
Pewnego pięknego dnia rozpoczął się sprint. Miałem bojowe zadanie do wykonania, mianowicie przekopiować trochę danych z jednego kontenera w blobie do drugiego. Żeby być precyzyjnym około 15 TB. Jest to już znacząca ilość danych i wymaga przemyślenia jak wykonać tę operację. Dane dotyczyły kilku źródeł danych, było ich 5. Każde z tych danych miały inną charakterystykę, trochę plików json i trochę tiff. Środowisko produkcyjne nie było gotowe, więc musiałem skopiować dane na deva, a potem na prod. Na szczęście sam proces działał na środowisku developerskim, więc miałem trochę luzu. 🙂 Musiałem wybrać odpowiednie narzędzia i skopiować dane. Jeśli chodzi o orkiestrację to Azure to Data Factory powinna być najlepsza, czy na pewno?
Problem
Zadanie może się wydawać błahe, ale są szczegóły, które sprawiają, że jego stopień trudności urósł. Wyobraź sobie, że masz dostęp do kontenera w blob storage. I jak do niego zajrzysz, to widzisz, że jest tam około 800,000 plików (fachowa terminologia blobów :)). A ile ja muszę skopiować ?
Odpowiedź na to pytanie jest w tabeli (blob table). I jak otwieram tabele, to widzę, że na liście jest tylko 280 000 plików. Do tego każdy rząd danych w tabeli jest meta-danymi.
Więc mam w tabeli listę plików do skopiowania i metadane dotyczące tych plików. Kolejna trudność to fakt, że każdy rządek danych w tabeli powinien towarzyszyć plikowi źródłowemu, bo to opisuje, co znajduję się w pliku. A więc mam mały problem skopiować 280 000 plików z kontenera, w którym jest 800 000 plików. Dodam, że jest to jednorazowe zadanie, docelowo będzie osobny mechanizm do kopiowania danych w pełni automatyczny. Jak narazie mogę robić wszystko półautomatycznie. Hmmm ? Od czego zacząć?
Pierwsze narzędzie, które nasuwa się na myśl jest Azure Data Factory. To przecież kombajn stworzony do mielenia danych. A więc zaczynamy.
Lista zadań
- Wyciągnąć meta dane z Azure Table.
- Zapisać meta dane z tabeli w docelowym kontenerze, gdzie każdy rząd danych z tabeli będzie plikiem json. Każdy nazwa pliku json znajduję się w metadanych.
- Skopiować pliki z danymi.
Narzędzie – Data Factory
Biorę się za Azure Data Factory i próbuję skopiować tabele, to akurat jest banalne zadanie, wystarczy jedna akcja i załatwione. Ale jak wyciągnę poszczególne rzędy i zamienię je w pliki json. No cóż takiej opcji w Azure Data Factory nie widzę.
Odpalam instancję i próbuję skopiować dane. W pipeline mogę tylko skopiować tabelę i nic więcej nie da się zrobić. To może Data Flow, – tutaj zonk bo Data Factory nie obsługuje tabeli. Przynajmniej jak na razie, pisząc to wiem, że na dzień dzisiejszy takiej funkcjonalności nie ma ale w każdej chwili może się zmienić. Zalecam regularnie sprawdzać dokumentację, żeby być na bieżąco. Widzę, że na tym etapie Data Factory nie daje rady co oznacza, że trzeba się wziąć za jakieś kodowanie.
Nie ma wyjścia, trzeba skryptować czyli jakoś to oprogramować. Tutaj najszybszym rozwiązaniem jest jakiś C#, PowerShell a może Python. W związku z tym, że miałem już parę skryptów w pythonie wybrałem tą opcję. Dodam, że zacząłem prace lokalnie bo z taką ilością metadanych laptop sobie poradzi. Inna kwestia to odpalenie tego rozwiązania na prodzie. Tutaj do kopiowania chyba wygra PowerShell, bo jest łatwy do odpalenia w Release Pipeline i pustej VMce (taka już jest tyle że nie ma w niej nic oprócz Windowsa). Pozostałem narzędzia typu C# czy Python wymagają odrobinę więcej pracy.
Buduję prototyp
Zacząłem pracę od ściągnięcia danych z tabeli najszybciej użyć Azure Data Explorer i ściągnąć je na dysk w postaci pliku csv. Nie mam dużo danych więc to nie będzie problem. Jak już mam csv to mogę zacząć się bawić z resztą. A więc mój wstępny proces wygląda następująco.
