
Jak sprawdzić jakość danych w Databricks i to zautomatyzować.
Nie martw się jest nowe narzędzie od Databricks i bardzo Ci pomoże w kontroli jakości.
Bardzo ważny temat wchodzący w skład testowania. Samo testowanie to bardziej skomplikowany aspekt inżynierii, ale jakość danych to kawałek łatwy to ugryzienia. Na szczęście nowe narzędzie od Databricks wydaje się być proste i łatwe w użyciu. Jeszcze nie miałem okazji przetestować go produkcyjnie, ale zamierzam to zrobić najszybciej jak się da.
https://github.com/databrickslabs/dqx/tree/main
Jest to prosty framework walidacji danych w Dataframe. Umożliwia on walidację jakości w czasie rzeczywistym podczas przetwarzania danych.
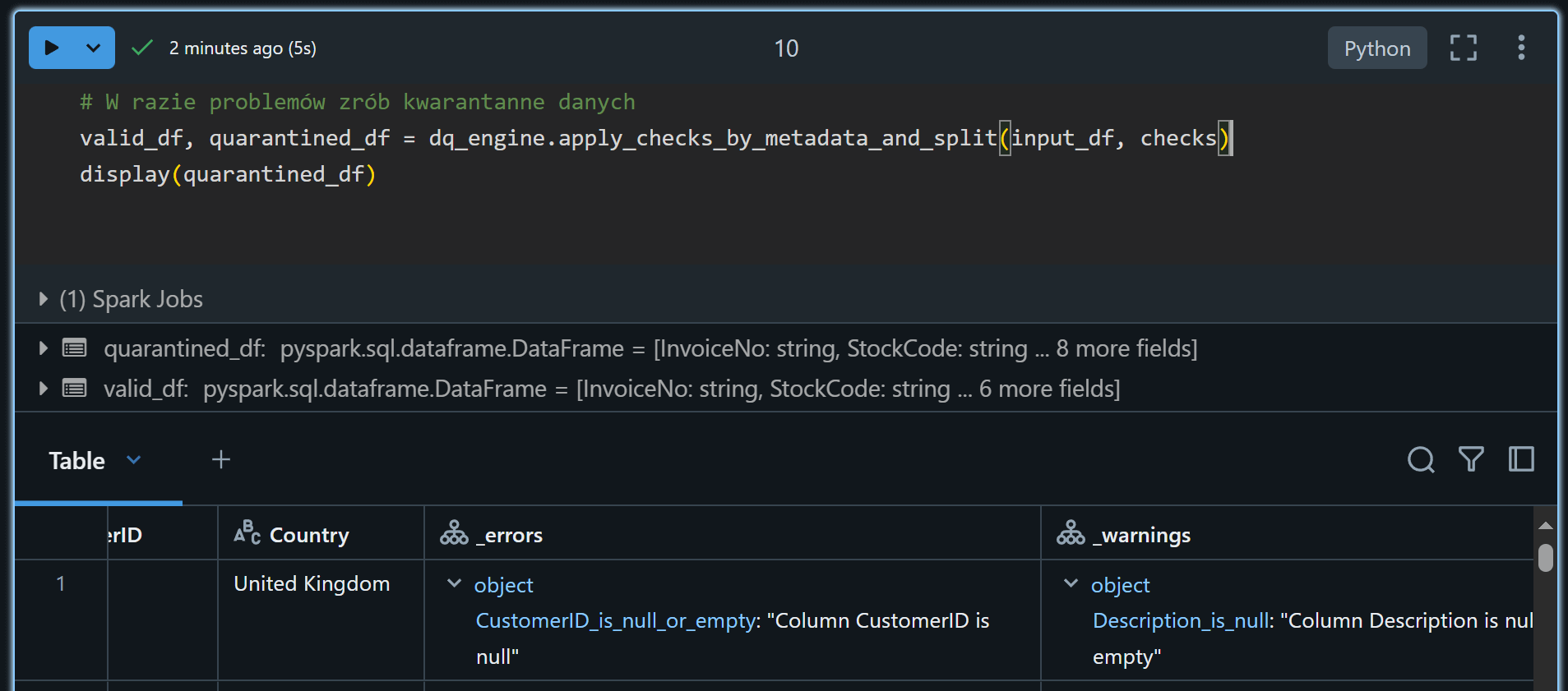
Powie Ci w których wierszach i konkretnych kolumnach jest problem
Nieprawidłowe dane można poddać kwarantannie.
