
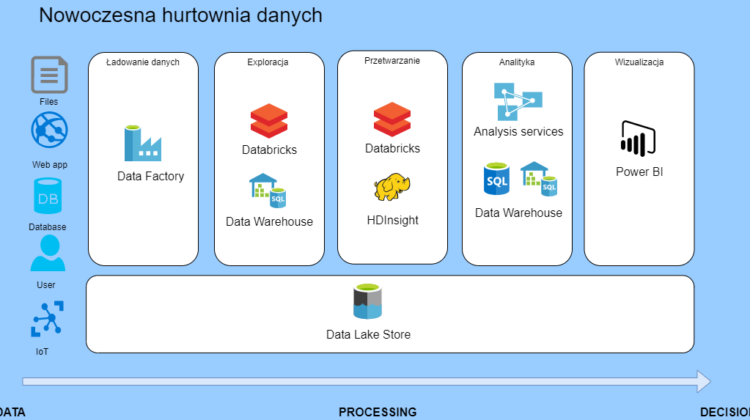
Model hurtowni danych
Chciałbym się podzielić notatkami o tworzeniu super nowoczesnej hurtowni danych, jaką możemy postawić w Azure. Jest to model architektury promowany przez Microsoft, jest on prosty we wdrożeniu i utrzymaniu. Dzięki jego prostocie taką hurtownię danych będziesz mógł go łatwo sprzedać biznesowi i szybko dostarczyć dużo wartości dla firmy.
Trzeba pamiętać o tym, że jest to generyczne rozwiązanie, które rozwiąże wiele problemów. W niejednej firmę sprawdzi się na medal, ale na pewno nie będzie pasowało do każdego problemu. Więc potraktuj go jako szablon, który można zmodyfikować do własnych potrzeb.
Grupowanie danych
Dane można podzielić na kategorie, w zależności od fazy w jakiej się znajdują.
- Brązowy: czyste nieprzetworzone dane
- Srebrny: trochę zwalidowane przetworzone, dla analytików
- Złoty: fact and dimention czyli dane produkcyjne
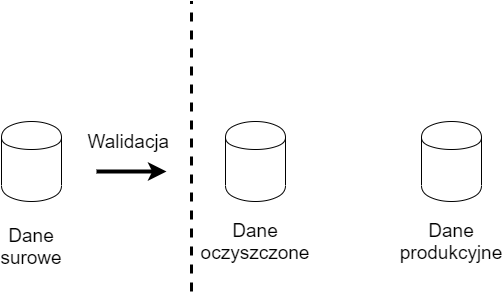
Zacznij od jakości, już na początku trzeba sprawdzać dane. Nie dopuść by dane kiepskiej jakości dostały się hurtowni danych.
Kiedy dane przepływają przez system, każdy element transformacji musi być zdolny do przeładowania danych. To znaczy, kiedy wystąpi błąd, system musi sobie z tym poradzić. I tutaj wkracza mechanizm ‘replay’ czyli uruchamia proces jeszcze raz i odtwarza stan danych, jaki był przed błędem.
DevOps
To bardzo ważny element Azure, bez niego proces CI i CD byłby bardzo trudny. Zachęcam do zapoznania się z jego możliwościami. Link do dokumentacji.
Databricks
Jeśli chodzi o Sparka, to tworząc rozwiązanie do Databricksów, trzeba starać się tworzyć biblioteki. Na co dzień pracę można rozpocząć w notebookach i są one świetne to rozpoczęcia pracy i prototypownia. Gdy trzeba, solidne rozwiązanie to pomyśl o bibliotece, w którą można wzbogacić o testy i łatwiej ją deployować i kontrolować. Świetna praktyką jest CI i CD. Taką bibliotekę budujemy i wrzucamy do DevOps Artifact. Stamtąd możemy ją wrzucić do klastra Spark. Zachęcam do zapoznania się Databricks Community Edition, jest to darmowa wersja do celów szkoleniowych.
Składowanie surowych danych
Tutaj koncentrujemy się na Data Lake, które pozwala na składowanie dużych ilości danych. Ta usługa jest przystosowana do przetrzymywania dużych ilości danych i analizy w narzędziach Big Data oraz hurtowniach danych.
Mechanism integracji / wstrzykiwania danych

Jeśli chodzi o ładowanie danych to, tutaj najlepszym rozwiązaniem jest Data Factory. Jest to tak ważne narzędzie, że trzeba go opisać osobno.
Eksploracja i danych
Tutaj mamy dostępne dwa solidne narzędzia Databricks i Synapse – SQL DW. Oba nadają się świetnie do eksploracji danych i ich przetwarzania. Databricks jest narzędziem Big Data tutaj możemy działać, używając Sparka. SQL DW jest, bazą danych i tutaj będzie dominował język SQL. Możemy użyć R. W obu przypadkach są dostępne narzędzia ML.
Przetwarzanie
Oprócz Databricksów dodatkowym narzędziem w Azure które pozwala na przetwarzanie danych w stylu Big Data jest HDInsight. Tutaj oprócz Sparka jest dostępny ekosystem Hadoop.
Analityka

Jak już przetworzysz dane i będą w świetnej formie trzeba zabrać się za analitykę i przygotowanie danych do wizualizacji. Dane często są uproszczone, najczęściej jest to jakaś agregacja pokazująca dane dla jakiegoś konkretnego wymiaru, np. dzienna sprzedaż pogrupowana według lokalizacji.
Tutaj oprócz Analysis Services możemy użyć narzędzia SQL Server.
Wizualizacja
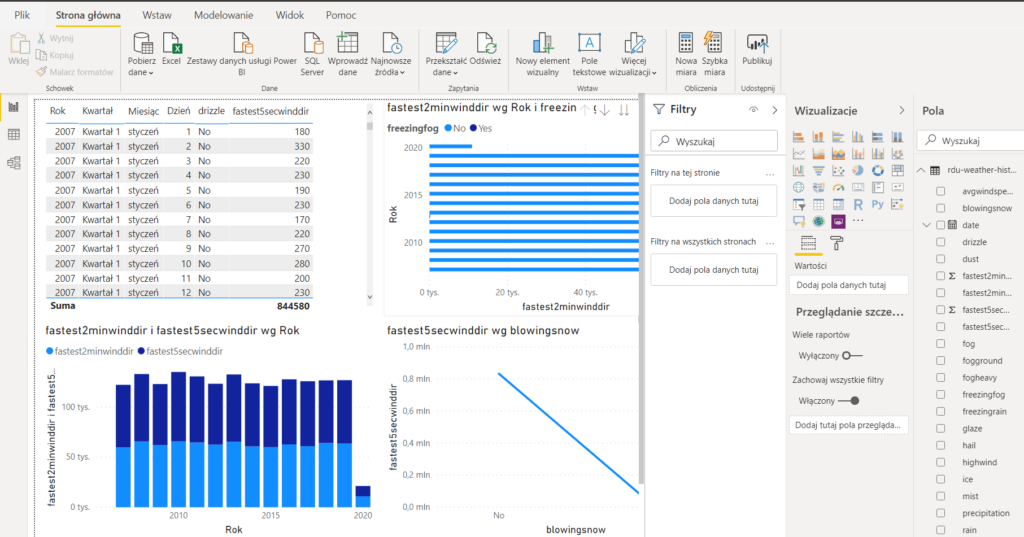
Jak już wszystko jest ładnie poukładane to czas na ładne wykresy dla naszych klientów.
Monitoring
Tutaj Azure daje nam App Insights.
Zachęcam do obejrzenia filmu bardzo ciekawa prezentacja Lace Lofranco i zapoznanie się z repo.
Link do rozwiązania