

Nie znam rozwiązania gdzie nie trzeba połączyć jakiś tabel. Możesz pracować przy różnych modelach architektonicznych takich jak Lakehouse czy Warehouse bądź innym cudzie technologii. W każdym przypadku pracując z Apache Spark będziesz łączył(ła) tabelę. Małe duże, rozproszone czy nie jakoś join trzeba zrobić. Najczęściej po prostu robisz join i nic innego Cię nie interesuje. Spark decyduje co i jak ma robić a ty siedzisz i czekasz.
W większości przypadków jest to ok i Spark dobrze połączy tabele, ale życie nie jest takie łatwe na jakie wygląda 😁 czasami trzeba się namęczyć. Będą przypadki gdzie cały proces będzie bardzo wolny. W takich przypadkach dobrze wiedzieć
- jak zoptymalizować join
- wiedzieć co dzieje się pod maską podczas takiej operacji.
Poniżej lista typów połączeń w Sparku, i szczegóły jak działają.
Typy Łączników
- Połączenia wewnętrzne (inner joins): zachowaj rzędy z kluczami, które wychodzą po lewej i prawej stronie
- Połączenia (outer join) zewnętrzne: zachowuje wiersze istniejące w lewym lub prawym zestawie danych
- Lewe połączenia zewnętrzne (left outer join): zachowaj wiersze z kluczami w lewym zestawie danych
- Prawe połączenia zewnętrzne (right outer join): przechowuj wiersze z kluczami w prawym zbiorze danych
- Lewe pół-złączenia (left semi join): trzymaj wiersze po lewej, a tylko po lewej, gdzie klucz pojawia się w prawym zbiorze danych
- Lewy łącznik anty (left anti join): trzymaj wiersze po lewej i tylko po lewej stronie, gdzie nie pojawiają się w prawym zbiorze danych
- Połączenia naturalne (natural join): wykonaj połączenie, domyślnie dopasowując kolumny między dwoma zestawami danych o tych samych nazwach
- Połączenia krzyżowe (cross join): dopasowuje każdy wiersz w lewym zbiorze danych z każdym rzędem w prawym zbiorze danych.
Broadcast Hash Join
- Opis: Jest to najszybszy typ złączenia w Sparku, stosowany, gdy jeden z zestawów danych (zazwyczaj mniejszy) może zmieścić się w pamięci. Wielkość RAM dla broadcast join jest konfigurowalna. Domyślnie jest to 10MB. Jeśli chcesz to zwiększyć to użyj spark.sql.autoBroadcastJoinThreshold. Jeśli ustawisz tą wartość jako -1 to broadcast zostanie wyłączony. Do włączenia potrzebujesz słowo klucz = BROADCAST, BROADCASTJOIN lub MAPJOIN.
- Mniejszy zestaw danych jest rozsyłany do wszystkich węzłów roboczych, co pozwala każdemu węzłowi na lokalne połączenie z partycją większego zestawu danych. Jeśli Dataframe będzie za duży to może dojść do OOM – out of memory error.
- Większy zestaw danych jest partycjonowany po kluczu połączenia.
- Zaleta to unikanie Shuffle, czyli kosztownego przesyłania danych.
- Dane nie muszą zostać posortowane co przyspiesza operacje
- Spark planuje BHJ kiedy ma klucze (equi join) do połączenia i wybrane typy łącznia to (cross, inner, left outer, left semi)
- Możesz użyć opcji Hint czyli podpowiedzieć Sparkowi jak ma połączyć tabele. Uwaga nie zawsze posłucha kiedy podasz mu różne typy połączeń, Spark wybierze według swoich priorytetów:
- BROADCAST
- MERGE
- SHUFFLE_HASH
- SHUFFLE_REPLICATE_NL
- Przykład użycia: Idealny w sytuacji gdy masz do połączenia duża tabelę z małą np. znacznie mniejszą tabelą konfiguracyjną gdzie tylko wyciągasz jakieś dane referencyjne. Poniżej przykład meto jak sprawdzić ile miejsca Dataframe będzie zajmował w pamięci.
