
Apache Spark jest narzędziem bardzo skomplikowanym, i nie wielu z nas ma czasu na czytanie kodu źródłowego. Tego wszystkiego jest za dużo. Również podczas projektu nie ma za wiele czasu na dogłębna analizę. Zadbaj o to żeby uprościć sobie życie. Chciałem tutaj zebrać najważniejsze elementy z procesu optymalizacji. Mają one Ci pomóc w jak najszybszym podkręceniu procesu. Czasami skrócenie czasu lub zmniejszenie zużycia zasobów o 10-20% to bardzo dużo. Polecam szukać „quick wins” czyli najprostszych rozwiązań, które dadzą zauważalne rezultaty.
1. Układ danych (Data Layout)
Jeśli chodzi o składowisko danych to najbardziej optymalnym formatem jest Delta Lake. Ten format zapewni szybki odczyt i zapis danych. Samo wybranie formatu jednak nie wystarczy. Musisz pamiętać również o typie tabel, w Databricks masz do wyboru dwa typy Managed lub External. Każdy z tych typów ma swoje wady i zalety i musisz sprawdzić przed wyborem, które lepiej pasują do twojego problemu. W zależności od typów tabel i wersji Runtime musisz zwrócić uwagę na wielkość plików. Wersji Runtime 11.3 oraz tabel Managed wielkość plików zostanie obsłużona automatycznie. W pozostałych przypadkach musisz sam o to zadbać.
Samo użycie formatu delta nie jest rozwiązaniem wszystkich problemów. Kiedy zapisujesz pliki do delty wykorzystując różne metody (upsert =insert, update, delete) to ich ilość będzie coraz większa. Wraz z ich ilością spada wydajność odczytu.. Więc potrzebujesz regularnego procesu który będzie kompaktował pliki. Doczytaj o Deletion Vectors.
