
Jeśli zadałeś sobie pytanie, „big data co to?”, to jesteś w dobrym miejscu. Postaram się wyjaśnić do czego służy ta technologia, i kiedy użyć tego zestawu narzędzi. Ten prosty model, powinien Ci pozwolić dobrać optymalną technologię, pasującą do twojego problemu.
Big Data przetłumaczone z angielskiego oznacza dosłownie „duże dane” po polsku lepiej by brzmiało „dużo danych” lub „duże zbiory danych„. Tutaj pewnie zapytasz ile to jest dużo? Właśnie, żeby odpowiedzieć na to pytanie musisz przeczytać trochę więcej, poniżej znajdziesz odpowiedź.
Ten artykuł powinien wyjaśnić co to jest Big Data pokazując jednocześnie kiedy użyć tej technologii. Po tej lekturze nie powinieneś mieć żadnych wątpliwości.
Jak działa technologia Big Data
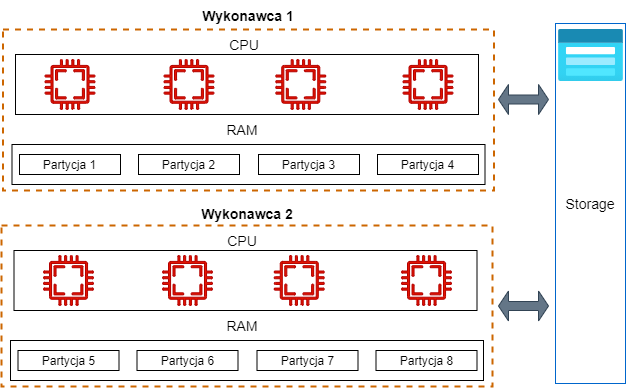
Technologia Big Data jest już dość leciwa, Apache Hadoop powstał w 2006 roku a Apache Spark w 2009. Tak naprawdę na dużą skalę zaczęła się rozwijać od 2012 roku, więc jest już na rynku bardzo stabilna. Główną ideą tej technologii jest możliwość równoległego przetwarzania danych. Oznacza to, że możesz podzielić dane na partycje, czyli na małe kawałki. Tak podzielone, pozwalają na wykonanie kalkulacji na każdej partycji osobno. Oczywiście nie ty to robisz, ale algorytmy Apache Spark, o którym możesz poczytać tutaj. Np. Jeśli twoje dane są podzielone na 100 partycji, to narzędzia Big Data mogą przetwarzać dane z każdej partycji w tym samym czasie. To tak jakbyś oglądał 10 seriali na 10 telewizorach w tym samym czasie, jedna godzina i już jesteś na bieżąco z Netflixem. 😀
Poniższy diagram to ilustruje, posiadając 8 rdzeni mogę przetwarzać 8 partycji w tym samym czasie.
Transformacje w stylu Big Data
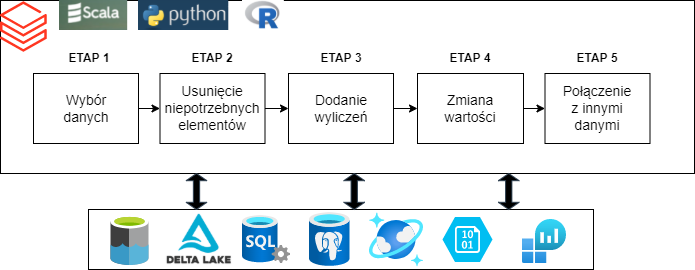
Big Data służy do transformacji i przetwarzania danych. Jeśli twoje dane wymagają modyfikacji, to będziesz potrzebował napisać kod, który uzdatni dane, naprawi je. Oczywiście dzisiejsze narzędzia takie jak Apache Spark czy Apache Hadoop to kombajny i ich ekosystem jest uzbrojony w szereg narzędzi do obróbki i analizy danych. Od prostych selektów aż do procesów ML (Machine Learning).
