
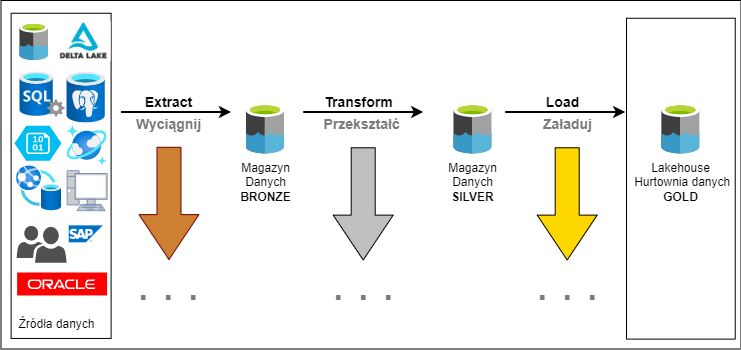
Na pewno nie raz spotkałeś się z terminem ETL. Jest to akronim, jak się domyślasz pochodzi z angielskiego Extract Transform and Load. Jest to najpopularniejszy na świecie proces przetwarzania danych. Przetłumaczone na polski Wyciągnij, Przekształć i Załaduj. To wieloetapowy proces przetwarzania danych. Stosuje się go, kiedy organizacja chce stworzyć centralne repozytorium danych. Każdy z tych kluczowych faz można podzielić na mniejsze już bardziej wyspecjalizowane.
Proces ETL
Jest to wieloetapowy proces polegający na wykonywaniu konkretnych typów operacji przetwarzania danych. Każdy etap ma swoje specyficzne wymagania. Inżynier danych jest osobą odpowiedzialną za tworzenie i utrzymanie procesu ETL. Poszczególne fazy są opisane poniżej. Dodam, że są to główne elementy procesu. Każda z tych faz może być podzielona na wiele wyspecjalizowanych etapów.
Extract – Wyciąganie danych
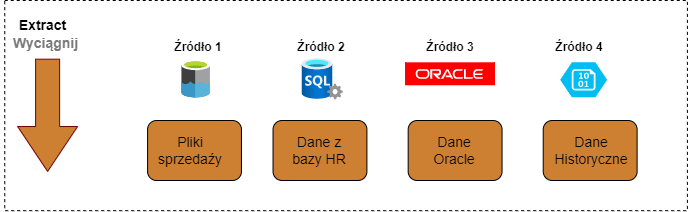
Extract – jest to pierwszy etap, w którym dane są pobierane ze źródła. Źródłem danych mogą być różne systemy informatyczne, pliki, bazy danych, użytkownicy. Pierwszym etapem jest sprawdzenie, czy w źródle pojawiły się nowe dane. Twój pipeline musi zapewnić, aby dane zostały załadowane do magazynu tylko raz. Nie możesz dopuścić do pojawienia się duplikatów. Jeśli pobierasz dane z plików, to musisz upewnić się, że proces przeładuje każdy plik tylko raz. Jeśli pracujesz w chmurze, to zadanie jest ułatwione, ponieważ są tam narzędzia zapewniające jednorazowe przetwarzanie plików. Taka funkcjonalność jest dostępna w Azure Data Factory lub Databricks Autoloader.
Jeśli działasz on-premise bądź nie masz dostępu do wymaganych narzędzi, to musisz gdzieś zapisać nazwę pliku i podczas ładowania sprawdzić, czy już go nie wczytałeś. Inną metodą jest skopiowanie plików już przetworzonych do innej lokalizacji, tak aby nowe pliki nie zostały pomieszane ze starymi. Pamiętaj o sprawdzeniu dokumentacji źródła, żeby poznać jego charakterystykę. Pamiętaj każdy system działa inaczej i musisz dobrze poznać dane.
Metody wyciągania danych.
Są dwie najczęściej spotykane metody pobierania danych w procesie ETL.
- Metoda ’Pull’ – dane są aktywnie pobierane przez system zarządzający ETL. Po jego stronie możesz ustawić harmonogram, który wykona operację kopiowania danych np. codziennie o 23.30
- Metoda ’Push’ – w której to system źródłowy aktywnie wysyła dane to systemu ETL. Np. może to być wysyłka plików, bądź wiadomość wywołująca proces ETL.
