
| W tym wydaniu: Autoloader Unity CatalogDaft vs Spark Architektura medalionu |
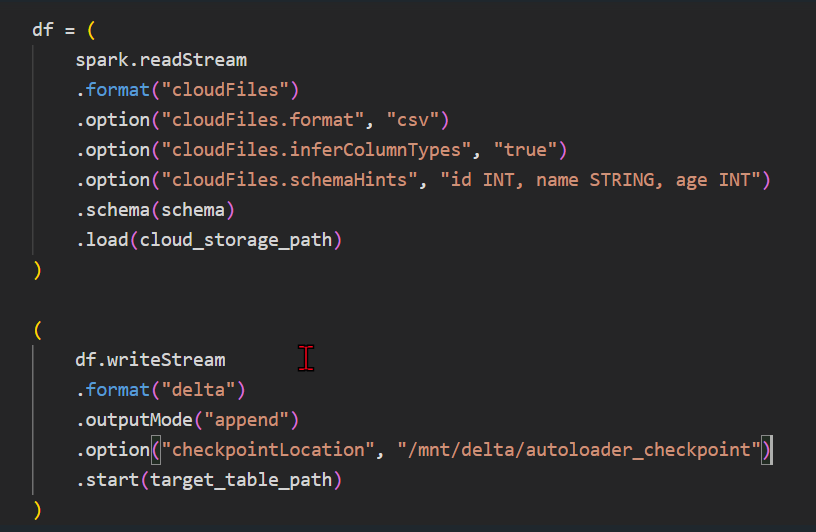
| DATABRICKS UNITY CATALOG Jeśli pracujesz w Databricks i nie masz jeszcze Unity Catalog to zapewne będziesz mieć. Ze względu na ułatwione zarządzanie dostępami co raz więcej firm będzie migrowało do Unity Catalog. Warto się z tym zapoznać i przygotować do ewentualnej migracji. Jedną z opcji jest stworzenie osobnej subskrypcji i modyfikacja kodu który będzie zapisywał dane do tabel zarządzanych przez Unity Catalog. Najważniejszą zmianą jaką musisz zrobić przy migracji jest zmiana ścieżek, najczęściej zapisujesz dane do folderów /mnt lub /abfss…a w Unity Catalog będziesz mieć .. Jeśli chcesz to potestować na boku to musisz mieć swoja subskrypcję, być adminem i mieć premium workspace. What is Unity Catalog Enabling Unity Catalog on Azure Databricks: A Step-by-Step Guide |
| DAFT VS SPARK Niedawno wspominałem o Polars, nowy szybki framework do inżynierii danych. Teraz pojawił się nowy bajer, zwie się Daft. Poniżej link to artykułu gdzie autor chce sprawdzić, czy można zamienić PySpark na Daft w środowisku Databricks. Okazuje się, że po instalacji Daft na klastrze Databricks i połączeniu go z Unity Catalog, można go użyć do odczytu tabel Delta. Jednak pojawiają się problemy z autoryzacją i odczytem tabeli, które wymagają rozwiązania. Po ich rozwiązaniu, Daft zdołał odczytać tabelę Delta z 21 milionami wierszy i przeprowadzić agregację danych szybciej niż PySpark. Jak się to sprawdzi na produkcji tego nie wiem, ale warto wiedzieć że są takie narzędzia. Introduction to Daft ( … vs Polars)Daft vs Spark (Databricks) for Delta Tables (Unity Catalog) |
| ARCHITEKTURA MEDALIONU Obecnie jest duża moda na tworzenie Lakehouse opartej na kilku warstwach. Surowe dane wchodzą z jednej strony do Raw i są przetwarzane w kilku etapach (bronze, silver, gold). Po wszystkich etapach są już pięknie oczyszczone i gotowe do konsumpcji. Taki podział na kilka warstw jest bardzo rozsądny ponieważ daje ci możliwość rozbicia skomplikowanych operacji na kilka etapów. Oczywiście co dzieje się w każdej warstwie zależy od ich ilości i podejścia danej organizacji. Jak już wspominam o tradycji to jeszcze nie tak dawno temu stawiałem hurtownie danych w klasycznym SQL Server. Tam bardzo popularny jest Star Schema, czyli gwiazda. Tutaj mam dobre wieści da się zrobić gwiazdę w Databricks. What goes into bronze, silver, and gold layers of a medallion data architectureFive Simple Steps for Implementing a Star Schema in Databricks With Delta Lake |