Wielkość Partycji
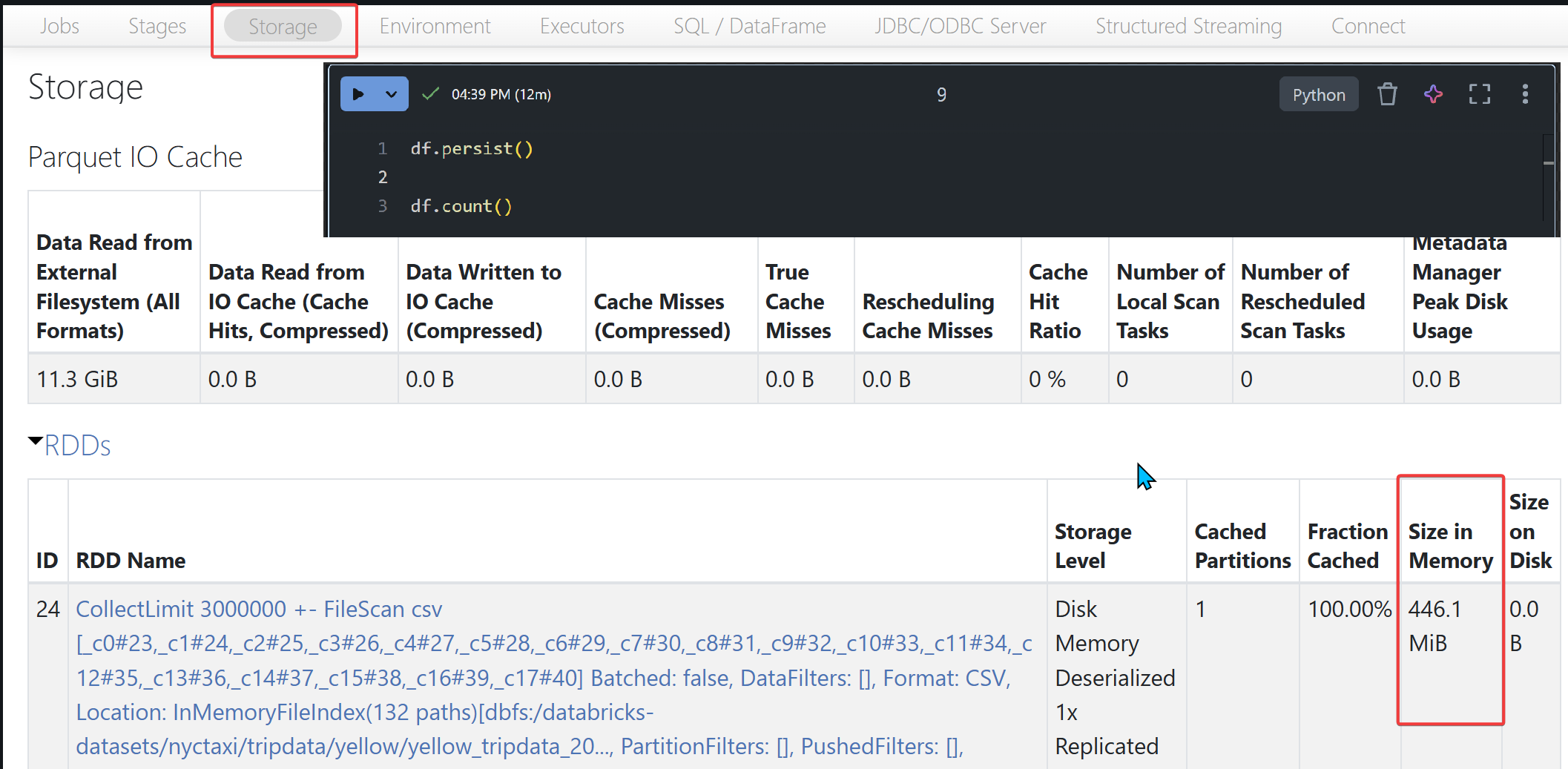
Jak sprawdzić wielkość Dataframe w pamięci, jest na to kilka sposobów, są lepsze i gorsze, nie każdy da super precyzyjne dane, ale dla samej optymalizacji pod join nie muszą zgadzać się co do bajta.