Każda z nich powinna być dobrana indywidulanie w zależności od tego, jak działa system źródłowy. Najczęściej dostosowuje się proces ETL do źródła danych. Pamiętaj, że każdy pipeline może działać inaczej w zależności od wymagań.
Transform – Przekształcanie danych
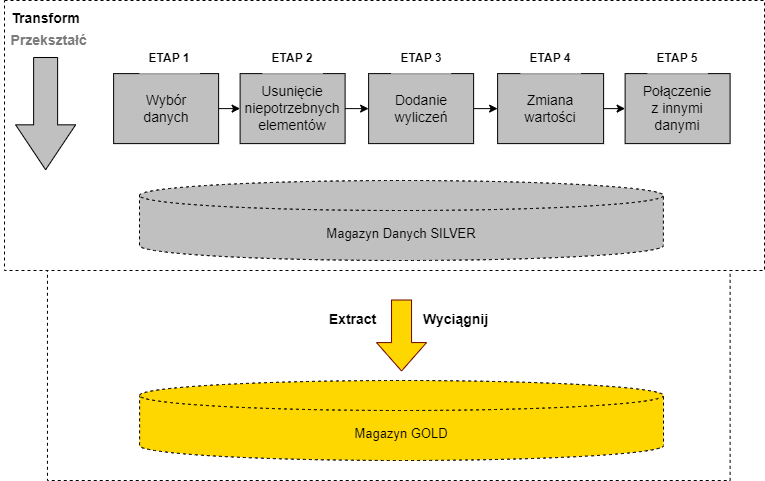
Transform – drugi i najbardziej skomplikowany etap, czyli przekształcenie danych. Bardzo często dane są słabej jakości i nie nadają się do użycia w „stanie surowym”. W tym etapie transformacje mogą dotyczyć oczyszczania danych, naprawiania, łączenia danych z innych źródeł.
Transformacje najczęściej dotyczą oczyszczania danych lub ich uzdatnienia. Dane pochodzące z różnych systemów bardzo często mają braki. W pojedynczych polach może brakować pewnych wartości bądź są one niepoprawne.
W tej fazie inżynier danych programuje wszelkie reguły firmy wymagane do przygotowanie danych pod zadania analityczne.
Schemat danych
Ważne jest, aby dane z każdego źródła spełniały wymagania jakości. Tutaj ważny jest schemat danych – jest to definicja metadanych opisująca każdy element z danego zbioru. Jednym z podstawowych elementów schematu danych są nazwy poszczególnych pól oraz ich typy. Poniżej przykład schematu w formacie json. Pozwala on na automatyczne wykrycie błędów w plikach. Każde pole danych ma swoją nazwę oraz typ danych, integer, long. string. Dzięki takiej definicji będę w stanie sprawdzić, czy każde pole z danymi spełnia wymagania. Np. czy nazwa produktu jest typem string i czy są w nim dane. Sprawdzanie schematu danych w procesie ETL jest bardzo ważne.
{
"$schema": "http://json-schema.org/draft-04/schema#",
"title": "Product",
"description": "Jakiś produkt z jakiegoś katalogu",
"type": "object",
"properties": {
"id": {
"description": "Unikalny numer produktu",
"type": "integer"
},
"name": {
"description": "Nazwa produktu",
"type": "string"
},
"price": {
"description": "Cena produktu",
"type": "number",
"minimum": 0,
"exclusiveMinimum": true
}
},
"required": ["id", "name", "price"]
}
Łączenie danych
Celem procesu ETL jest stworzenie centralnego repozytorium danych. Może on przyjąć, postać Hurtowni Danych, Lakehouse czy Data Lake. Oznacza to, że dane z każdego systemu powinny zostać odpowiednio połączone w jeden wspólny model danych. Dzięki dobrze stworzonemu modelowi będzie można łatwo wyciągnąć wszystkie informacje. O modelu danych piszę w ostatnim akapicie, tutaj dodam, że są to relacje pomiędzy poszczególnymi zestawami danymi.
