

1. Cloud
Jeśli jeszcze nie jesteście w temacie to niewątpliwie musisz pomyśleć o chmurze. Staje się ona nieodzowną częścią naszego świata IT. Coraz więcej firm myśli i zaczyna coraz mocniej cisnąć w chmurę. Oczywiście on-premises nie zniknie z pola widzenia i jeśli firma ma już jakieś rozwiązanie lokalnie, to zapewne będzie go utrzymywać. Obserwując rynek i nasze projekty coraz więcej firm decyduje się na rozwiązanie hybrydowe. Jako developer czy tester musisz być gotowy na pytania, czy jesteś w stanie to postawić w Azure? Obserwuje coraz większe ciśnienie na budowanie kompetencji cloudowych. Nie zwlekaj i zacznij się uczyć chmury. Nie trzeba wcale na to dużo pieniędzy. Na początek możesz o tym poczytać.
Sugeruje wyznaczyć czas w kalendarzu, żeby choć trochę czasu poświęcić na ten temat. Polecam Azure, który daje gotowe samouczki w Azure Education Center. Wiele z nich daje dostęp do Sanboxa, czyli działających usług w Azure. Wystarczy wybrać swoją ścieżkę i można zacząć działać.
Jeśli myślisz o świecie AWS, to tam też są samouczki. Na początek zawsze coś, są za darmo więc żal nie skorzystać.
Jeśli nie wiesz, którą wybrać sprawdź, to sprawdź czy są już jakieś projekty w twojej firmie. Jeśli nie ma, to możesz rzucić monetą i też będzie dobrze. Ja bym się skupił na Azure lub AWS, bo są najpopularniejsze. Jeśli poznasz i zrozumiesz narzędzia w jednej chmurze, to przejście na drugą nie będzie stanowiło problemów. Tutaj spoiler alert !!! ich usługi działają w podobny sposób, tylko się inaczej nazywają, więc przejście z jednej na drugą nie będzie tak bolesne.
Jeśli chodzi o Databricks, czyli zabawkę do Big Data, to jest w każdej chmurze, więc inżynier danych z taką wiedzą obskoczy wszystkie 3 chmury, AWS, Azure i Google Cloud.
Jest jedna bardzo ważna rzecz, o której wiele osób nie wie. Obecnie AWS ma przewagę, jeśli chodzi o udział w rynku. Jest jeden ważny aspekt, który sprawia, że Azure systematycznie rośnie. Microsoft znacznie lepiej zarządza relacjami z klientem. W moim obecnym projekcie MS od lat przysyła swoich architektów do klienta, tak do pomocy. Regularnie ludzie MS chodzą na spotkania i pomagają klientowi w codziennych problemach. Jest to strategia MS polegająca na ciągłym wspieraniu klientów oraz utrzymywaniu dobrych relacji z partnerami. Tutaj AWS kuleje i nie ma tak dobrych relacji, co długoterminowo sprawia, że Azure rośnie i nadgryza coraz to większą część tortu.
Źródła wiedzy
- Azure Education Center: Dla inżynierów danych polecam przerobić materiały do certyfikatu DP-203
- Seequality Blog
- Mrpaulandrew Blog
- Databricks engineering blog
- James Serra’s Blog
2. Rozwiązania hybrydowe
Aktualnie jest jeszcze mnóstwo serwerowni na świecie. Firmy od lat inwestowały w centra danych i tak or razu ich nie porzucą. Zamiast zwiększać wydatki na maszyny w piwnicy wolą połączyć się z chmurą publiczną. Rozwiązania hybrydowe są teraz bardzo popularne i ty jako inżynier powinieneś móc rozszerzyć, to co robisz u klienta na VM-ce i przenieść bądź dodać parę funkcji w chmurze.
Prędzej czy później staniesz przed wyzwaniem chmury i będziesz musiał użyć kilku usług np. w Azure. Zachęcam do pro aktywności i rozpoczęcia od zdobywania, chociaż wiedzy teoretycznej.
Jeśli przyjdzie ci ochota na wiedzę praktyczną, to jest sporo darmowych usług w Azure i AWS. Więc na początek wystarczy. Jest też wiele usług kosztujących przysłowiowe grosze, więc warto trochę zainwestować. U nas ostatnio jak w większości firm brakuje ludzi z wiedzą chmurową, więc gorąco polecam naukę. Będzie sporo ciekawych projektów.