Wprowadź walidację danych najwcześniej jak się da w procesie zasilania. Podstawowa zasada głosi nie wpuszczaj złych danych na produkcję, im wcześniej wyłapiesz błędy tym lepiej dla całego procesu.
Co potrafi Databricks DQX
- Informacja o powodzie niepowodzenia kontroli.
- Niezależny od formatu danych (działa na Spark DataFrames).
- Obsługa Spark Batch i Streaming, w tym DLT (Delta Live Tables).
- Różne reakcje na nieudane sprawdzenia, np. usunięcie, tagowanie lub poddanie kwarantannie nieprawidłowych danych.
- Obsługa poziomów kontroli: ostrzeżenie (zaznacz) lub błędy (zaznacz i nie propaguj wierszy).
- Obsługa reguł jakości na poziomie wierszy i kolumn.
- Profilowanie i generowanie kandydatów do reguł jakości danych.
- Sprawdza definicję jako kod lub konfigurację.
- Podsumowanie walidacji i panel jakości danych umożliwiający identyfikację i śledzenie problemów z jakością danych.
Instalacja
Instalacja może się odbyć przy użyciu pip, chociaż ta metoda jest bardziej do testów na devie. Produkcyjnie jest dostępna biblioteka do zainstalowanie przez Databricks CLI. Tak porządnie zainstalowana będzie służyła długo i szczęśliwie.
W pierwszej fazie importujesz wymagane biblioteki:
from databricks.labs.dqx.profiler.profiler import DQProfiler
from databricks.labs.dqx.profiler.generator import DQGenerator
from databricks.labs.dqx.profiler.dlt_generator import DQDltGenerator
from databricks.sdk import WorkspaceClient