Jak się domyślasz dane z poszczególnych źródeł są od siebie odizolowane. Każde w innym systemie i rozrzucone na kilkadziesiąt tabel. Analiza danych takiego formatu jest bardzo trudna i nieefektywna. Rozwiązaniem jest łączenie danych podczas transformacji. Dzięki temu wypłaszacza się struktura danych i model danych zawiera wszystkie ważne dane w jednym miejscu.
Wymagania firmy
Żeby dane można było wykorzystać w analizie, należy wprowadzić specyficzne reguły firmy. Poszczególne systemy źródłowe mogą nie mieć zaprogramowanych wszystkich reguł biznesu. Etap transformacji jest dobrym miejscem, gdzie możesz dodać wymagane zależności biznesowe. Tutaj ważne jest, aby dobrze poznać dokumentację bądź mieć świetną komunikację z osobą, która zna się na danych. Najczęściej, kiedy pracujesz w projekcie oprócz analityka biznesowego, powinieneś mieć dostęp do SME (czyli Subject Matter Expert) Jest osoba po stronie firmy znająca się na danych oraz na konkretnym systemie. Dzięki dobrym kontaktom będziesz mógł wprowadzić niezbędne wymagania biznesu.
Load – Ładowanie danych
Load – ostatni etap. Po wykonaniu wszystkich transformacji dane są już sprawdzone i wyczyszczone. Ta faza powinna być w miarę lekka. Tutaj najważniejsze to zapisanie danych. W zależności od tego jaki model, a raczej jaki magazyn danych wybrałeś, pozostaje zapisać bądź dodać dane do wybranej struktury. Może to być prosta operacja jak 'append’ do plików. Świetne są pliki parquet, dla tych, co ich nie znają, polecam się zapoznać, są tego warte. W innym scenariuszu może to być zapis do bazy danych.
Jakość danych
Nie muszę chyba podkreślać, jak ważna jest jest jakość danych. Jednym z kluczy do sukcesu firmy są dane, a raczej umiejętność wyciągnięcia z nich wartości. Dobre decyzje podejmuje osoba najlepiej poinformowana o tym, co dzieje się w firmie i poza nią. Więc dane muszą być najwyższej jakości.
Jak to osiągnąć. Najlepiej dobrze zaprojektować proces ETL i wszystkie jego etapy. Następnie go zautomatyzować i solidnie przetestować.
Powinieneś dobrze przemyśleć każdy element procesu. Tutaj wkracza architektura, dobrze dobrane narzędzia i nastawione na konkretne etapy procesu.
Od początku automatyzujemy pipeliny ETL. Każdy element począwszy od wykrycia danych, aż po ładowanie czy zarządzanie logami powinien być automatyczny. W razie błędów system powinien wysłać powiadomienia do inżynierów odpowiedzialnych za proces ETL.
Dzięki automatyzacji wszystkie etapy są sprawdzane pod kątem jakości danych. Zawsze powinieneś sprawdzić schemat danych. Jest to podstawowa operacji podczas odczytu i potwierdzi czy dane pasują do tego, co jest w wymaganiach. Jeśli wykryjesz błędy, to trzeba je jakoś obsłużyć. Jedną z metod jest przesłanie błędnych danych do osobnego folderu, który jest monitorowany. Taka kwarantanna dla chorych danych. Tutaj w zależności od usterki dobieramy metodę i naprawiamy dane, jeśli się da. Może się zdarzyć, że błąd jest po stronie systemu źródłowego, a wtedy powinieneś to eskalować do odpowiedniego zespołu.
Logi i monitorowanie
Jak już tak automatyzujemy i sprawdzamy dane firmy, to warto by było gdzieś zapisać informację o błędach oraz o samym procesie. Skoro pracujesz z procesem wieloetapowym, to warto wiedzieć jak działa każdy etap. Ile danych było na wejściu, a ile na wyjściu? Ile było błędów?
Logi powinny ułatwić monitorowanie procesu ETL lub każdego innego systemu. Kod źródłowy powinien obsługiwać logi i wyłapywać ważne błędy.
Dzięki temu będziesz w stanie monitorować cały proces i wszystko, co się w nim dzieje.
Alternatywa ELT
Pomimo wielu zalet przetwarzanie ETL ma pewne wady i jest na to alternatywny proces ELT. Extract Load Transform, wyciągnij, załaduj i potem przekształć. Zmiana może się wydawać nie wielka, ale ma kolosalne znaczenie w codziennym życiu. Jak widzisz zamieniono kolejność elementów procesu.