Polecam zapoznać się z Azure Architecture Center jest tam mnóstwo przykładów jak takie rozwiązania mogą wyglądać.
Tutaj trochę statystyki.
- Dane z eurostat: Use of Cloud computing services
- Dane z firmy IDC zajmującej się badaniem rynku: IDC Forecasts Worldwide „Whole Cloud” Spending to Reach $1.3 Trillion by 2025
Wszystkie znaki na niebie i ziemi wskazują na to, że będzie trzeba się z chmury doszkolić.
Źródła wiedzy
Użyłbym tych samych źródeł co w pierwszym akapicie. Jeśli on-premises już znasz, to teraz trzeba poznać odpowiedniki twoich narzędzi w chmurze.
- Microsoft Azure YouTube (ponad 200K subskrybentów i dużo ciekawych informacji)
- Cloud Academy YouTube
- Azure GitHub sporo kodu może ci się przydać
- Azure DevOps mniej dla inżyniera danych ale jeśli nad czymś utkniesz to warto mieć źródło wiedzy
3. Lakehouse
To jest cały czas rozwijane pojęcie mające na celu zastąpić tradycyjną relacyjną hurtownię danych. Ten temat jest bardzo mocno promowany przez Databricks i coraz częściej używany. Mając do dyspozycji takie narzędzia jak Databricks czy Spark z wykorzystaniem Azure Data Lake nie ma konieczności tworzenia relacyjnej hurtowni danych. Dane mogą być luźno poukładane na poziomie Blob Store czy Data Lake. Zamiast tabel w bazie możemy mieć tabelę Delta stworzoną w Databricks.
O Lakehouse już pisałem. Jest to bardzo elastyczne rozwiązanie i znacznie łatwiejsze w stworzeniu i utrzymaniu niż relacyjna baza. Dzięki jego zaletom jest coraz częściej stosowane. Na ten temat znajdziesz dużo materiałów w Databricks i nawet sporo kursów online. Można go wykorzystać jako wzorzec architektury i sporo z niego skopiować do innych rozwiązań niewymagających relacyjnej bazy danych.
Źródła wiedzy
- What Is a Lakehouse?
- Czy Data Lakehouse pożre Hurtownię Danych?
- Frequently Asked Questions About the Data Lakehouse
- Darmowy kurs Lakehouse z Delta Lake :
- Przegląd po funkcjach Delta Lake
- Zasady inżynierii oprogramowania z Databricks
- Kompleksowy potok danych wsadowych i strumieniowych OLAP za pomocą Delta Lake
- Udostępnianie dane użytkownikom końcowym za pomocą tabel zbiorczych i bazy danych Databricks SQL
- Wzorce projektowe, jak udostępnić dane do dalszego użycia
- tip: Jak się już zalogujesz, to poniżej video będziesz miał do pobrania ebooki, są tam dwa godne polecenia. The Big Book of Data Engineering, Building the Data Lakehouse
- Delta Lake Cheat Sheet dokument pdf
4. AI/ML
Tego tematu chyba nie trzeba reklamować, świat oszalał na punkcie AI i ML. Technologii wspierającej analitykę jest coraz więcej. W pracy siedzę obok kolegi, który zajmuje się tym zawodowo i dużo czasu spędza nad sieciami neuronowymi. W firmie jest cały zespół zajmujący się tym tematem. I z moich obserwacji wynika, że w miarę jak kierownictwo firm staje się świadome i zaczynają rozumieć technologię AI/ML jej użycie będzie rosło. Kolejnym czynnikiem zwiększającym popyt na tego typu rozwiązania jest ilość developerów z odpowiednimi umiejętnościami. Jest wiele miejsc, gdzie można wykorzystać ML, tylko trzeba odpowiednich umiejętności. Coraz więcej ludzi uczy się tego, co spowoduje rozwój w tym kierunku.
Niewątpliwie każdy, kto pracuje z danymi powinienem znać, chociaż podstawy. Pytanie ile z tego taka osoba jak ja, czyli zwykły skromny inżynier danych 🙂 musi znać. Muszę przyznać, że dzisiaj wiem za mało – rzekłbym mam mikro wiedzę. Przyczyna jak zwykle jest jedna – brak czasu, ale ty pewnie na to też cierpisz :). Jedyne co mogę zrobić to zebrać źródła ciekawej wiedzy, żeby regularnie chociaż trochę podłubać przynajmniej w podstawach, które mogą być potrzebne w mojej roli.