Najprostsza metoda to
- Stwórz Dataframe
- df.persist(StorageLevel.DISK_ONLY) wykorzystaj wbudowany mechanizm zapisu danych, zostanie on zapisany na dysku
- Dataframe.count() – wykonaj jakąś akcję to zmaterializuje Dataframe
- Wejdź na Spark UI / Storage – tam znajdziesz informację ile zajmuje miejsca na dysku.

Alternatywa to SizeEstimator
def estimate_dataframe_size(df):
# Konwersja do RDDD
rdd = df.rdd
# Uzycie sys.getsizeof
estimated_size = rdd.map(lambda x: sys.getsizeof(x)).sum()
# Przelicz na MB
size_in_mb = estimated_size / (1024 * 1024)
return f"{size_in_mb:.2f} MB"
Konwersja do Pandas i wywołanie metody
pandas_df = df.toPandas()
df.info()
Shuffle Sort Merge Join
- Opis: Jest to standardowa metoda złączenia, która sortuje oba zestawy danych na podstawie kluczy. Jest najczęściej używana przy dwóch dużych obiektach. Składa się z trzech faz.
- Faza Shuffle: Tabele zostaną podzielona na partycje według klucza wybranego do połączenia. Spark musi zadbać o to żeby w każdy klucz znalazł się w tej samej partycji.
- Faza Sortowania: Dane zostaną posortowane wewnątrz każdej partycji. W obu setach będą te same klucze co ułatwi połączenie w kolejnym etapie.
- Faza Łączenia Merge: Łączenie zestawów danych. Iteracyjnie leci po wierszach i łączy pasujące klucze.
- Działają dla typów equi join gdzie po obu stronach są pasujące klucze.
- Adaptive Query Execution wykona konwersje do shuffle hash join jeśli partycje po operacji shuffle są mniejsza niż ustawiona wartość
spark.sql.adaptive.maxShuffledHashJoinLocalMapThreshold. Jeśli ta wartość jest większa odspark.sql.adaptive.advisoryPartitionSizeInBytesa reszta partycji nie jest większa odmaxShuffledHashJoinLocalMapThreshold, join w takiej sytuacji spark wybierze shuffled hash join bez względu na wartość konfiguracjispark.sql.join.preferSortMergeJoin. - Przykład użycia: Odpowiednia dla dużych zestawów danych, gdzie obie strony mogą być sortowane i scalane efektywnie. Jest szczególnie skuteczna przy pracy z danymi posortowanymi lub gdy wykonywane są wielokrotne złączenia. Warto sprawdzić jaka jest wartość konfiguracji dla
spark.sql.join.preferSortMergeJoin.
Shuffle Hash Join
- Opis: Oba łączone zbiory są partycjonowane według wybranych kluczy. W kolejnym etapie dane są przesyłane do węzłów, Spark dba o to żeby rekordy z tym samym kluczem znalazły się w tej samej partycji. Potem Spark wybiera mniejszy z dwóch zbiorów danych i tworzy tablicę (hash table). Proces wymaga więcej pamięci niż Broadcast Hash Join ze względu na przesyłanie wszystkich danych.
- Proces składa się z następujących kroków:
- Partycjonowanie: Oba zbiory są dzielone według klucza tak aby każda partycja zawiera rekordy z tym samym kluczem.
- Shuffle: Dane są przysyłane do węzłów, które będą obsługiwać konkretne partycje. Umożliwia to połączenie rekordów ze wspólnym kluczem.