Przygotowanie metadanych
- Ściągnąć tabele do csv
- Wygenerować json z pliku csv (każdy rząd danych to jeden plik)
- Zapisz w blobie indywidualne pliki json ()
- Skopiuj dane źródłowe
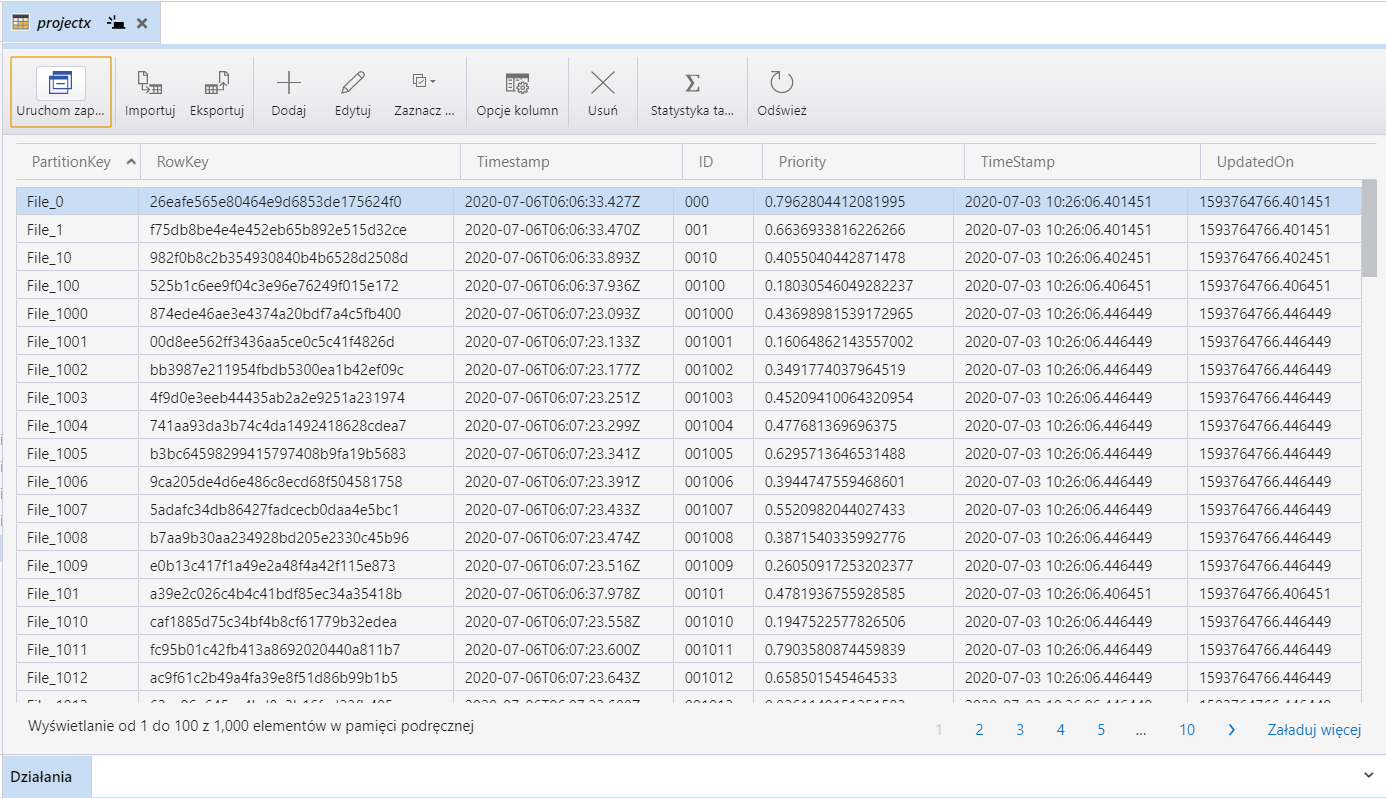
Tutaj kawałek kodu pythona do przetworzenia metadanych. Resztę znajdziesz w GitHub
import csv, json
csv_file_name = 'C:\\Users\\admin\\Downloads\\projectx2.csv'
json_file_name = 'C:\\Users\\admin\\Downloads\\meta.json'
json_data = {}
with open(csv_file_name,'r') as csvFile:
csvReader = csv.DictReader(csvFile)
field_names = ('PartitionKey','RowKey','TimeStamp','UpdatedOn','ID','Priority')
for row in csvReader:
# print(row)
FileName = row['RowKey']
json_data['PartitionKey']= row['PartitionKey']
json_data['RowKey'] = row['RowKey']
json_data['TimeStamp'] = row['TimeStamp']
json_data['UpdatedOn'] = row['UpdatedOn']
json_data['ID'] = row['ID']
json_data['Priority'] = row['Priority']
#json_data = row
with open('C:\\Users\\admin\\Downloads\\' + FileName +'.json','w') as jsonFile:
jsonFile.write(json.dumps(json_data,indent=4))
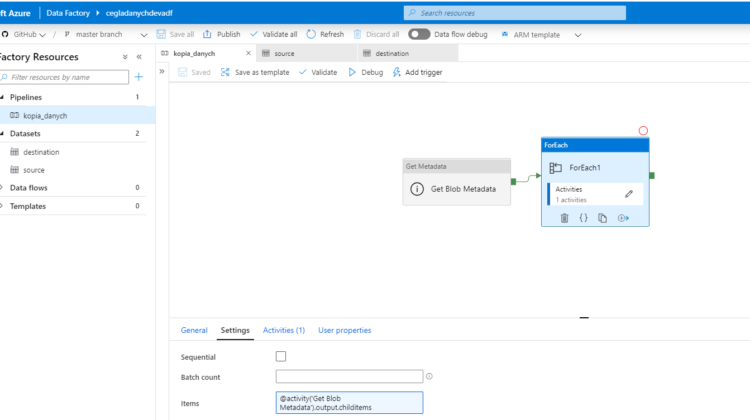
Po odpaleniu danych mam już wszystkie pliki json czyli metadane w kontenerze. to połowa sukcesu. Meta dane już są więc czas na dane. Wracam do Data Factory i sprawdzam czy da się skopiować tylko te pliki, które mam w kontenerze. Wymyśliłem takie rozwiązanie.
