/CD.
Druga procedura jest to odczytu konfiguracji i ona znajdzie się w ADF, to dzięki niej będziesz pobierał dane i kontrolował wszystkie procesy. Tą procedurę uruchomisz akcją Lookup przykłady poniżej.
Linked Services
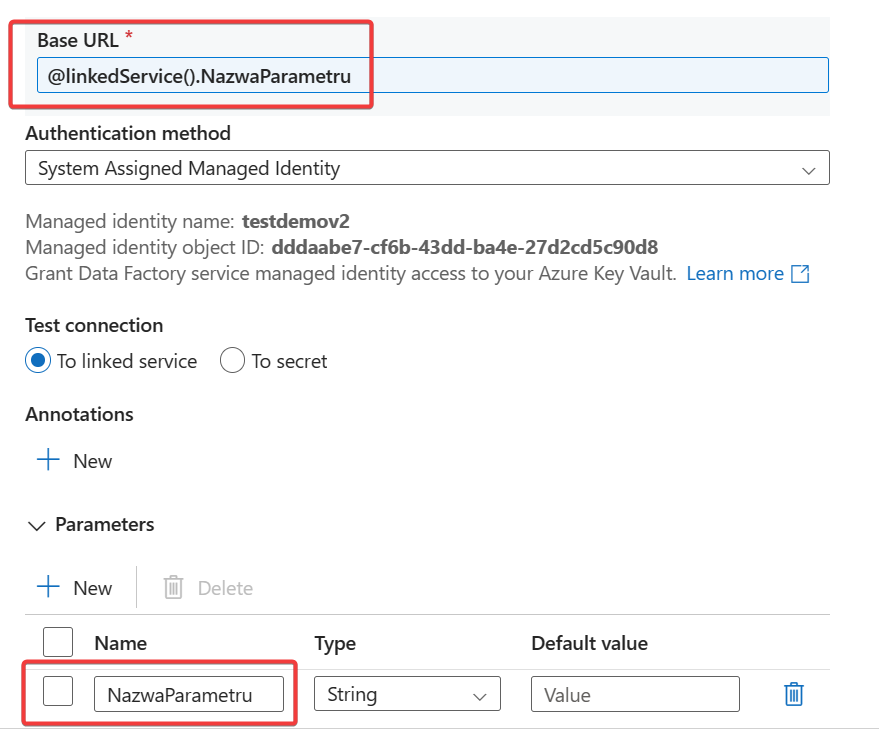
Tutaj dodam że wszystkie Linked Services powinny być sparametryzowane. tzn, że dynamicznie pobierasz ich konfiguracje z bazy, w której trzymasz wartości tych konfiguracji np. nazwa Key Vault, w którym trzymasz hasła. pochodzi z bazy a jej nazwa jest parametrem.
Key Vault
Najlepszym narzędziem do trzymania haseł i wszelkich wrażliwych informacji jest Key Vault. Możesz się do niego podłączyć i pobrać dane dynamicznie dzięki parametrom w Linked Service.
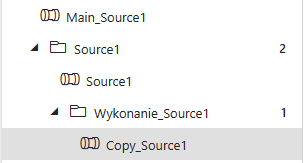
Struktura w ADF
Tutaj znajdziesz przykładową strukturę pipelienów w ADF. Są one ułożone hierarchicznie i każdy wywołuje kolejną warstwę zasilania. Nawet jeśli w tym samym źródle masz 100 tabel to wszystkie możesz je pobrać jednym pipelinem. Wiem to prawdziwa magia. 🌟
Main_Source ten pipeline może by wykorzystywany do kontroli pozostałych pipelinów (wielu źródeł), zakładam, że będziesz miał więcej źródeł niż 1 więc będziesz potrzebował czegoś co będzie kontrolowało resztę procesów. Pamiętaj jest to tylko wzorzec i możesz go modyfikować pod twój projekt. Cechą tego wzorca jest to, że jednym pipelinem wywołujesz drugi, na podstawie konfiguracji.
Folder Source1 jest stworzony pod konkretne źródło danych w tym przykładzie może to być np. baza danych on prem. Takich folderów możesz mieć więcej w zależności od ilości twoich systemów. Np. jeden do bazy a inny do plików.
Source1 to jest pierwszy pipeline kontrolujący konkretne źródło to on rozpoczyna proces. Tutaj zakładam, że będziesz pobierał więcej niż jedną tabelę więc potrzebujesz For Each Loop i przez to nie będziesz w stanie uruchomić całego zasilana z jednego pipelina ze względów na ograniczenia jakie narzuca ADF. Znacznie lepiej jest to rozłożyć na kilka i wywoływać hierarchicznie.