- Opis: Poprawa układu danych może znacząco wpłynąć na wydajność. Zaleca się przemyślane zaprojektowanie schematu tabel, aby minimalizować koszty związane z przetwarzaniem danych.
- Przykłady: Sprawdź czy wielkość plików w tabelach jest pomiędzy 128 MB a 1GB. Mniejsze pliki mogą być nie efektywnie szczególnie jeśli danych jest bardzo dużo. Możesz to zrobić w samym koncie magazynu lub przez Unity Catalog.
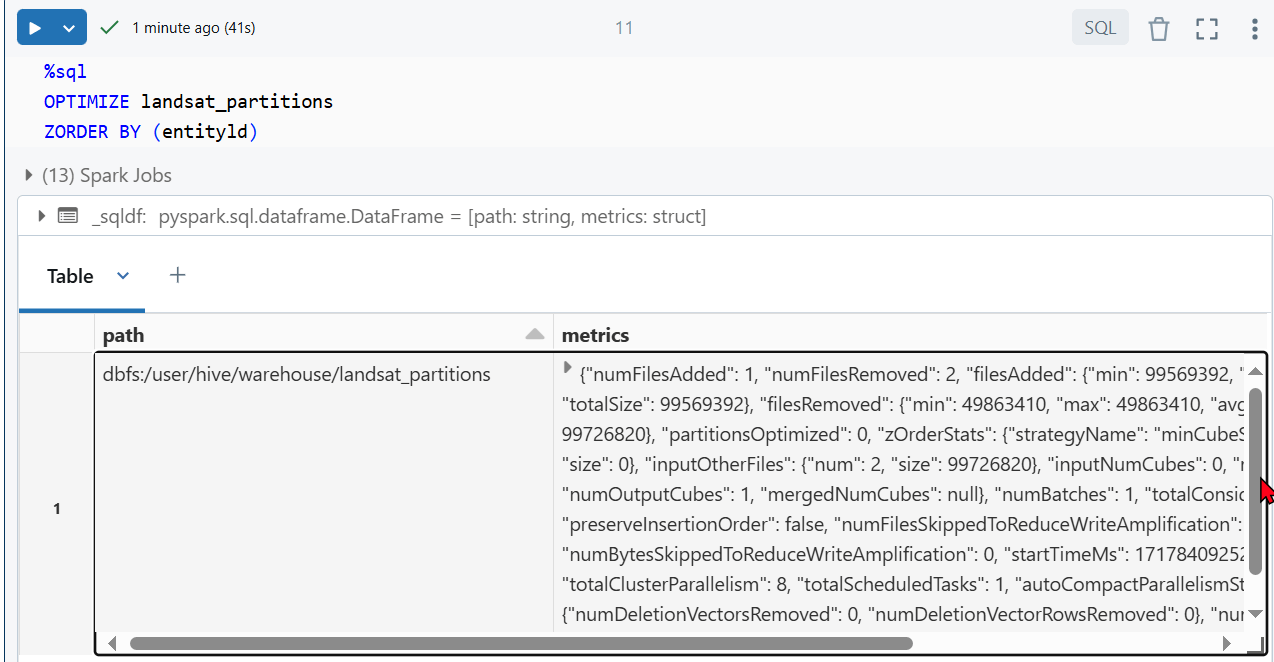
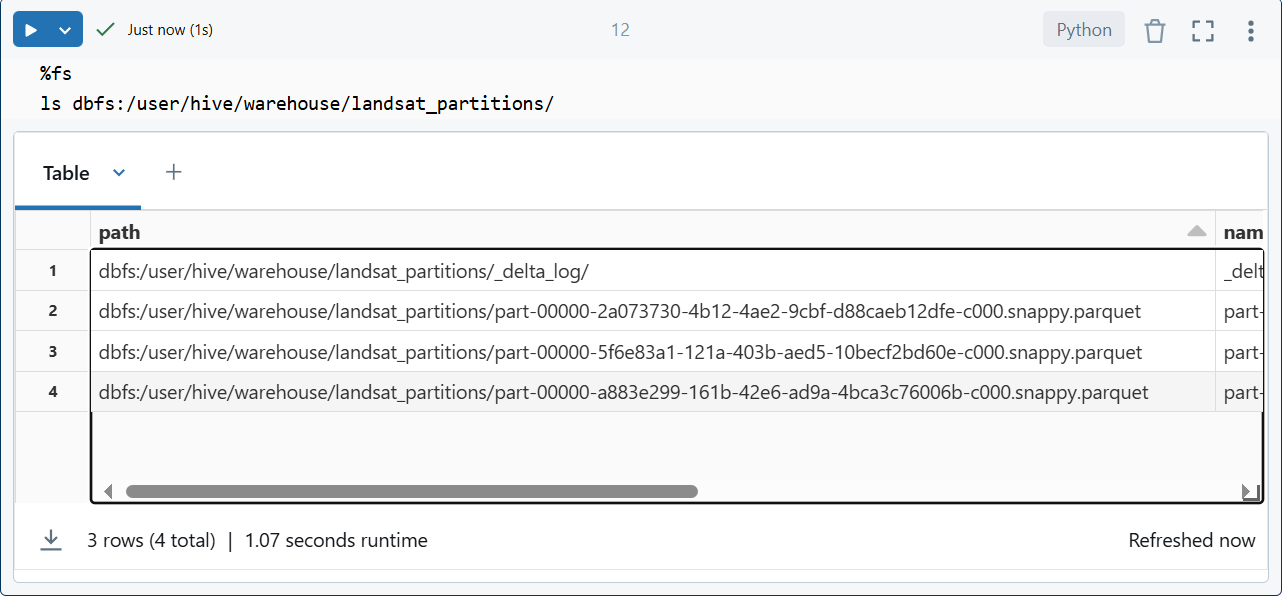
2. Optymalizacja i Z-order (Optimize & Z-order)
Kiedy plików jest za dużo to przeważnie są małe, a kiedy są małe to są wolne. Jak się domyślasz otwarcie 1000 małych plików będzie wolniejsze niż otwarcie 100 większych pomimo ich małości 😁. Więc regularnie trzeba je łączyć w większe (compacting). Do tego służy Optimize, który skompresuje pliki czyli mniejsze połączy w większe i do tego poukłada je w lepszym porządku co przyspieszy odczyt. Zapytasz – skąd mam wiedzieć że jest ich za dużo? Zadałeś świetne pytanie odpowiedz poniżej w zaleceniach.
- Opis: Optimize łączy małe pliki w większe i reorganizuje je.
- Z-ordering to technika używana do optymalizacji zapytań poprzez zgrupowanie powiązanych wartości w sąsiadujących blokach danych, dzięki temu Spark je szybciej wczyta.
- Zalecenia:
- Używać kolumn o wysokiej kardynalności.
- Nie używać więcej niż 4 kolumn w Z-ordering, aby uniknąć degradacji efektywności.
- Wielkość plików można konfigurować
delta.targetFileSize - Optymalizuj regularnie na osobnych Job klastrach, nie tych samych, na których przetwarzasz dane.