- Hash Join: Spark wybiera mniejszy zbiór (w obrębie partycji) i tworzy w pamięci tablicę. Drugi, większy zbiór jest “przeszukiwany” w pamięci, a pasujące klucze są łączone (join) w ramach tej samej partycji.
- W przeciwieństwie do Sort Merge Join, Shuffle Hash Join nie wymaga sortowania danych, co w niektórych przypadkach może być szybsze.
- Przykład użycia: Dobrze sobie radzi z dużymi zbiorami danych. SHJ jest mniej wydajne niż SMJ, ale można go używać, gdy sortowanie nie jest możliwe. Możesz spróbować wywołać go hintem i w ten sposób sprawdzić czy to będzie szybsze.
Broadcast Nested Loop Join
- Opis: Ta metoda łączenia jest podobna do Broadcast Hash Join. W tej metodzie jeden zestaw danych (mniejszy) jest rozsyłany do wszystkich węzłów, a następnie każdy rekord z jednego datasetu jest porównywany z drugim. W uproszczeniu taka zagnieżdżona pętla. Ta metoda nie wymaga sortowania.
- Wspiera on typy equi i nie equi joins.
- Składa się z dwóch faz
- Faza broadcast. Przesyłanie mniejszego setu do workerów.
- Faza Loop. Czyli iteracja po większym datasetcie i próba dopasowania rekordów z mniejszego. Ponieważ jest to pętla sam mechanizm jest wolniejszy, szczególnie jeśli danych jest dużo.
- Spark użyje BNLJ kiedy nie ma kluczy ( none equi „<=”, lub „OR”) i używasz jednego z typów połączeń (cross, left anti, left outer, left semi, righ outer)
- Przykład użycia: Efektywna w scenariuszach, gdzie jeden zestaw danych jest wystarczająco mały, aby zmieścić się w pamięci, ale druga strona może nie mieć odpowiedniego klucza do haszowania. Szczególnie w sytuacji gdzie potrzeba none equi join – np „>=” lub „BETEEN” wtedy spark nie może użyć BHJ czy SMJ. Tutaj czasami lepiej ty było zamienić none equi join na equi join.
- Jeśli używasz operatora „OR” to możesz podzielić join na dwa osobne w jednym robisz equi join („=”) a potem zrobić union.
- Sprawdź spark.sql.autoBroadcastJoinThreshold jeśli ta wartość jest za mała to Spark może przejść na użycie SMJ.
Shuffle-and Replicated Nested Loop Join
- Opis: Ten join jest wykorzystywany przy połączniu typu Cartesian. Replikuje on partycje obu zbiorów danych w całym klastrze. Po to żeby mógł połączyć wszystkie rekordy z dwóch zbiorów. Zostanie on użyty kiedy Spark nie będzie miał kluczy (none equi join) lub jeśli dasz mu hint (SHUFFLE_REPLICATE_NL).
- Jest to bardzo kosztowna operacja ponieważ każdy wiersz musi być dopasowany do każdego wiersza z drugiego zestawu.
- Składa się z kilu faz:
- Replikacji, to nie to samo co Shuffle tutaj wszystkie partycje są przesyłane, każdy wykonawca dostaje partycje z obu zestawów.
- Potem leci pętla i dopasowuje każdy wiersz z obu zestawów. Matematycznie będzie to x * y.
- Łączy elementy zarówno złączenia przesyłanego, jak i pętli zagnieżdżonej. Najpierw replikuje jeden ze zbiorów danych na węzłach podczas przesyłania drugiego na podstawie kluczy złączenia, co pozwala na dopasowanie za pomocą pętli zagnieżdżonej.
- Przykład użycia: Zwykle stosowane przy skomplikowanych zapytaniach lub gdy inne strategie złączenia nie są stosowane ze względu na charakterystykę danych. Na szczęście połączenie typu cartesian są raczej rzadkie, a jak już musisz to musisz tylko będzie to drogo kosztowało. Więć używaj rozsądnie.
Czy często zdarza Ci się zmieniać typy podpowiadając Sparkowi?