Główny
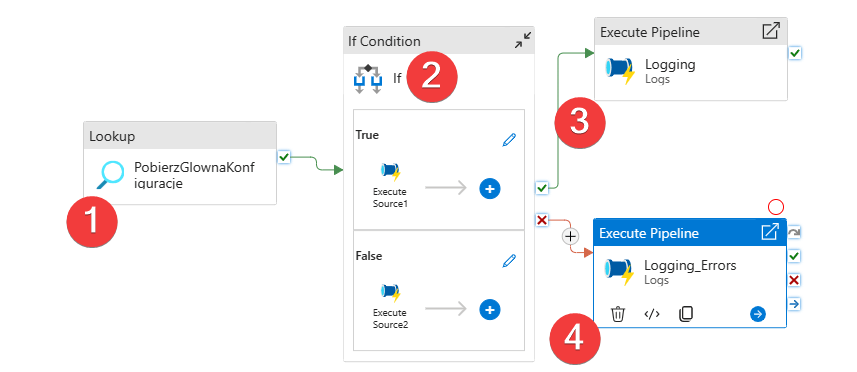
- W tej części pobieram konfiguracje, Akcja Lookup, która wywoła procedurę z odpowiednimi parametrami np nazwą projektu.
- Tutaj możesz dołożyć dodatkowe opcje w postaci akcji IF, w zależności od konfiguracji np pobrać dane całościowo lub inkrementalnie.
- Logujemy wydarzenia – tutaj osobny pipeline i zapis np. do bazy relacyjnej
- Logujemy awarie – ten pipeline może np wysyłać powiadomienia bądź jak w przypadku nr.3 zapisać parametry awarii do bazy w celu późniejszej analizy.

Source 1
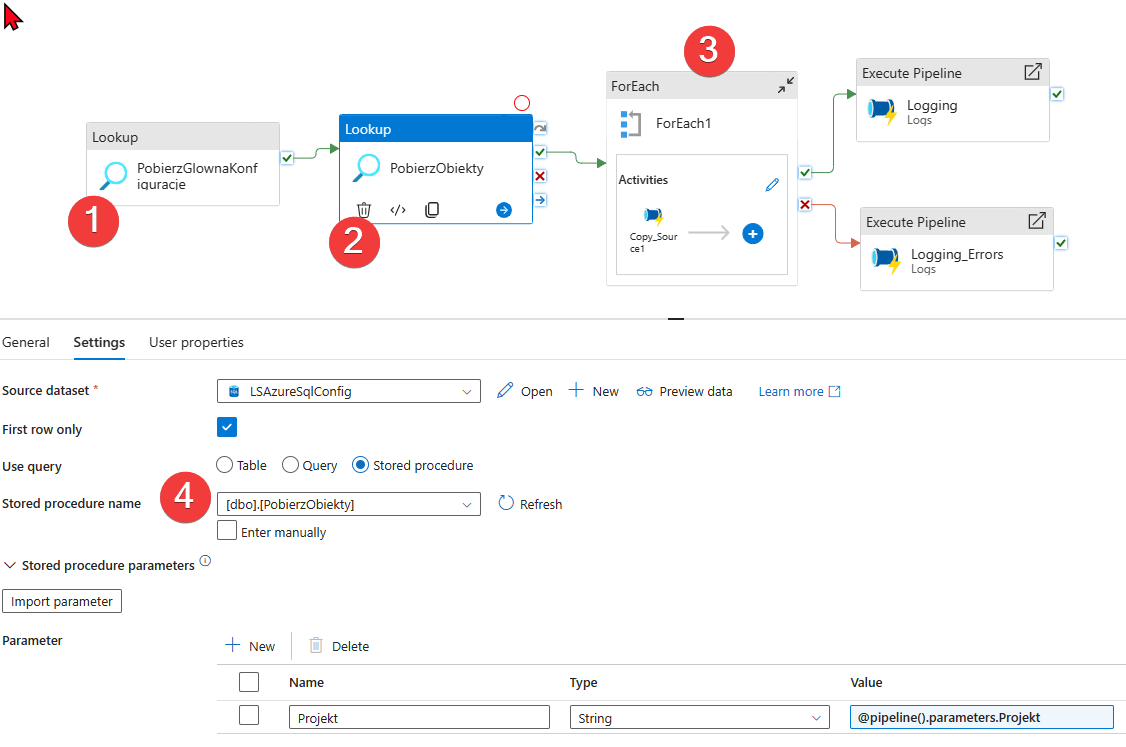
Jest to początkowy etap pobierania danego źródła. W tym wzorcu akcja ForEach wywoła pipeline, który będzie kopiował dane. Zanim jednak to zrobi potrzebuje trochę informacji.
- Pierwszy element Lookup tak jak w przypadku poprzednich pipelinów pobiera główną konfigurację (np. nazwa kv, bazy źródłowej ect.) oczywiście korzysta z procedury.
- Drugi lookup pobiera listę obiektów do pobrania, w moim przypadku jest to lista tabel.