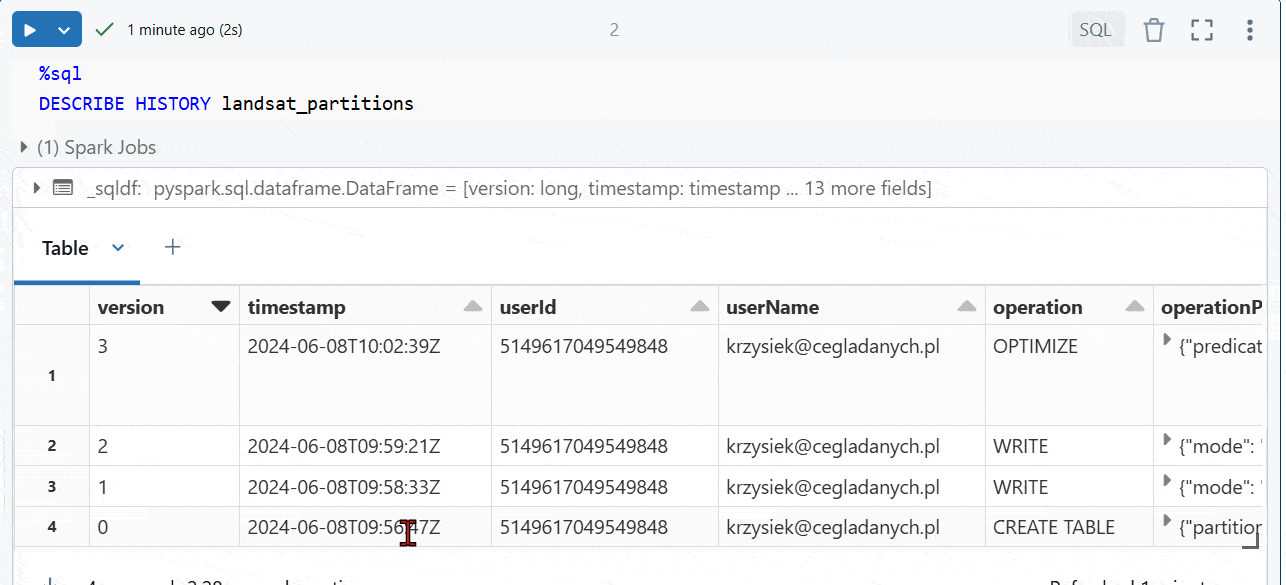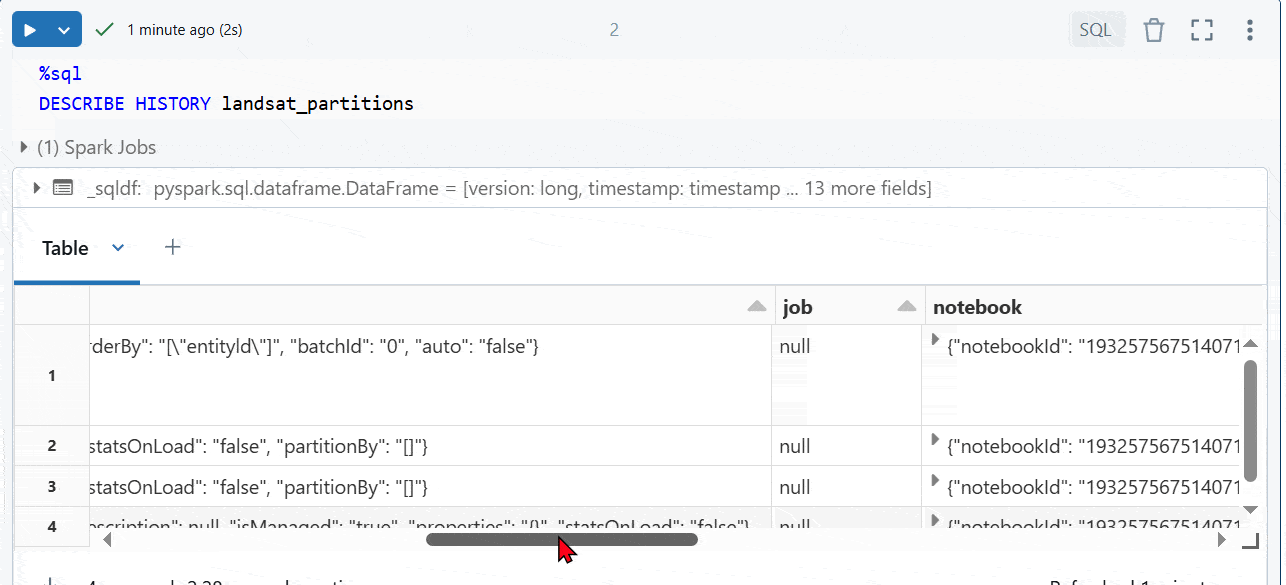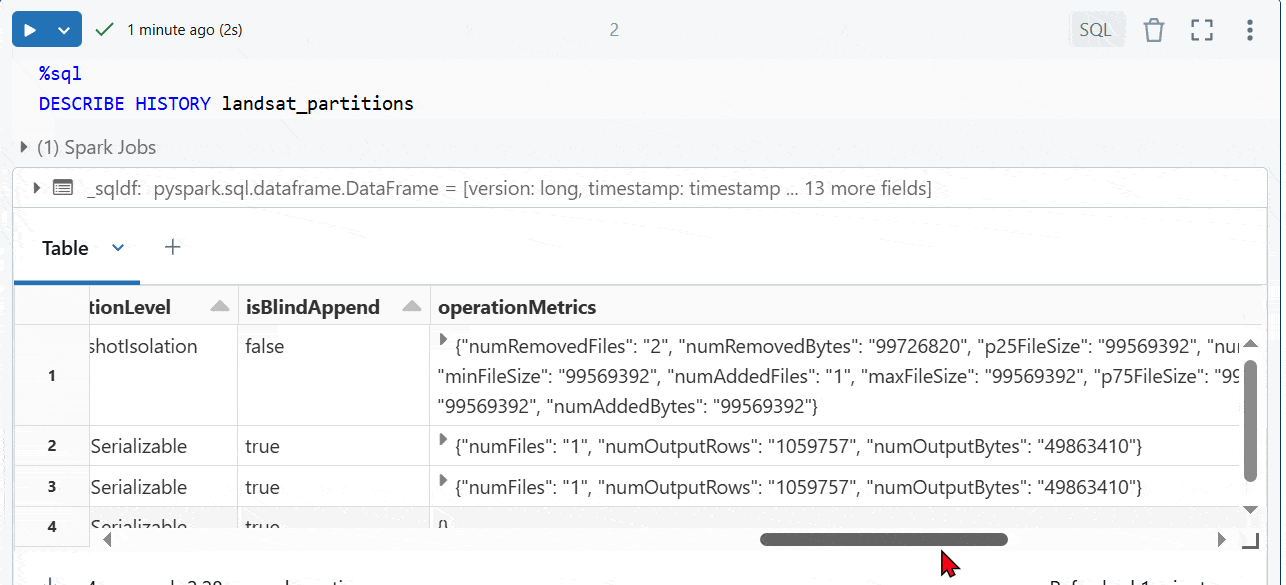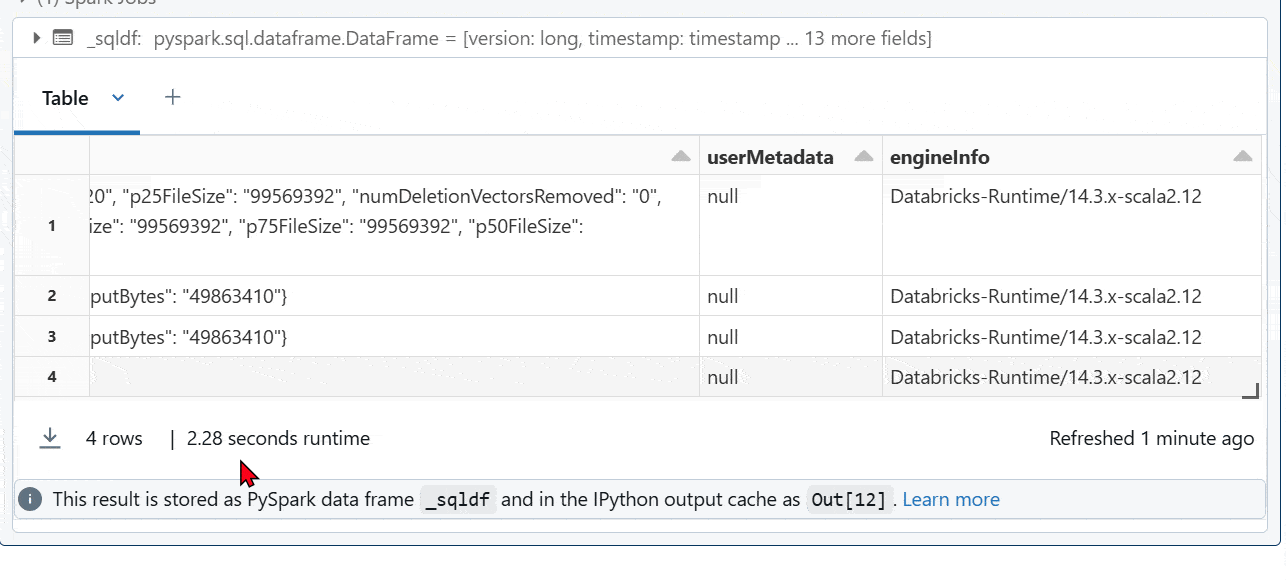
3. Automatyczna optymalizacja (Auto optimize)
Auto optymize kompaktuje pliki do 128MB. Tą wartość możesz zmienić i wybrać większe pliki jest to konfigurowalne. Automatyzacja jest uruchamiana przez trigger kiedy system wykryje tabela bądź partycje z minimalną ilością plików, oczywiście możesz to kontrolować przez spark.databricks.delta.autoCompact.minNumFiles
Jak zawsze trzeba przeczytać dokumentację i sprawdzić szczegóły. Bo źle skonfigurowane i źle dobrane może tylko pogorszyć performance. Ja bym się trzymał tego co rekomenduje Databricks przynajmniej w większości przypadków.