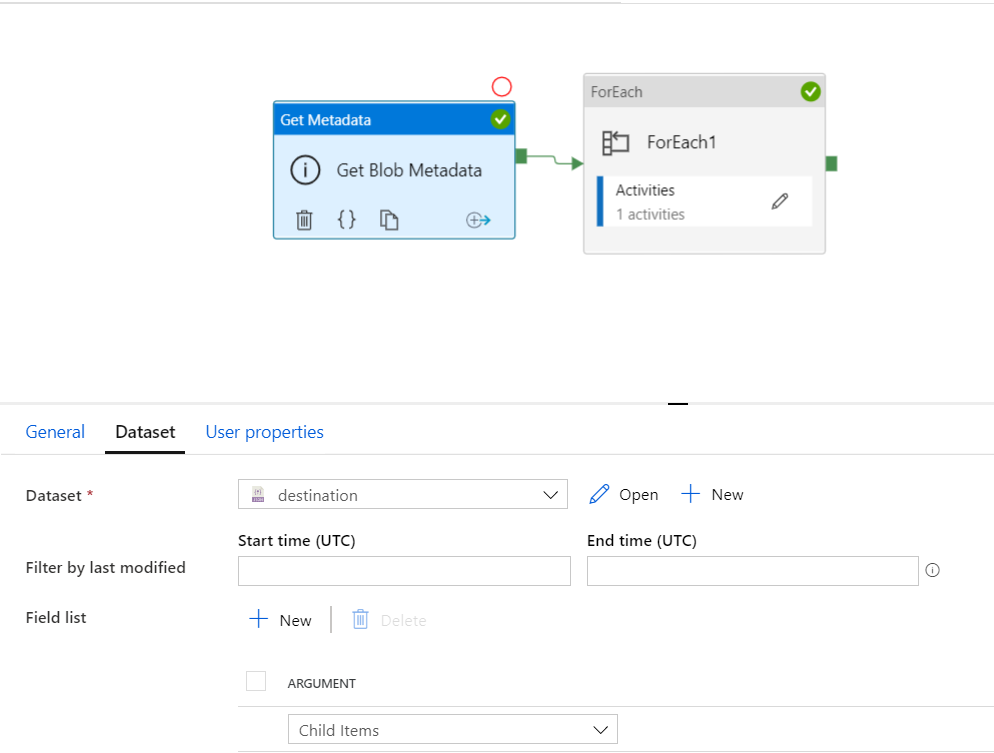
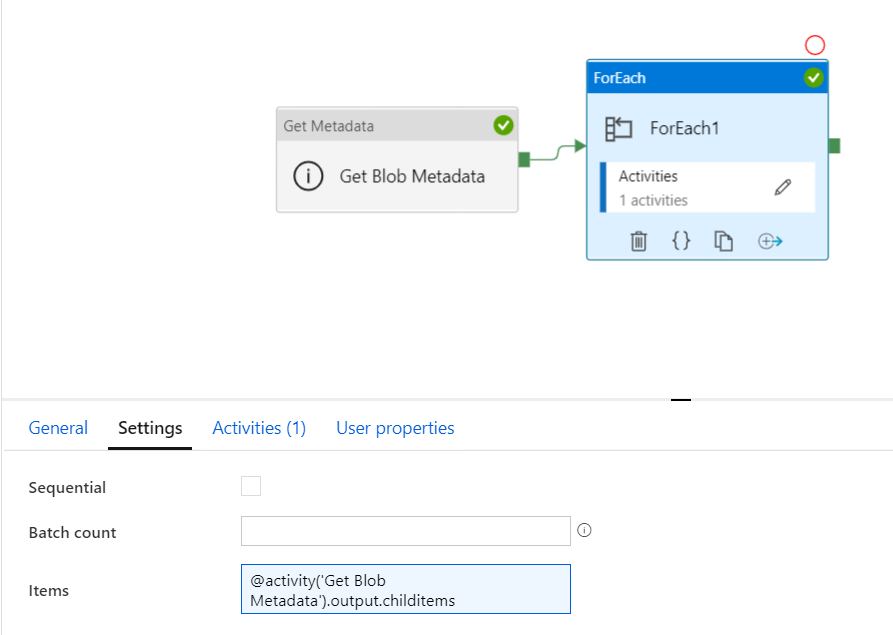
Jeżeli ustawię metadata w pipeline to będę miał listę wszystkich plików, a konkretnie ich nazwy. Potem odpalę Foreach i dynamicznie przekaże nazwy do akcji Copy. Dzięki temu będę mógł skopiować tylko te pliki, które mnie interesują. Cały czas mam w głowie problem z kopiowaniem tylko wybranych plików ze źródła a nie całego kontenera. Czy mogę już świętować ? Na pierwszy rzut oka tak rozwiązanie działa, mam pliki meta czyli sukces. No nie całkiem.