Powstały one dlatego, że ludzie nie mogli sobie poradzić z olbrzymią ilością danych. W erze przed technologią Big Data dane musiały zostać przesłane do procesora, gdzie jedyną równoległością przetwarzania była wielowątkowość. Dzięki narzędziom, jakie oferuje Big Data, masz możliwość tworzyć potoki danych (data pipelines). Są to wieloetapowe procesy, transformujące dane. Począwszy od źródła, w którym są surowe dane aż do miejsca docelowego, gdzie będą ustrukturyzowane, naprawione bez błędów i przygotowane do finalnego użycia w analityce.
Diagram potoku danych Big Data
Dobór narzędzi Big Data
Zanim dobierzesz narzędzia do problemu, powinieneś zadać kilka pytań, oczywiście muszą to być odpowiednie pytania. Ważne jest, aby przy podejmowaniu decyzji przejść przez ścieżkę, która może wyglądać jak na diagramie poniżej. Każda skomplikowana decyzja powinna być podjęta przy użyciu drzewka decyzyjnego. W technologii jak i w życiu, rzeczy nie są tylko białe lub czarne. Przestrzegam przed zero-jedynkowym traktowaniem problemów nie tylko podczas decyzji o Big Data.
Upewnij się, że dobierasz technologię pasującą do problemu, a raczej optymalne narzędzie. Do tego wymagana jest pewnie zmiana mentalna prowadząca do kwestionowania wybranego narzędzia. Często zdarza się, że wybieramy coś na szybko, bo wydaje się, że to akurat pasuje to problemu. Natomiast jeśli zadasz odpowiednie pytania, to może się okazać, że wybrałeś armatę do zabicia komara. Tak się czasami dzieje z Big Data.
Oczywiście przy wyborze narzędzia każda decyzja jest odwracalna, ale słono zapłacisz za błąd a szczególnie firma. Ból, jaki powstanie przy wyborze złych narzędzi, pojawi się dopiero po jakimś czasie. Kiedy się zorientujesz, że masz problem, projekt jest już tak zaawansowany, że zmiany są zbyt kosztowne. Koszt to nie tylko pieniądze, ale i stracony czas oraz opóźnienie projektu. Tak firma zbiera dług technologiczny. Więc lepiej zapobiegnij temu zawczasu i dobierz odpowiednią technologię do problemu.
Najważniejsze cechy Big Data – 3 x V
Zbliżamy się do kluczowego elementu, który wyjaśni i pomoże w decyzji czy potrzebujesz technologii Big Data. Są to słynne 3 V
- Volume (Ilość)
- Velocity (Prędkość)
- Veriaty (Różnorodność)
Z tego wynika, żeby zakwalifikować Big Data do rozwiązania problemu z danymi, muszą być spełnione trzy warunki. Gdybym miał się pokusić o napisanie formuły pozwalająca na podjęcie decyzji to wyglądałaby następująco.
V (Ilość) + V (Prędkość)+ V (Różnorodność) = X
Do każdej zmiennej przypisujesz wartość 1, jeśli spełnia wymagania opisane poniżej. Jeśli po zsumowaniu X = 3 lub jesteś blisko tej wartości, to jest bardzo duże prawdopodobieństwo, że dobrze dobrałeś technologię. Jeśli jest mniej niż trzy, to oznacza, że trzeba się jeszcze skonsultować i dokładnie zbadać wymagania. Oczywiście jest to prosty framework mogący pomóc i trzeba go potraktować jako sugestię, a nie definitywną decyzję. Ma ona na celu rozpoczęcie dyskusji i sprawdzenie, czy zadałeś odpowiednie pytania.