W tym modelu najpierw ładujesz dane, a następnie je przetwarzasz. Wbrew pozorom ma to swoje zalety. Dzięki coraz lepszym narzędziom i frameworkom nie trzeba za każdym razem wykonywać transformacji. Coraz częściej dane są ustrukturyzowane w całości lub częściowo i to wystarczy, żeby można je było obrabiać. Kiedyś inżynier musiał przetworzyć i przygotować dane tak, aby je przechować w relacyjnej bazie danych. Relacyjna baza danych wymaga pewnej struktury danych, niezbędnej do analizy.
Nowoczesne narzędzia szczególnie te dostępne w chmurze potrafią obrabiać dane surowe dostępne w plikach. Można wykonywać analizę na danych w plikach tekstowych. Jeśli chcesz wykonać jakąś transformację, to możesz to zrobić w warstwie analitycznej. Zamiast tworzyć skomplikowany model, to wystarczy kilka zmian kodu.
Można użyć warstwy magazynu zwanego Data Lake. Są to ustrukturyzowane pliki np json, avro czy parquet. Coraz częściej dane w systemach źródłowych są na tyle dobrej jakości, że nie trzeba spędzać dużo czasu na ich oczyszczaniu i przygotowaniu. Są gotowe go użycia zaraz po załadowaniu. W Data Lake ważne jest aby dobrze stworzyć strukturę folderów. Dzięki temu analitycy będą mieli ułatwioną pracę.
Narzędzia ETL
W zależności od całej masy czynników jest do wyboru cała masa narzędzi. Tym zdaniem raczej nie pomogłem, ale of czegoś trzeba zacząć.😁
Nie chcę w chodzić w listę 50 narzędzi dostępnych, ale skupię się na tych, które znam. Najszybszy podział narzędzi to na te on-premise i w chmurze.
On-premise
Jeśli chodzi o piwniczkę wypełnioną serwerami, to najlepszym narzędziem do budowanie hurtowni danych jest SQL Server (wiem jestem stronniczy). W połączeniu z zestawem narzędzi do ładowania i przetwarzania danych. Jest to kombajn, który dostarczy cały pakiet i można tworzyć procesy ETL jakimi NASA by się nie powstydziło. SQL Server i SSIS mogę polecić bez wahania i bez afiliacji. Będzie działało.
Pamiętaj szukasz nie tyle narzędzia ale całego frameworku, kombajnu do integracji danych z wielu źródeł. Ma wspierać całą masę konektorów, i mieć możliwość programowania dla bardziej wymagających reguł. Przykładowa lista narzędzi do integracji.
Azure Cloud
Tutaj zaczynają się schody, ponieważ narzędzi jest znacznie więcej ale postaram się wyliczyć te najważniejsze, które spełnią najbardziej wygórowane wymagania.
Jeśli twój proces ETL jest bardzo skomplikowany i masz duże ilości danych to jest kilka narzędzi w Azure godnych polecenia.
Data Lake Gen2
Ta usługa służy do przechowywania danych. Kiedy tworzysz klasyczny blob store, to musisz wybrać ’hierarchical namespace’. Dzięki temu będziesz mógł tworzyć strukturę folderów. Jest ona stworzona do przetrzymywania danych w plikach oraz pod szeroko pojętą analitykę. Taki magazyn pomieści Peta bajty danych we wszelakich formatach.
Data Factory
Służy do orkiestracji i automatyzacji zadań związanych z przepływem danych. Jeśli chcesz integrować dane z wielu źródeł nie tylko z Azure, ale również on-premis to możesz użyć Data Factory. Ma ponad 90 konektorów do przeróżnych usług tj. źródeł Big Data takich jak Amazon Redshift, Google BigQuery, HDFS, SQL Server, Oracle Exadata, Teradata czy Salesforce. Możesz zautomatyzować pobieranie danych i zarządzać ich przepływem.
