Big Data
Wiele firm ma obecnie problem z danymi. Jest ich na ogół za dużo. Dane są rozproszone w całej organizacji pochodzących z różnych miejsc. Każde źródło danych stanowi określony problem i jednocześnie daje dużo możliwości. Jest to albo bardzo skomplikowane, albo struktura danych jest trudna do zarządzania. Ponadto obserwujemy wykładniczy wzrost danych. Najlepiej opisać Big Data przy użyciu koncepcji 3vs.
Objętość – ogromne ilości danych. Firmy mają tak dużo danych, że trudno nimi zarządzać i uzyskiwać wgląd. Jeśli masz terabajty danych, potrzebujesz specjalistycznych narzędzi do zarządzania nimi. Możesz to osiągnąć za pomocą usługi HDInsight i powiązanego z nią zestawu narzędzi.
Różnorodność – ponieważ firmy mają wiele źródeł danych. Pochodzą z różnych jednostek biznesowych i systemów rozmieszczonych w całej organizacji. Stwarza to problem mieszanych danych strukturalnych i nieustrukturyzowanych. Wyobraź sobie, że każdy system dostarcza dane w innym typie pliku. Stwarza to problemy techniczne i podnosi koszty rozwiązania.
Prędkość – aby jeszcze bardziej skomplikować sobie życie, wyobraźmy sobie, że dane docierają bardzo szybko z różnych miejsc i do tego w czasie rzeczywistym. Jak czym takim zarządzać. Byłoby miło, gdybyś mógł przetwarzać go w czasie rzeczywistym i analizować w tym samym czasie. Dlatego możesz skorzystać z praktycznych narzędzi Big Data oferowanych przez platformę Azure w usłudze HDInsight.
Musisz pamiętać, że aby skorzystać z tych narzędzi, musisz myśleć bardziej holistycznie. Istnieje potrzeba zastosowania właściwej metodologii pracy i odpowiednich technik. Musisz stworzyć strategię i wprowadzić ją do biznesu, aby odnieść sukces. Jest świetny artykuł na temat podejmowania lepszych decyzji biznesowych za pomocą analizy predykcyjnej. Jest to coś, co należy uwzględnić w strategii.
Koncepcje Big Data
Przetwarzanie wsadowe – możesz przetwarzać dane w blokach (wszystko za jednym razem). Bardzo często wymaga to filtrowania i czyszczenia. Po przetworzeniu danych analiza i wizualizacje są znacznie łatwiejsze. Ta metoda działa lepiej w przypadku analizy historycznej.
Przetwarzanie strumieniowe – jeśli chcesz mieć niskie opóźnienia i obrabiać dane w czasie rzeczywisty, wtedy strumień jest twoim wyborem. Gdy nadchodzą dane, są one od razu przetwarzane i od razu wprowadzane do narzędzi analitycznych.
Uczenie maszynowe – gdy masz dostęp do dużych ilości danych, możesz rzucić wyzwanie analityce predykcyjnej. Duże ilości dobrych danych pozwalają na zastosowanie modeli statystycznych, takich jak klasyfikacja lub regresja, do prognozowania wyników. Usprawni to proces decyzyjny. Jest dużo narzędzi i łatwo dostępnej wiedzy z nauczania maszynowego, które pozwoli Ci wykorzystać to w swoim rozwiązaniu.
Co to jest HDInsight?
HDInsight to w pełni zarządzana usługa, która umożliwia korzystanie z narzędzi Big Data. Jest to standardowy ekosystem Hadoop działający na maszynach wirtualnych Azure, stworzony przez Hortonworks.
Zarządzanie przetwarzaniem klastrowym staje się bardzo łatwe, gdy masz odpowiednie narzędzia w ręku. Za tym stoi kilka gotowych platform open source (takich jak Apache Hadoop, Apache Spark, Apache Hive, Apache LLAP, Apache Kafka, Apache Storm i Microsoft Machine Learning Server). HDInsight obsługuje procesy takie jak wyodrębnianie, przekształcanie i ładowanie (ETL), hurtownie danych, uczenie maszynowe lub IoT.
Na platformie Azure dostępne są wszystkie narzędzia potrzebne do osiągnięcia sukcesu w zarządzaniu danymi. Już zacząłem opisywać ten zestaw narzędzi dostarczony przez platformę Azure.
HDInsight to trochę hybrydowe stworzenie, głównie PAAS z pewnymi atrybutami IAAS. Umożliwia dostęp do rodziny produktów Hadoop. Do wyboru jest kilka typów klastrów. Musimy pamiętać o jednej wielkiej wadzie HDInsight, głównie że nie można ich wyłączyć. W porównaniu do maszyn wirtualnych, które można uśpić, klaster HDInsight zawsze działa i wysysa pieniądze.