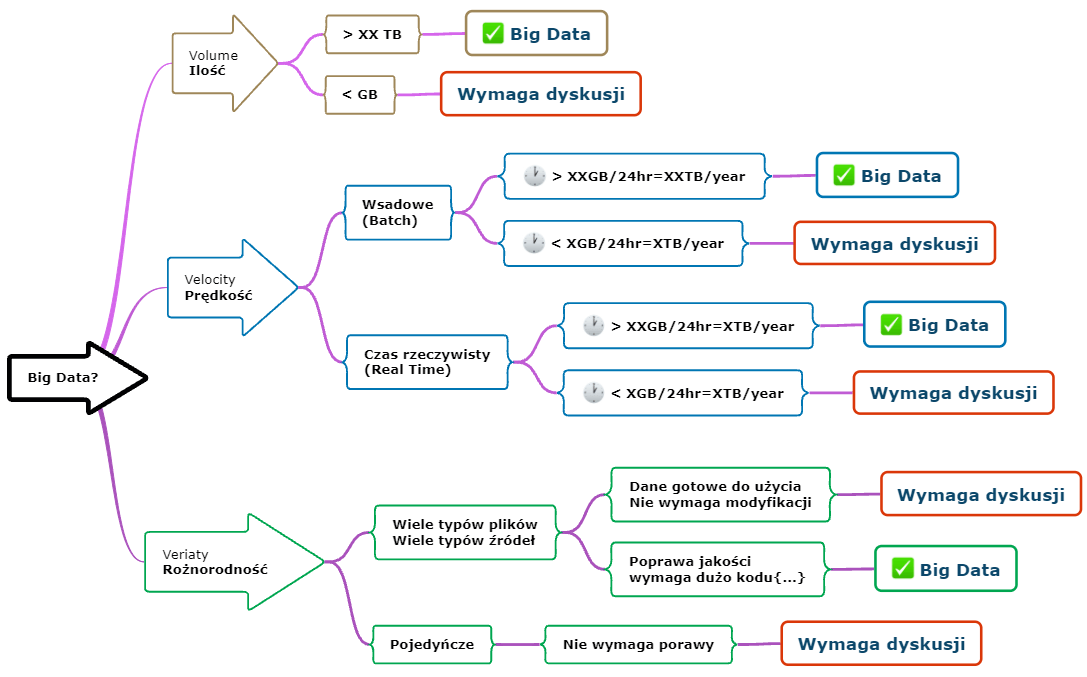
Ilość
Duże ilości danych, tutaj mówimy zdecydowanie o terabajtach (TB). Chociaż jeśli masz setki gigabajtów, to nie jest wartość, którą powinieneś ignorować. Analizując ten punkt powinieneś zadać sobie pytanie, nawiązujące do punktu drugiego. Mianowicie jaka jest ilość danych w przedziale czasu, np 500GB na dobę. Ile danych system będzie musiał przetworzyć np. na godzinę. Jak już odpowiesz na to pytanie, to przejdź do następnego. Jeśli danych jest mało (kilkadziesiąt GB) i można je przetworzyć na wirtualnej maszynie, to Big Data nie koniecznie jest najlepszą opcją.
Prędkość
Tutaj podstawowym pytaniem jest, jaki jest napływ danych do systemu w przedziale czasu? Można to uprościć do ilości danych na godzinę lub na dobę. W tym punkcie pojawia się dodatkowy aspekt sposobu, w jakim dane spływają do systemu. Tutaj są dwie opcje, jest to Batch, czyli paczki danych, pojawiające się co jakiś czas. Jednym z popularnych metod jest przetwarzanie danych w ciągu nocy, kiedy nikt nie używa systemu. Z drugiej strony jest typ Real Time, czyli dane, które napływają ciągle w czasie rzeczywistym. Najlepszym przykładem są dane z urządzeń IoT. W tej kategorii skup się na danych przetwarzanych w trybie Batch. Ja bym zakwalifikował dane do tej kategorii, jeśli przekraczają kilkaset GB na dobę.
Różnorodność
Trzecia kategoria to różnorodność, co oznacza, że dane pochodzą z wielu źródeł. Więc jeśli masz kilkanaście rodzajów plików np. txt, json, csv, avro, pliki binarne. Do tego dochodzą dane z wielu systemów lub baz danych. To oznacza, że jest ich sporo i trzeba narzędzia radzącego sobie z wieloma typami danych. Tutaj Big Data będzie pomocne. Z drugiej strony, jeśli masz jeden rodzaj pliku lub źródła danych to oznacza, że nie powinieneś zaliczyć tych danych do kategorii różnorodne.