Databricks
To jest moje ulubione narzędzie do Big Data i nie tylko. To prawdziwy kombajn stworzony do transformacji dużych ilości danych. Pod spodem stoi Apache Spark stworzony do transformacji danych w stylu Big Data i zaawansowanych zadań analitycznych np Machine Learning. Można go zaprogramować wedle uznania przy użyciu Python, Scala, ,R czy SQL. Databricks świetne się sprawdzi przy tworzeniu Lakehouse czy analizie danych z Data Lake. Usługa daje dostęp do notatników, ułatwiających pracę.
Synapse Analytics
Usługa stworzona pod analitykę na dużych ilościach danych. Jeśli chcesz stworzyć Hurtownię Danych opartych na relacjach, to ta usługa pomoże w osiągnięciu celu. Są tam opcje tworzenia notatników i wykonywania analizy na danych tekstowych. Podobnie jak w Databricks. W jednej usłudze MS zmieścił kilka użytecznych funkcji tj. integracja danych, analityka big data, hurtownia danych. Tam też masz możliwość stworzenia procesu ETL. Jak zwykle bywa tak i w tym przypadku usługa ta łączy się z innymi w Azure oraz on-premise, więc integracja z wielu systemów nie będzie stanowić problemów.
Wpływ chmury publicznej
Czy chmura publiczna wpłynęła na proces ETL?
Klasyczna odpowiedź konsultanta – to zależy.
Zamiast się rozpisywać, odpowiem, że narzędzia dostępne w chmurze publicznej wpłynęły pozytywnie na proces integracji i transformacji danych. On-premise mogłeś być ograniczony narzędziami i ich możliwościami w chmurze ilość dostępnych narzędzi oraz ich stopień integracji jest większy. Masz znacznie więcej możliwości. Sam proces powinien podlegać tym samym zasadom projektowania, lecz możesz go osiągnąć znacznie szybciej i efektywniej.
Przykładowy proces ETL
Chciałem Ci pokazać, jak może wyglądać przetwarzanie danych w Databricks. Zakładam, że już stworzyłeś infrastrukturę, w ramach nauki możesz to zrobić ręcznie w portalu lub użyć jakiejś automatyzacji np PowerShell lub Terraform. Obecnie Terraform stają się bardzo popularne. Jako Inżynier Danych nie musisz być ekspertem, ale podstawy dobrze jest znać. Ja chcąc nie chcąc parę miesięcy spędziłem u klienta stawiając infrastrukturę, bo czasami trzeba pomóc, jak jest za mało DevOpsów. Żeby rozpocząć przygodę zacznę od najprostszego przykładu.
Architektura
Zacznę od prostej architektury, która jest oparta na podstawowych narzędziach w Azure. Wykorzystam do tego Azure Blob store, tutaj będą napływały nowe pliki. Następnie ADF będzie monitorował bloba i jak pojawi się nowy plik, to uruchomi Notebook w Databrickach. W notebooku będzie kilka podstawowych transformacji danych. Następnie zapiszemy wszystko do Data Lake w formacie „parquet”. Taki format danych ułatwi późniejszą analizę, dzięki rewelacyjnej kompresji zajmuje bardzo mało miejsca na dysku.
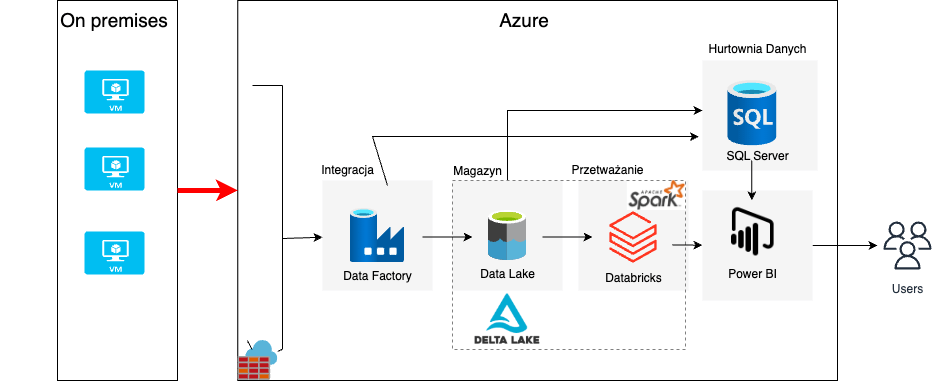
Najpierw orkiestracja
Tutaj skupmy się na prostym potoku w ADF. Będzie się składał z dwóch elementów. Pierwszy uruchomi notebook i jak transformacja przebiegnie pomyślnie, to ADF skopiuje dane do archiwum. Jest to tylko przykładowe rozwiązanie, niekoniecznie jest to optymalne. Wszystko zależy jakie mamy wymagania i co chcemy osiągnąć. Od czegoś trzeba zacząć i potem można to rozbudować.