W drugiej fazie możesz użyć automatycznego profilowanie danych, profiler policzy najważniejsze statystyki o danych. Wystarczy że podasz mu Dataframe jako parametr a on zrobi resztę.
input_df = spark.read.format("csv").option("header","True").load("dbfs:/databricks-datasets/online_retail/data-001/data.csv")
ws = WorkspaceClient()
profiler = DQProfiler(ws)
summary_stats, profiles = profiler.profile(input_df)
display(summary_stats)
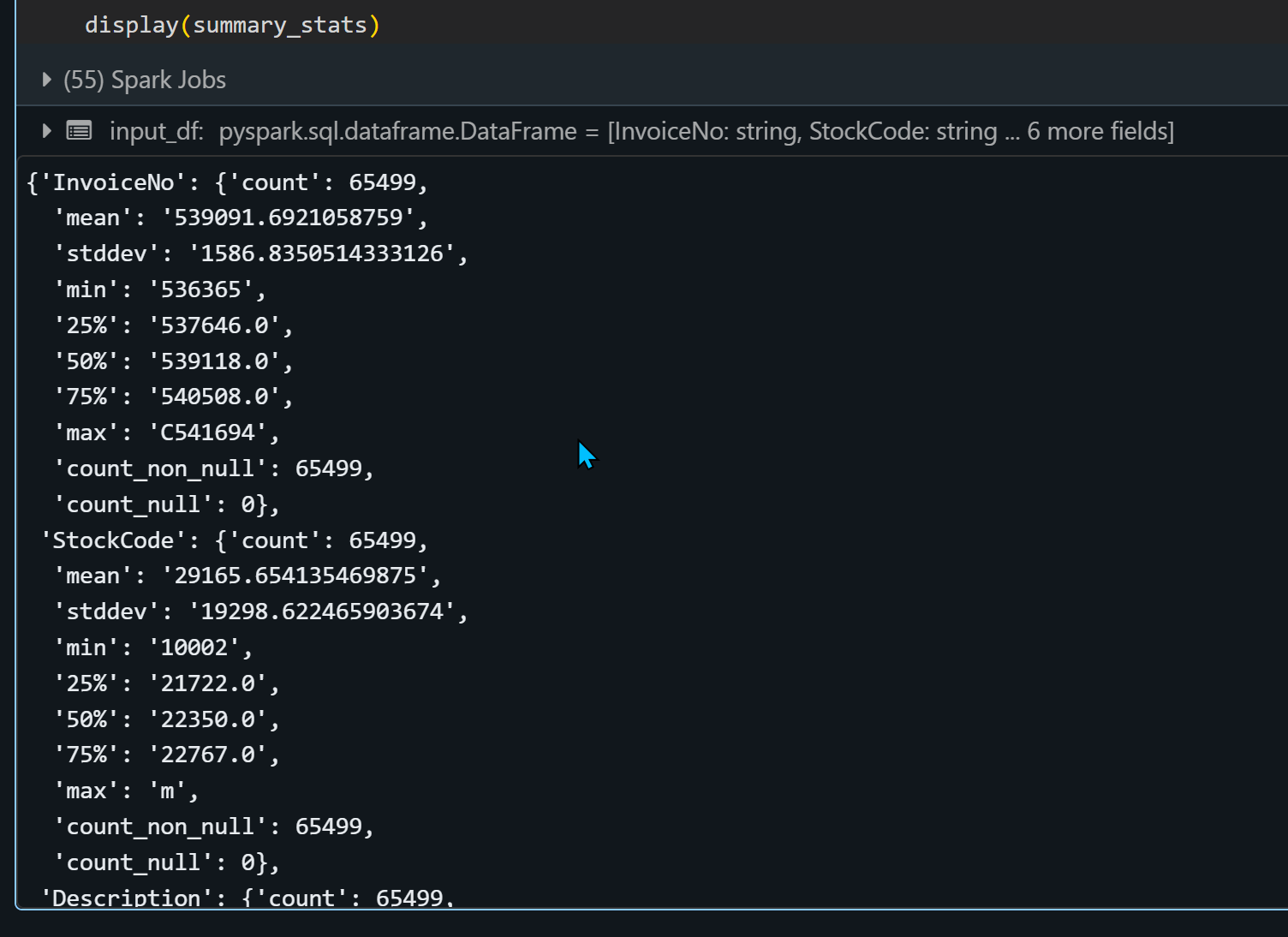
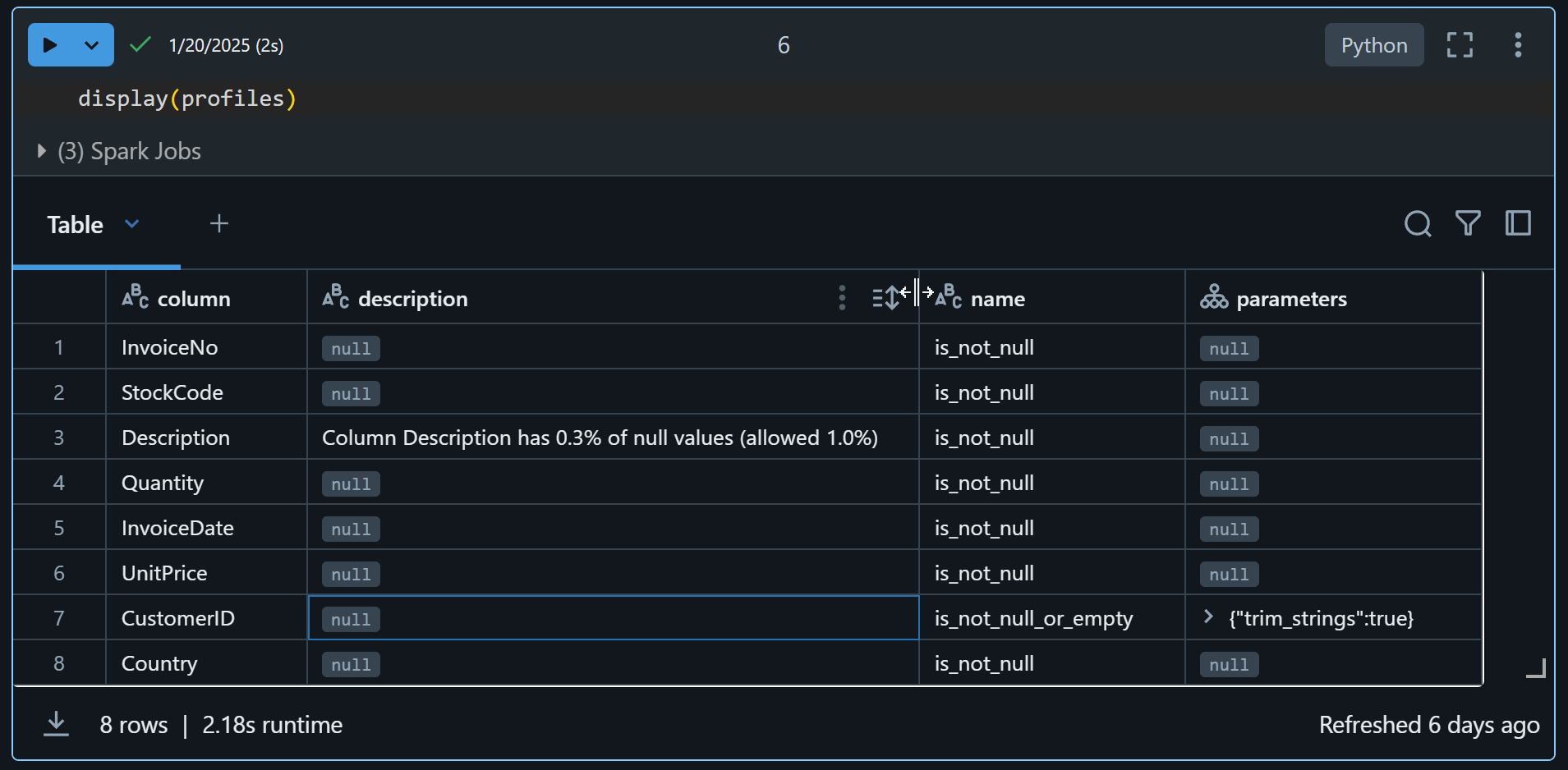
Profil jest dostępny jako dataframe. Zauważ na przykładzie poniżej dodał opis do kolumny Description – podaje procentowy ilość nulli
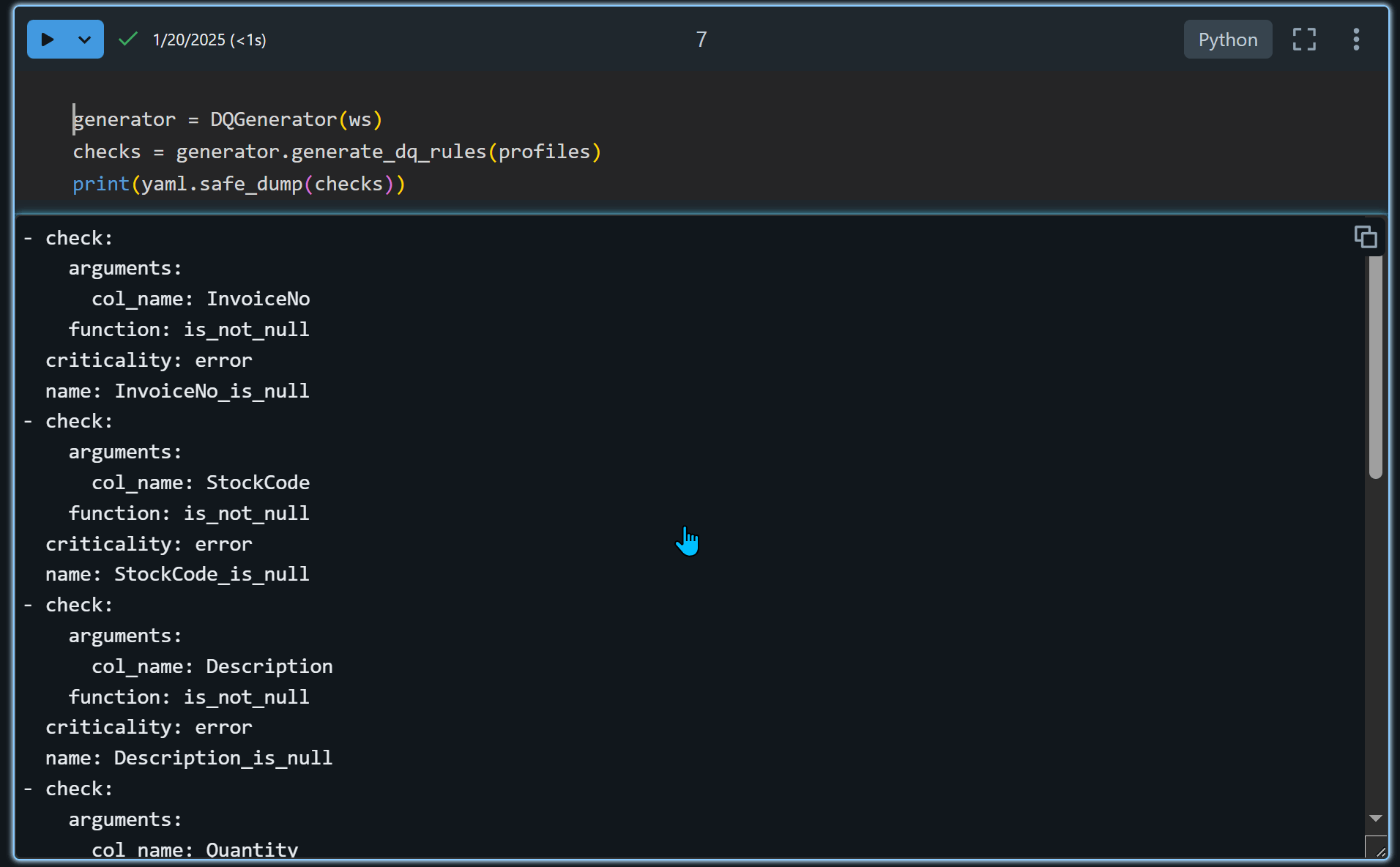
Generowanie konfiguracji yml
Narzędzie jest bardzo pomocne i na podstawie profilu danych wygeneruje plik konfiguracyjny.
generator = DQGenerator(ws)
checks = generator.generate_dq_rules(profiles)
print(yaml.safe_dump(checks))
Szczegóły i przykłady zajdziesz w repo.
Jeśli dane nie spełniają wymagań możesz je wrzucić do dataframe jako kwarantanna i zadecydować co z nimi zrobić.
Ważna uwaga!!!
Jest to nowe narzędzie pracę nad nim rozpoczęto w Kwietniu 2024, a pierwszy realese 0.1.0 w Styczniu 2025, więc jest to jeszcze nie sprawdzone w bojach i świeżutkie. Miej to na uwadze zanim wykorzystasz gdzie się da. Ja bym rozpoczął od najmniej krytycznych elementów i jeśli okaże się stabilne wprowadzał stopniowo.
Daj znać jak działa u Ciebie.