
| BARDZO DUŻE DANE Ostatnio w projekcie głowimy się jak zasilić tabele Feature Store w Databricksach. Nie byłoby w tym nic trudnego gdyby nie olbrzymia ilość kolumn. Na wejściu mamy cirka 4000 kolumn (100 tabel), a do każdej kolumny musimy doliczyć po 20-30 statystyk – jak się domyślasz docelowo będzie sporo. Taka ciekawostka – testowałem ile Feature Table jest w stanie wytrzymać – okazuje się, że płacze przy 10,000 kolumn. Musimy więc pójść w wiersze, a nie kolumny bo będzie tego za dużo. Zobaczymy jak nam pójdzie. 😁 Trzymaj kciuki.Trafiłem na taki artykuł Zacha Wilsona, były inżynier z Facebooka, który opisał jak radzili sobie z > 100TB (50 miliardów wiadomości). Polecam się zapoznać. How To Optimize 100TB Data PipelinesDatabricks Feature Store |
| OPTYMALIZACJA TABEL DELTA POD POWERBI W Maju pracowałem nad jednym PoC dla klienta, celem było pobranie danych z MS Dynamics – model danych był w Common Data Model, o tym powinien napisać artykuł bo ten standard będzie się pojawiał w różnych projektach. Klient chciał testować raporty w Power Bi na danych w Lakehouse, i dla porównania wykorzystał Databricks Warehouse i Synapse (teraz to Fabric). I tutaj optymalizacja danych w Delta jest bardzo ważna. Poniżej wideo podpowiadające jak to zrobić. Spark Data Engineering Patterns Optimizing Delta Tables for Power Bi in Microsoft Fabric |
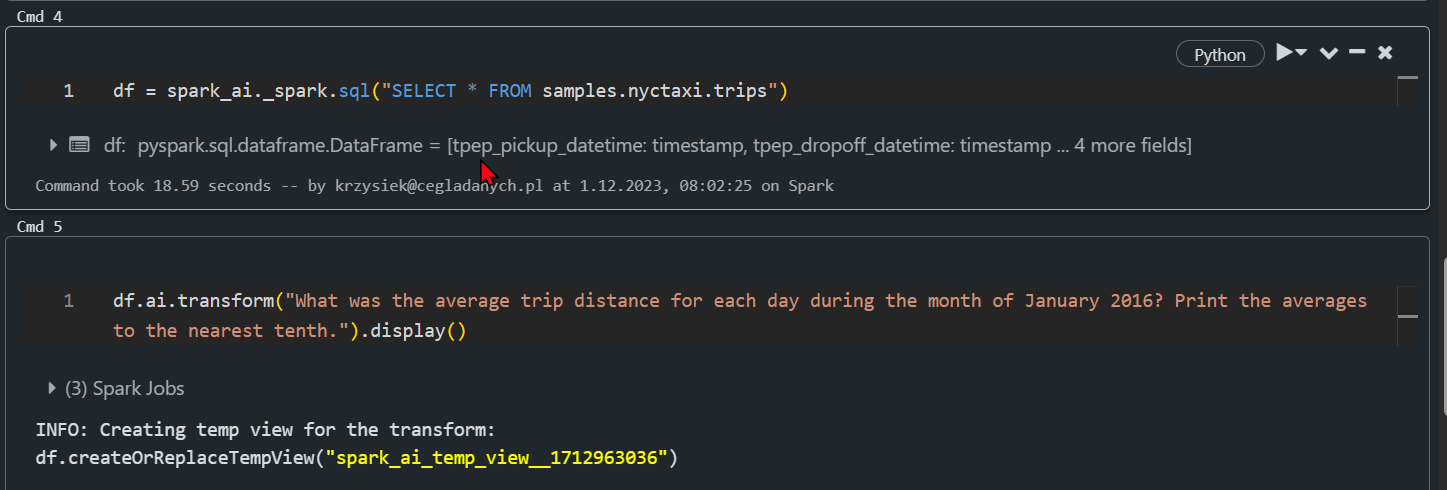
| OPEN AI W DATABRIKCKS Niedługo nie trzeba będzie pisać kodu SQL, żeby wykonać analizę danych. Jest SDK, które umożliwia analizę danych pisząc tekst po angielsku. Z tego co widzę i testuję działa z GPT-4, próbuję odpalić na wersji darmowej, ale jak na razie krzyczy, na wersji darmowej. 😂 jeszcze sprawdzę dostępne modele w OpenAI, a nuż zadziała. Retrying langchain.chat_models.openai.ChatOpenAI.completion_with_retry.<locals>._completion_with_retry in 4.0 seconds as it raised RateLimitError: You exceeded your current quota, please check your plan and billing details.. RateLimitError: You exceeded your current quota, please check your plan and billing details. English SDK for Apache Spark |
 |
| SPARK FUNKCJE NA KOLUMNIE Dla przypomnienia zebrałem wszystkie funkcje Dataframe jakie możesz wykonać na kolumnie. Lubię mieć swoje przykłady pod ręką, a nie tylko googlować. Co swoje to swoje 😁 alias(*alias, **kwargs) Zwraca kolumnę z nową nazwą lub nazw (w przypadku wyrażeń zwracających więcej niż jedną kolumnę, takich jak explode).asc() Zwraca kolumnę posortowaną rosnąco asc_nulls_first() Zwraca kolumnę posortowaną rosnąco. W pierszej kolejności będą nulle….. apache-spark-operacje-na-kolumnach |