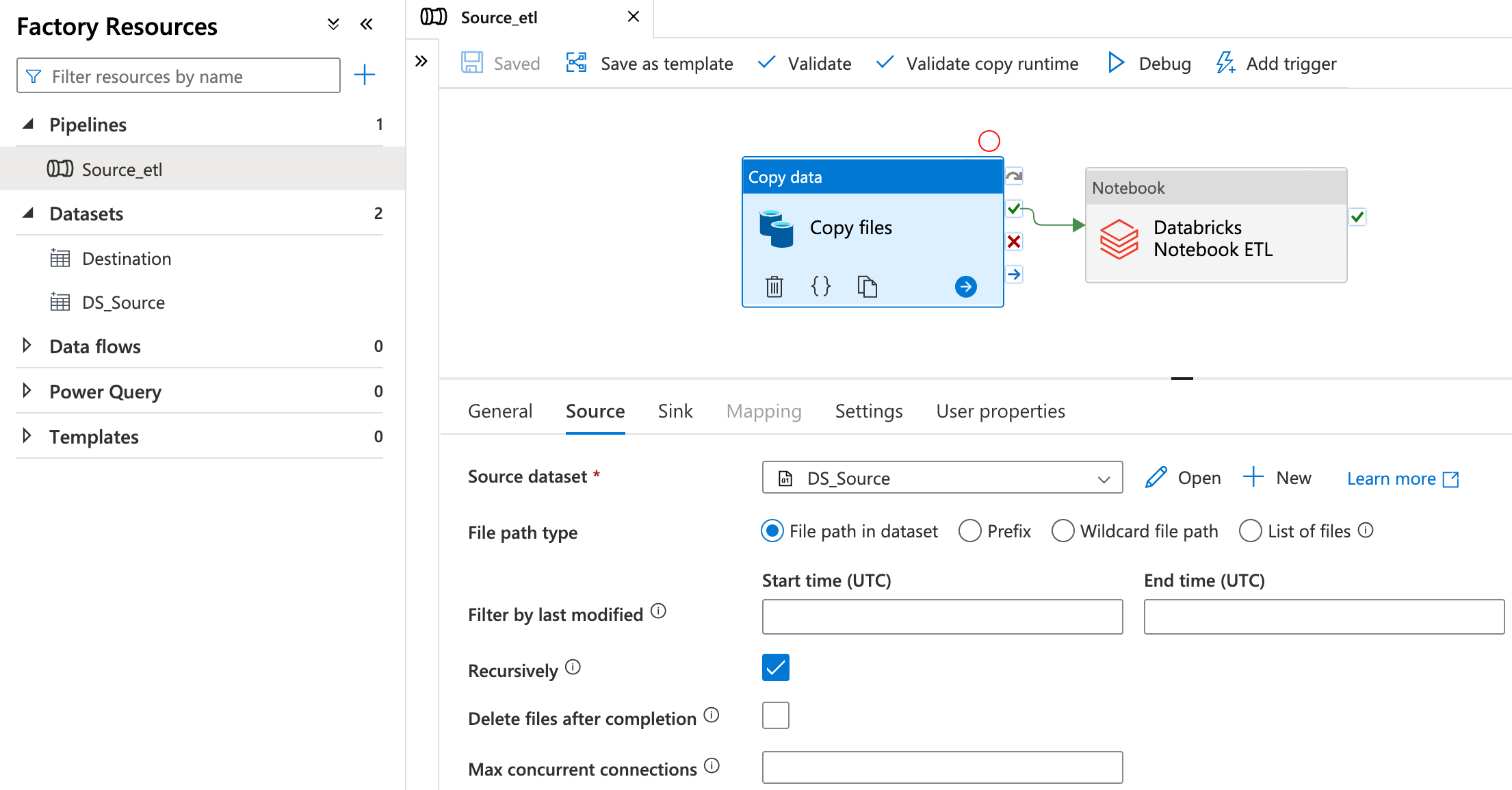
Databricks
W pierwszym etapie podłączam się do konta magazynu „storage mount”. Jako przykład, który możesz użyć do nauki korzystam z SAS (Sygnatura dostępu współdzielonego). Jest to tymczasowy token pozwalający na dostęp do konta magazynu. Produkcyjnie powinniśmy użyć KeyVaulta i w nim trzymać klucze. Przykład z Azure Docks.