Dobrze by było mieć jakiś plan i chociaż poznać 3 proste rzeczy dające wartość w pracy.
Źródła wiedzy
- mikulskibartosz.name Blog
- The Data Scientist’s Guide to Apache Spark
- Wprowadzenie do sztucznej inteligencji na platformie Azure
- Używanie narzędzi wizualnych do tworzenia modeli uczenia maszynowego
5. Predictive analytics
Przewidywanie tego, co się wydarzy jest bardzo ciekawym konceptem. Niejednokrotnie sam chciałbym wykorzystać możliwości predykcji w ładowaniu i analizie, żeby lepiej obsłużyć wyjątki. Jest to ściśle powiązane z AI/ML. Na ostatnim spotkaniu z klientem jednym z wymagań była możliwość przewidywania usterek, jakie mogą się pojawić podczas produkcji. Wyobraź sobie fabrykę i całą masę urządzeń przemysłowych, które wysyłają dane. Wszystko spływa na bieżąco (IoT in real time) i trzeba jakoś analizować dane w locie i jeszcze przewidzieć co może się wykrzaczyć. To ci dopiero wyzwanie, niestety łatwe to nie jest, ale ktoś musi zrobić tą brudną robotę. Jest to bardzo ciekawe, ale i wymaga sporo pracy. Tutaj zebrałem listę źródeł pomagających w początkowych etapach nauki.
Oto lista miejsc, gdzie można podejrzeć jak jest to rozwiązane.
Źródła wiedzy
- Predictive Analytics with Spark in Azure Databricks – ciekawy i krótki kurs warto przerobić
- Data science and machine learning with Azure Databricks
- Defect prevention with predictive maintenance using analytics and machine learning
6. Real time analytics
Narzędzi IoT jest coraz więcej, a to one głównie będą generować dane, które my musimy ogarnąć. Jest coraz większe zapotrzebowanie na analizę danych w czasie rzeczywistym i podejmowanie decyzji na bieżąco. Jestem przekonany, że projektów tego typu będzie coraz więcej.
W Azure masz dwa najpopularniejsze narzędzia Spark Streaming i Stream Analytics. Oba narzędzia służą do analizy i przetwarzanie danych strumieniowych, aczkolwiek Spark ma znacznie większe możliwości. Jeśli interesuje cię certyfikacja Azure, to musisz wiedzieć, że pamiętam tylko pytania dotyczące Stream Analytics. Polecam poznać oba, bo prędzej czy później ta wiedza się przyda.
Jeśli tylko musisz przetrzymać dane, a potem analizować, to nie jest takie ciężkie. Schodki się zaczynają, kiedy trzeba robić analizę i przetwarzać dane w czasie ładowania. To jest już trochę trudniejsze.
Poniżej linki do notatników Databricks z przykładami oraz dodatkowe przykłady, które pozwolą Ci lepiej poznać te narzędzia.
Źródła wiedzy
- Structured Streaming demo Python notebook
- Structured Streaming demo Scala notebook
- Pozyskaj strumienie danych za pomocą Azure Stream Analytics
- Real-Time Insights From Azure Databricks Jobs With Stream Analytics And Power BI
7. Bazy danych Time-Series
Nawiązując do analizy danych w czasie rzeczywistym, kiedy przeanalizujemy już nasze dane, to trzeba je gdzieś trzymać. Dane z urządzeń IoT mają pewną cechę, która wymaga odpowiednich narzędzi do ich składowania. W zeszłym roku miałem epizod w takim właśnie projekcie, gdzie wymagane było, aby dane były dostępne przez 5 lat. Dodatkowo klient chciał je analizować, używając SQL. Przy wolumenie 60-80TB trzeba było dobrać technologię to tego problemu. Ze względu na prosty model danych (około 80 atrybutów) Big Data raczej nie pasowały to tego problemu.
Z danymi tego typu jest jedno ułatwienie, nie trzeba wykonywać operacji update tylko append. Więc najkorzystniejszym rozwiązaniem jest baza danych, ale nie zwykła, lecz przystosowana do danych IoT. Zachęcam do zapoznania się z tą technologią i architekturą rozwiązań IoT. Na szczęście nie ma aż tak dużo narzędzi na rynku, na początek można zacząć od kilku.
