

Dwa podstawowe problemy z jakimi się często spotykam związane są z osiągami jakie jestem w stanie uzyskać w Spark. Tobie też może się to przydarzyć jeśli już się nie wpadłeś w podobną pułapkę.
- proces działa bardzo wolno
- występują błędy OOM (out of memory errors)
Z mojego punktu widzenia to najczęstsze co mi się przydarza. Aplikacja zaczyna mulić lub pada z wielkim hukiem. 😁 Recept jest pewnie tyle ile jest problemów, ale chciałbym się skupić na podstawach pamięci żeby potem móc się zagłębiać w inne meandra Sparka.
Pamięć sterownika
Tutaj warto pamiętać jeśli wybierasz wielkość klastra, mówię tu o Databricks, często dobieramy standardową opcję, gdzie driver i wykonawcy mają taką samą wielkość RAM. W większości przypadków jest to wystarczające, ale…. Ostatnio coraz częściej widzę problemy z brakiem RAMu drivera (może to specyfika projektu, robimy za dużo collect() 😜). Już się na tym naciąłem i teraz częściej wybieram większy driver niż executor. W zależności od procesu szczególnie jeśli są długie i skomplikowane to driver otrzymuje sporo informacji z całego klastra. Pamiętaj trzeba to monitorować i w razie konieczności dobierać większy driver niż executor. UWAGA!! to zależy od tego co robisz, wystarczy mała zmiana kontekstu i nie będzie to optymalne.⚠
Uważaj na dwa scenariusze
Collect() to pobiera dane do drivera, to się zdarza kiedy piszemy dynamiczne rozwiązania i chcemy wykonać operacje na obiektach z DataFrame, jeśli robisz df.collect() to obciążysz Driver.
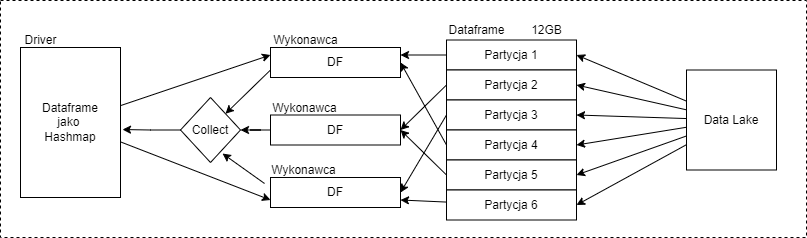
W drugim scenariuszu jeżeli robisz broadcast, czyli przesyłasz dataset na cały klaster to musisz zwrócić uwagę na ilość dostępnej pamięci. Przy przesyłaniu danych dochodzi do ich powielenia na sterowniku i w wykonawcach, zanim wkroczy GC (garbage collector) to pamięć będzie zajęta. Poniższy diagram przedstawia wymianę danych – jeśli na wejściu df ma 12GB to zanim wkroczy GC i zrobi porządek danych będzie 48GB (driver + wykonawcy = 12*4).
Pamięć wykonawcy
Ilość skonfigurowanej pamięci znajdziesz w spark.executor.memory – tutaj tip znajdziesz tą informację w Spark UI / Environment
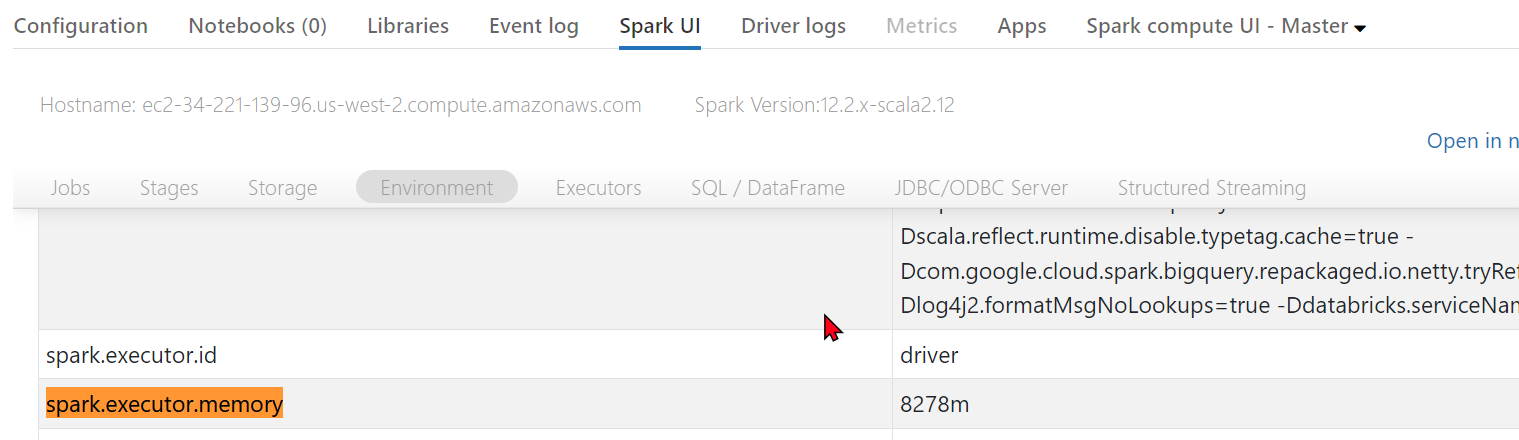
są tam jeszcze dwie dodatkowe wartości, z których się rzadko korzysta niemniej jednak warto je znać. „spark.executor.memoryOverhead” i „spark.executor.memoryOverheadFactor” jest ona wykorzystywana dla potrzeb nadmiarowych czyli zarezerwowana na potrzeby komunikacji sieciowej, buforowania, odzyskiwania pamięci i innych operacji systemowych. Muszę przyznać, że nie zdarzyło mi się ich zmieniać nie mniej jednak wiem, że istnieją i może będą musiał z nich skorzystać.