Extract
# Pierwsze źródło pliki csv
filePath = "dbfs:/FileStore/tables/Files/actors.csv"
actorsDf = (
spark.read.format("csv")
.option("header", "true")
.option("inferSchema", "true")
.load(filePath)
)
# Drugie źódło pliki json ze schematem
filePath = "dbfs:/FileStore/tables/Files/xxxxx.json"
schemaFile = "dbfs:/FileStore/tables/Files/schema.json"
actorsDf = (
spark.read.format("json")
.schema(schemaFile)
.load(filePath)
)
Transform
# Podstawowa funkcja select, służy do wybierania atrybutów z dataframe
selectedMoviesDf = moviesDf.select("title","year","genre","country","date_published","duration","director","avg_vote")
# Filtrowanie danych po kategorii i ocenie
filteredDf = selectedMoviesDf.where("genre == 'Drama'").where("avg_vote > 4.8")
# Więcej filtrowania
filteredcolDf = filteredDf.where((f.col("country") == "USA") | (f.col("country") == "Canada, France") | (f.col("country") == "Netherlands"))
# Sprawdzanie wartości null isNull(), posotałe funkcje możesz sprawdzić w ten sam sposób
isnullHeight = namesDf.withColumn("is_height_null", col("height").isNull()) \
.withColumn("is_height_not_null", col("height").isNotNull())
# startswith() - Wartość kolumny zaczyna się od. lub endwith() czyli konczy sie na....
startDf = namesDf.select("name").where(col("name").startswith("Adam")).orderBy("name")
# isin() - Wyrażenie logiczne, które jest oceniane jako prawda jeśli wartość tego wyrażenia jest zawarta w wartościach argumentów.
# załóżmy że chcemy wyciągnąć wartości z kolumny, które są zawarte w liście.
countryList = ["Poland","Italy","France"]
isinDf = moviesDf.select("*").where(col("country").isin(countryList))
# like() - Wyrażenia, które działa jak SQL like.
likeDf = moviesDf.select("original_title",col("original_title").like("%the%"))
# `substr()` - Wyrażenia, które zwraca część string.
substringDf = moviesDf.select("original_title",col("original_title").substr(1,5))
Load
# Zapisuję do pliku
namesDF.write.format("delta").mode("overwrite").save(path)
Model danych
Celem procesu ETL jest stworzenie centralnego repozytorium danych. Może on mieć postać hurtowni danych, czyli magazynu relacyjnego opartego na relacyjnej bazie danych. Drugim dość powszechnym rozwiązaniem jest Data Lake. Jest to magazyn ustrukturyzowanych danych przechowywanych w formie plików. W Data Lake nie ma sztywnych relacji przez co, jest łatwiej analizować dane. Model danych można bardzo łatwo zmienić. A same relacje można uzyskać poprzez odpowiednią strukturę folderów.
Trzecim typem jest Lakehouse, o którym piszę w tym artykule. Jest to hybryda pomiędzy Data Lake oraz Hurtownią Danych. Ma on zalety obu rozwiązań, jest łatwiejszy we wdrożeniu i utrzymaniu.
Model danych to nic innego jak relacja bądź struktura danych w centralnym repozytorium. Dane z całej organizacji połącz tak, aby końcowemu użytkownikowi ułatwić analizę. Nie mówię tutaj tylko o podstawowych wykresach, ale o zaawansowanej analizie statystycznej. Oraz o coraz głośniejszej analizie ML. Taka analiza bez odpowiedniego modelu będzie bardzo trudna.
Tworząc model i wybierając proces ETL zadaj pytanie, Co jest celem? Kto będzie używał tych danych i w jaki sposób?