Pierwszy set przeszedł bez problemu ale tam było około 50 000 plików. Co z następnym ?
Tutaj pojawia się kolejny problem, Azure Data Factory odmawia posłuszeństwa i pokazuje błąd;
{
"errorCode": "2001",
"message": "The length of execution output is over limit (around 4MB currently)",
"failureType": "UserError",
"target": "Get Blob Metadata",
"details": []
}
Data Factory ograniczenia
Wynika z tego, że Data Factory ma ograniczenia, a przynajmniej akcja ’metadata’. Jak czytam w dokumentacji to widzę, że jest limit 2MB (Trochę odbiega od tego co widzę w ADF). Metadata to prosta pętla, która tworzy json z listą nazw plików/folderów i tam mogę tylko pomieścić określoną ilość danych. Niestety moje rozwiązanie nie zadziała. Tutaj ważna lekcja Data Factory pipeline nie jest stworzone do pracy na pojedynczych plikach. Nie w takich ilościach jak bym chciał. Do tego dochodzą koszty jak sobie policzyłem to użycie tego rozwiązanie kosztowałoby około 8 000 zl dla wszystkich zbiorów danych. Tutaj polecam ciekawe video o Data Factory i kontroli kosztów.
Co mogę zrobić, żeby rozwiązać ten problem? Najprostszym i tanim rozwiązaniem jest azcopy. Jest to narzędzie typu 'CLI’ czyli uruchamiane z komendy. Dla mnie bomba bo mogę go uruchomić w mojej 'pustej’ VMce z użyciem PowerShella i sprawa rozwiązana.
$sourceuri = ""
$destinationuri = ""
$sourcesas = ""
$destinationsas = ""
$source = "$sourceuri$sourcesas"
$destination = "$destinationuri$destinationsas"
$csvpath = 'C:\Users\admin\Downloads\projectx2.csv'
$csvobject = Import-CSV $csvpath
#Czytamy plik csv
$csvheader = (Get-Content $csvpath | Select-Object -First 1)
$delimeter = ",";
$columnheader = $csvheader -Split $delimeter
foreach($item in $csvobject)
{
$filename = "$($item.$($columnheader[1]))$.tiff"
$source = "$sourceuri$filename$sourcesas"
$destination = "$destinationuri$filename$destinationsas"
& ".\azcopy.exe" cp "$source" "$destination" --recursive=TRUE
Write-Host "File name = $filename"
}
Podsumowanie
Zadanie zrobione można świętować. Problem w miarę błahy ale na pewno często spotykany. Mam nadzieję, że to Ci pomoże i zasugeruje podobne rozwiązanie.
Chciałem pokreślić, że opisany problem nie jest wadą Azure Data Factory. Trzeba pamiętać, że każde narzędzie ma swoje słabe i mocne strony. Sprawdź w czym dane narzędzie jest najlepsze i na tym się skup. Azure Data Factory nie jest narzędziem do zarządzania pojedynczymi plikami, przynajmniej to tego problemu, który opisałem. Przynajmniej jak na razie, pamiętajmy, że Data Factory cały czas się ulepsza i rozwija. To że możemy to zrobić nie oznacza że powinniśmy. Złe użycie narzędzia będzie nie efektywne i bardzo kosztowne. Daj mi znać czy miałeś podobny problem i jak go rozwiązałeś?