- Jakość : Dodatkową podkategorią różnorodności jest jakość danych. Ważne jest czy dane wymagają dużo manipulacji, żeby można było wykonać na nich analizę. Jeśli tak to zapewne będziesz potrzebował napisać sporo kodu, żeby dane dało się użyć w dalszych procesach. Jeśli dane są bardzo nieustrukturyzowane i wymagają pracy programistów, to najprawdopodobniej powinieneś je zaliczyć do tej kategorii. Natomiast, jeśli twoje dane są bardzo proste tj, nie wymagają żadnych modyfikacji, możesz nie potrzebować skomplikowanego narzędzia Big Data, ponieważ nie ma czego przetwarzać.
Historia pewnych 'Big Data’ danych
Żeby lepiej zobrazować do czego służy Big Data, opowiem wam historię o pewnej grupie ludzi, którzy by nie dali rady analizować danych bez Apache Spark.
Wyobraź sobie chłodny mglisty poranek. Do Londynu wjeżdża ciężarówka, parkuje i rozpoczyna się wyładunek. Panowie bardzo ostrożnie niosą małe pakunki i wnoszą go do szarego budynku. Tam grupa ludzi w okularach z grubymi denkami równie ostrożnie je odbiera. Małe paczuszki znikają w korytarzach budynku. Co to za ładunek, skąd się wziął. Patrzę na rejestracje, a tam widzę biały krzyż na czerwonym tle. To chyba Szwajcaria… Co takiego delikatnego przyjechało ze Szwajcarii. Może czekoladki dla Królowej. Hmmmm
Właśnie, że nie, na koszulce jednego z panów z grubymi okularami widnieje tabliczka ’Physics department’. Co tu się dzieje, fizycy z Londynu kupują czekoladki. No dobra powiem o co chodzi. Ciężarówka przyjechała ze Szwajcarii z CERN. W tej ciężarówce były twarde dyski około 60PB danych pochodzących z Hydron Collider. W Londynie dane są wrzucane na rozproszone klastry Apache Spark. Naukowcy są wdzięczni firmie Google, która jest tak szczodra dla środowiska akademickiego, że udostępnia im swoje serwery, których maja pod dostatkiem. Potem ludzie z departamentu fizyki siedzą przed monitorami i próbują ogarnąć te dane.
To jest jeden z przykładów użycia Big Data, gdzie ta technologia sprawdza się znakomicie. Rzekłbym, bez niej nie daliby rady wiele zrobić. Oczywiście nie musisz mieć 60PB, żeby korzystać z tej technologii, ale sprawdź, czy twój problem może być rozwiązany przy użyciu innych narzędzi nie koniecznie Big Data.
Zalety technologii Big Data
Największą zaletą narzędzi Big Data jest oszczędność czasu. Jak wiesz 'czas to pieniądz’. Nie ważne czy rozwiązanie będzie w chmurze czy, on-premise. Koszt CPU, czyli mocy obliczeniowej jest znaczny i stanowi największy koszt. Więc powinieneś dokonać starań, żeby wydawać jak najmniej i wykorzystać możliwość narzędzi do maksimum.
Dzięki równoległości, w ciągu tego samego przedziału czasu jesteś w stanie przetworzyć wielokrotnie więcej i szybciej niż przy użyciu tradycyjnych narzędzi np. Pandas w Pythonie. Już w 2014 roku Apache Spark wygrał konkurs na najszybsze przetwarzanie danych w technologii Big Data.
Czas jest najcenniejszym zasobem, jaki mamy. Nie ważne czy działasz w chmurze, gdzie płacisz za każdą minutę wykorzystania zasobów czy on-premise. W obu wypadkach długie użycie zasobów zwiększy koszt rozwiązania.
- On-Premise: Tutaj nie płacisz za minutę jak w chmurze, ale każda minuta obciążająca procesor zabiera, a raczej blokuje zasoby dla innych systemów. Firma musi dokupić hardware, żeby poradzić sobie z długim przetwarzaniem. Dzięki Big Data możesz lepiej wykorzystać dostępną moc obliczeniową, co obniży koszty firmy.