Mamy opcję do wyboru
Hadoop. Do wyboru jest kilka składników Hadoop w usłudze HDInsight.
HBase. Jest to baza danych NoSQL działająca na platformie Hadoop. Aby uzyskać szczegółowe informacje, przejdź do strony Apache.
Storm. Służy do obliczania strumieni wstrzyknięć danych w czasie rzeczywistym.
Spark. Obliczenia klastra w pamięci dla szybkich i odpornych na błędy obliczeń.
Usługi ML (serwer R). Machine Learning Server zapewnia analizy oparte na języku R w usłudze HDInsight. Może wykorzystać pakiety 8000+ R.
Kafka. Broker komunikatów służy do publikowania i subskrybowania strumieni rekordów danych.
Interaktywne zapytanie. Nazywany także Apache Hive, używany do przetwarzania analitycznego o niskim opóźnieniu.
Przechowywanie
HDInsight zaimplementował pamięć masową, aby korzystać z usługi Azure Storage lub Data Lake Storage. Możesz użyć usługi Azure Data Lake Storage Gen 1 / Azure Data Lake Storage Gen 2 lub obu. Nie martw się o utratę danych podczas usuwania klastra. Są od siebie niezależne. Możesz bezpiecznie usunąć klaster bez utraty danych. Jeśli chodzi o metadane, HDInsight używa bazy danych SQL, aby zachować metadane konfiguracji Hadoop. Nie musisz się tym martwić, Azure automatycznie zarządza tym za Ciebie.
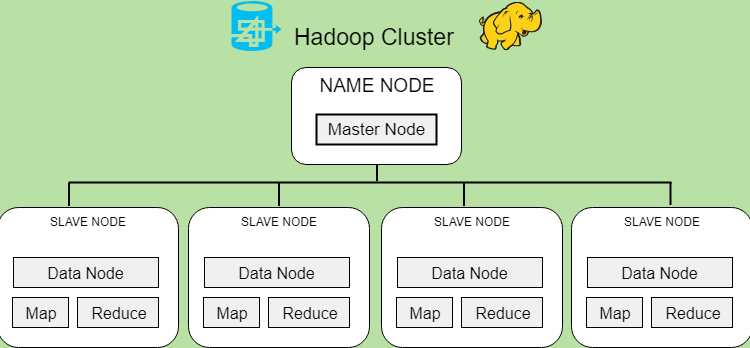
Hadoop
Hadoop to zestaw programów typu open source, które łącznie zapewniają system do przetwarzania danych w klastrze. HDFS oznacza rozproszony system plików Hadoop. Dane przetwarzane są zgodnie z zasadami MapReduce. Bardzo ważne jest środowisko YARN (kolejny negocjator zasobów), który jest odpowiedzialny za zarządzanie zasobami Hadoop.
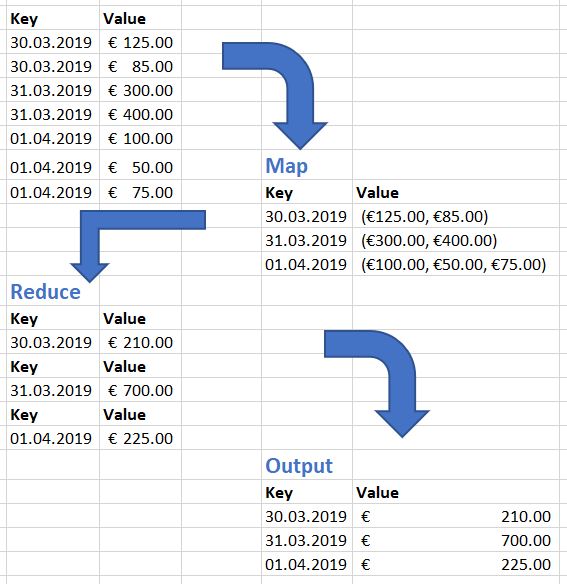
MapReduce
MapReduce to bardzo ważna koncepcja Big Data. Aby w pełni skorzystać z tej technologii, musisz zrozumieć, co to jest. Jest to proces zarządzania danymi. Proces składa się z dwóch faz, które dzielą dane na pary klucz-wartość.
Najpierw wykonuje się mapowanie, w którym wartości danych etapu są odwzorowywane na określony klucz. Spowoduje to utworzenie listy kluczy i pasujących wartości.
Następnym krokiem jest Redukcja, które wykonuje operację na każdej wartości klucza. Na przykład dodawanie lub mnożenie wartości. Dane wyjściowe generują odrębne klucze z obliczonymi wartościami.
Podstawowy przykład poniżej pokazuje ten proces.