Serializacja danych
Dataframe oraz RDD są przechowywane jako serializowane bądź zdeserializowane w pamięci jak i na dysku.
- W pamięci – zdeserializowane: Ta forma przechowywania danych w pamięci podręcznej jest najszybsza, ponieważ redukuje czas serializacji; jednak może nie być najbardziej efektywna pod względem zużycia pamięci, ponieważ wymaga przechowywania danych jako obiektów..
- W pamięci – serializowane: Korzystając z standardowej biblioteki serializacji w języku Java, obiekty Sparka są konwertowane na strumienie bajtów w trakcie przesyłania ich po sieci. Ta metoda może być wolniejsza, ponieważ dane serializowane są bardziej obciążające dla procesora podczas odczyt.
- Na dysku: Za duże partycje RDD mogą zostać zapisane na dysku. Jest to wada z punktu widzenia osiągów, ciągły zapis i odczyt są wolne. Plusem jest większa odporność na awarie bo dane są na dysku.
Dane muszą zostać przetworzone na format łatwy do konsumpcji. Możesz mieć format który się wolno serializuje i to bardzo spowolni twoją aplikację. Java udostępnia dwie biblioteki do serializacji.
Java serialization jest to opcja podstawowa. Możesz pracować z każdą klasą, która implementuje java.io.Serializable.
Kryo serialization Kryjo jest bardziej kompatkowy i do tego szybszy. Ale są też minusy nie ma wsparcia dla wszystkich typów Seriaalilzable i wymaga zarejestrowania klas przed ich użyciem. Więc musisz dodać parę linii kodu. Jeśli chodzi o Kryo to najlepiej się sprawdzi w Scali. W Pythonie raczej nie ponieważ w pytonie są one typem byte[]. Aczkolwiek tego nie testowałem, zawsze polecam sprawdzić i przekonać się na swoim przykładzie.
Podkręcanie pamięci
Zarządzanie pamięcią
Pamięci w Apache Spark jest podzielona na dwa obszary, obie dzielą ten sam region pamięci. Jest on podzielony funkcyjnie.
- Wykonawczą
- Magazynu
- Wykonawcza (Execution) jest użyta podczas obliczeń np. shuffles, joins, sortowanie, agregacje. Np. jeśli używasz groupBy to to dane są ładowane do obiektu (hashMap), który żyje dość krótko.
- Magazyn (Storage) – używaną jako cache, jeśli chcesz używać tych samych danych na całym klastrze. Wystarczy, że użyjesz opcji (persist) w Sparku. Powoduje one zarezerwowanie miejsca w RAM i przetrzymanie tego obiektu (Dataframe). GC go nie usunie nawet jeśli proces nie będzie już korzystał z tych danych. Zawsze musisz wykonać unpersist(). Możesz skorzystać z tej opcji jeśli potrzebujesz Dataframe wielokrotnie podczas przetwarzania danych np jakąś tabelę referencyjną.
Kiedy nie używasz pamięci wykonawczej wtedy cała pamięć magazynu jest dostępna.
Pamięć wykonawcza (execution) może wyrzucić pamięć magazynu jeśli jest to konieczne, ale tylko jeżeli cała użyta pamięć wpada na wyznaczony poziom. Ta pamięć wewnętrzna to region w pamięci głównej gdzie bloki pamięci są zapisane (cached) i nie są usuwane. Pamięć magazynu (storage) nie może usunąć pamięci wykonawczej jest ona podrzędna.