- Chmura publiczna: Za każdą minutę płacisz, więc im dłużej coś działa, tym jest bardziej kosztowne. Bardzo często, jeśli proces przetwarzania danych jest zoptymalizowany, opłaca się wykupić droższy klaster (więcej CPU i RAM), dzięki temu czas wykonania będzie krótszy a tym samym niższe koszty.
Question Authority
Moim celem jest wzbudzenie w tobie metody podejmowania decyzji opartej na pytaniach. Jestem zwolennikiem metody „Question Authority„. Jeśli jesteś na meetingu i ktoś twierdzi, że tak jest najlepiej i powinniśmy użyć technologii x … to zadaj pytanie, dlaczego….a czy nie da się tego zrobić z y…?
Każda technologia lub narzędzie zostało zaprojektowane do rozwiązania konkretnego problemu. I najlepiej się sprawdza w kilku scenariuszach. Oczywiście może być w stanie zaoferować dużo więcej funkcjonalności, ale czy na pewno pasuje do twojego problemu. Sprawdź, zweryfikuj i pytaj.
Lista pytań wartych rozważenia
Jak będziemy używać dane?
Jakie typy operacji będziesz na nich wykonywał?
Jaka jest struktura danych?
Czy potrzeba skomplikowanej transformacji danych?
Jaka jest jakość danych?
Czy dane są ustrukturyzowane i gotowe do użycia
Jak dużo typów danych mamy?
Alternatywy dla Big Data
Jeśli nie Big Data to co? A co mam zrobić, kiedy mam kilkadziesiąt GB i przetwarzam je od czasu do czasu? A co jak potrzebuję tylko prostej transformacji, np. dodaj lub usuń kolumnę? Twoja sytuacje zależy od tego, czy jesteś on-premise czy w chmurze. Bez względu na to gdzie są twoje dane, będziesz potrzebował kilku elementów.
- Miejsca gdzie będziesz składował dane.
- Mocy obliczeniowej, czyli CPU które wykona twój kod.
- Docelowego miejsca z danymi uporządkowanymi.
- Narzędzia, które pomoże zrobić analizę.
- Narzędzia do wizualizacji wyników.
Więc jeśli Big Data jest zbyt mocnym narzędziem, to może wystarczy wirtualna maszyna i baza danych. Opcji jest na tyle dużo, że nie będę się starał podać całej listy rozwiązań ponieważ mogą one tylko pasować do jakiegoś pojedynczego scenariusza. Najważniejsze żebyś upewnił się czy na pewno potrzebujesz dużego i skomplikowanego narzędzia, jeśli twoje wymagania są proste?
Przykłady
Poniżej znajdziesz przykłady, usług w chmurze Azure, które mogą być przydatne do przechowywanie i przetwarzania danych.
1. Relacyjne bazy danych
- Azure SQL Database
- Azure Database MySQL
- Azure Database PostreSQL
- Azure Database MariaDB
2. Analityka danych
- Azure Synapse Analytics
- Azure Data Lake
- Azure Data Expolorer
- Azure Analysis Services
- HDInsight
- Azure Databricks
3. Magazyn klucz/wartość
- Azure Cosmos DB Table API
- Azure Cache for Redis
4. Baza danych dokumentów
- Azure Cosmos DB SQL API
5. Baza kolumnowa
- Azure Cosmos DB Cassandra API
- HBase in HDInsight
6. Baza grafowa
- Azure Cosmos DB Gremlin API
- SQL Server
7. Bazy danych aparatu wyszukiwania
- Azure Search
8. Bazy danych szeregów czasowych
- Azure Time Series Insights
9. Magazyn obiektów
- Azure Blob Storage
- Azure Data Lake Gen2
10. Udostępnione pliki
- Azure Files
Mam nadzieję, że ten prosty model wyjaśnił Ci czym jest Big Data i pozwoli w rozsądnym dobrze narzędzi. Jeśli odpowiednio podejdziesz do problemu to w długim terminie oszczędzisz czas i pieniądze.
Daj znać jak często obserwujesz złe dobranie technologii do problemu?