- For Each wywoła już ostatni pipeline ten, który będzie kopiował indywidualne tabele lub pliki.
- Procedura dostarcza konfiguracje dla ADF
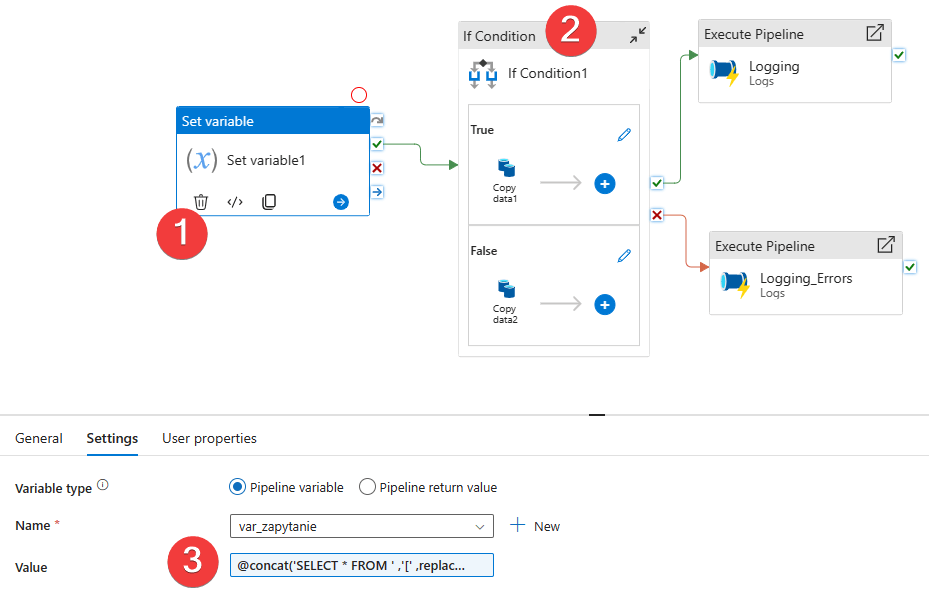
Kopiowanie
To już ostatni etap dla tego źródła, to właściwy pipeline, który będzie kopiował dane i ładował je do Azure Storage. Oczywiście w twoim wzorcu może to być inne miejsce docelowe.
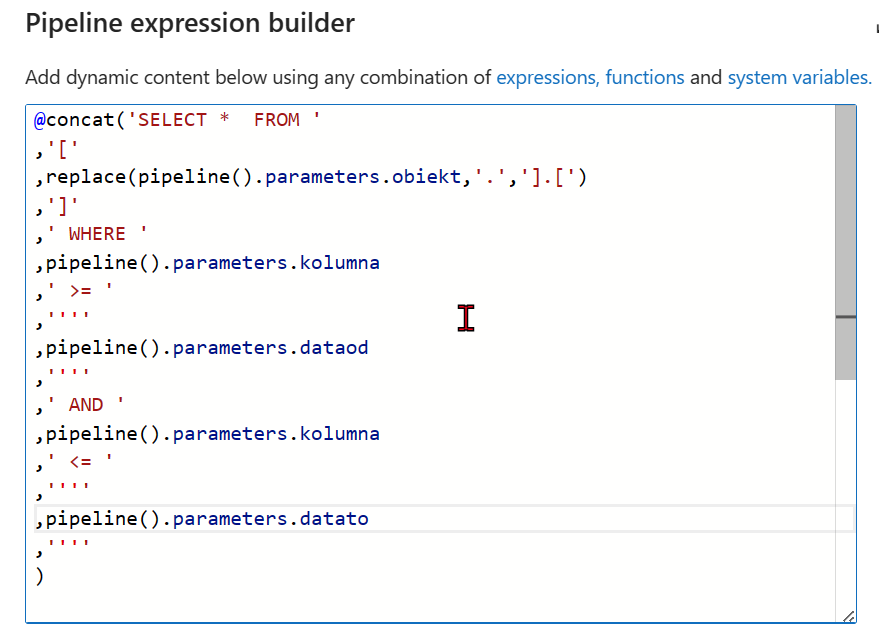
- Akcja Set Variable na podstawie otrzymanych konfiguracji dynamicznie stworzy zapytanie SQL. Dane do kwerendy pochodzą z poprzedniego kroku (pipelina). Najważniejsze jest to, że dla każdej tabeli zapytanie SQL jest tworzone dynamicznie. np. możesz zdefiniować osobną kolumnę dla każdej tabeli, która pobierze dane całościowo lub inkrementalnie na podstawie innej konfiguracji. W tym wzorcu każda tabela, do pobrania ma osobną konfigurację.
To tyle z tego wzorca projektowego. Mam nadzieję że z niego skorzystasz bo jest prosty, a zarazem daje mnóstwo kombinacji i elastyczności. Każdy element jest konfigurowalny i wszystko dzieje się dynamicznie.