Jeśli którejś z nich zabraknie pamięci to dojdzie do spill – czyli zapisana obiektów na dysku.
Jeśli aplikacje nie używa całej pamięci podręcznej (cache) to cała jest wykorzystana na wykonawczą (execute).
Konfiguracja pamięci
Podział pamięci
spark.memory.fraction – jest to 60% całej pamięci (JVM heap space – 300MiB)
spark.memory.storageFraction jest to wydzielona część całej pamięci przeznaczonej na cache, ustawiona na 50% z spark.memory.fraction.
Jak sprawdzić ile pamięci potrzebuje
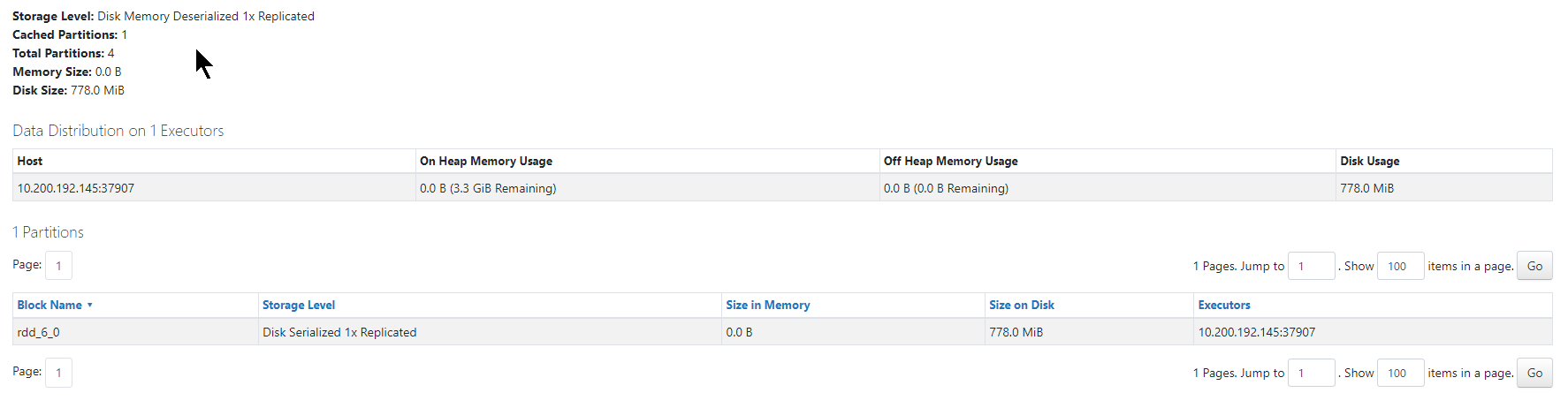
- Stwórz RDD,
- Cache
- Wejdz na spark UI tab ‘Storage’
- Zobaczysz ile pamięci RDD zajmuje

Poniżej metoda, która pozwala oszacować ile pamięci zajmuje Dataframe – użyj metody SizeEstimator estimate wprawdzie jest to tylko informacja szacunkowa, ale zawsze coś podpowie.
df.cache()
sampled_bytes = spark._jvm.org.apache.spark.util.SizeEstimator.estimate(df._jdf)
total_mb = sampled_bytes / (1024 * 1024)
Znalazłem drugą metodę jak zwykle w necie jest ich wiele, niestety nie działa jak najlepiej. Warto się nad tym pochylić i sprawdzić co tak naprawdę pokazuje.
df= (spark._jsparkSession.sessionState()
.executePlan(df._jdf.queryExecution().logical(),
df._jdf.queryExecution().mode()).optimizedPlan()
.stats()
.sizeInBytes())
Spotkałem się 3 sposobem ale to nie ma nic wspólnego ze Sparkiem. W data science często korzysta się z Pandas i można bardzo łatwo przekształcić Sparkowy Dataframe na Pandas i wyliczyć jej wielkość. Niestety nie jest to zbyt precyzyjne ponieważ Pandas nie ma tych samych typów danych co Spark. Ich waga w RAM będzie inna, co nie oznacza, że możesz się posiłkować tą dodatkową informacją. Jeśli chodzi o Pandas to nie jestem w tym biegły, ale jest na necie sporo informacji gdzie można znaleźć trochę informacji.
pandas_df = df.toPandas()
pandas_df.memory_usage(deep=True).sum()
lub
pandas_df.info()
alternatywa
import sys
sys.getsizeof(pandas_df)
Każda z tych meto daje różne wyniki, co nie oznacza, żeby z nich nie korzystać lecz przyjąć, że są to dane szacunkowe.