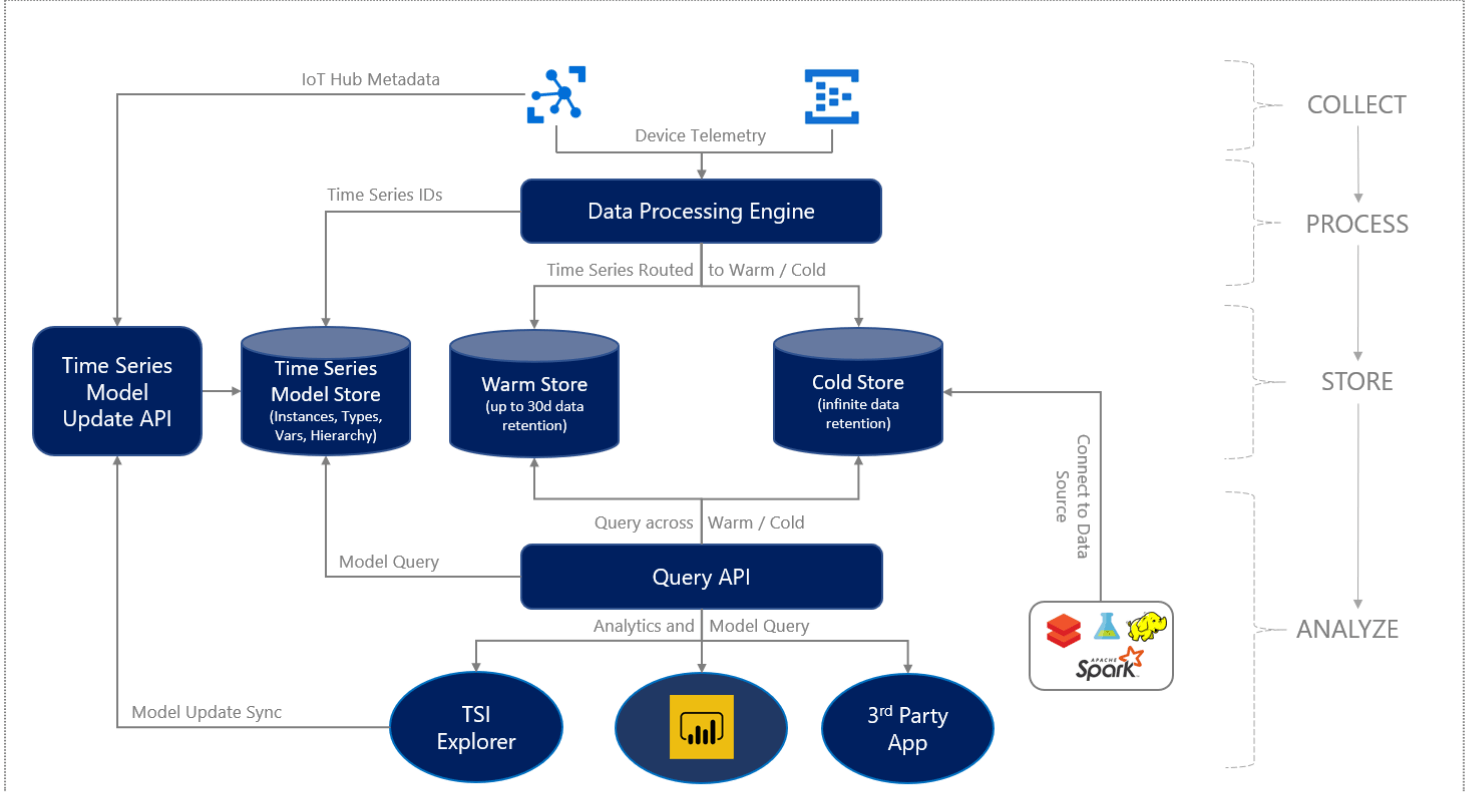
Źródła wiedzy
- InfluxDB
- TimescaleDB, Coś na YouTube, IoT Demo
- Time Series insights Gen2
- Graphite, Porównanie Graphite vs InfluxDB vs Cosmos DB
2022
Podsumowując przemijający rok, zauważyłem ciągle rosnący trend, jeśli chodzi o chmurę publiczną. Trzeba więcej o tym myśleć i poszerzać wiedzę. Szczególnie ze wzorców projektowych i rozwiązań architektonicznych. Większość problemów, nad którymi pracujemy, zostało już rozwiązane, więc nie trzeba się męczyć i może da się coś wykorzystać.
Zachęcam do zdobywania wiedzy i zabawy.
Daj znać czy masz jakieś fajne źródła i czy przyszły rok wniesie zmiany do twojego życia projektowego?