- Opis: Automatyczna optymalizacja (Auto optimize) obejmuje funkcje, takie jak optymalizacja zapisów i automatyczne kompaktowanie, które poprawiają wydajność zapytań.
- Zalecenia:
- Włączenie
delta.autoOptimize.optimizeWriteidelta.autoOptimize.autoCompact. - Użycie właściwości tabel, aby automatycznie dostosowywać rozmiar plików do specyficznych potrzeb.
- Włączenie
4. Partycjonowanie (Partitioning)
Partycjonowanie polega na podzieleniu danych na małe kawałki inaczej mówiąc na pogrupowaniu według jakiegoś klucza. Klucz powinien być dobrze dobrany pod twoje najczęstsze zapytania. Po jakich kluczach (kolumnach) najczęściej będziesz wyciągać dane. Być może pracujesz z danymi szeregów czasowych, więc partycjonujesz według roku, miesiąca i dnia, data jest dobrym typem do rozważenia. Polecam sprawdzić Liquid Clustering. Tradycyjne partycjonowanie staje się bardziej „legacy” może być bardziej problematyczne i trzeba do tego podejść bardzo ostrożnie.
- Opis: Partycjonowanie może przyspieszyć zapytania poprzez ograniczenie ilości przetwarzanych danych.
- Zalecenia:
- Partycjonowanie tabel powyżej 1 TB.
- Wybór kolumn o niskiej kardynalności jako kolumn partycjonujących (Customer ID raczej nie 🚫).
- Dane w jednej partycji powinny mieć około 1GB.

5. Dostrajanie rozmiaru plików (File size tuning)
Oprócz sztandarowych wielkości plików dostarczonych przez Auto-Optimize 128MB i Optimize 1GB masz dodatkową możliwość pełnej kontroli nad wielkością plików. To zadanie może zrobić Databricks za Ciebie, wystarczy wykorzystać poniższe konfiguracje.
- Opis: Dostosowywanie rozmiaru plików może poprawić wydajność zapisu i odczytu danych.
- Zalecenia:
- Ustawianie
delta.targetFileSizedla automatycznej optymalizacji. - Włączenie
delta.tuneFileSizesForRewrites, aby Databricks automatycznie dostosowywał rozmiary plików w oparciu o obciążenia.
- Ustawianie

6. Przetasowanie danych (Data Shuffling)
Do Shuffle dochodzi kiedy poszczególny nody (executory) muszą się wymienić danymi. Dochodzi to tego kiedy robisz jakiś join, groupBy czy jakąś agregację. Jak się domyślasz dane są podzielone na partycje i ich kawałki są rozrzucone po całym klastrze. Więc każdy worker musi się wymienić danymi z innymi workerami. I jest to bardzo kosztowne. Bardzo często nie jesteś w stanie tego uniknąć tzn nie wszystkie przypadki.
Optymalizacja join
Jeśli jedna tabela jest na tyle mała, że pomieści się w pamięci każdego z wykonawców to możesz ją przesłać czyli zrobić „Broadcast„.
- Opis: Przetasowanie danych jest kosztownym procesem, który można zoptymalizować, aby poprawić wydajność.
- Zalecenia:
- Użycie joinów haszujących (hash join) z broadcastem mniejszych tabel.
(duży_df.joins(broadcast(mały_df)) - Dostosowanie progów do broadcastowania większych tabel (np.
spark.sql.autoBroadcastJoinThreshold). - Jeśli używasz wykonawcy z RAM powyżej 32GB to możesz podkręcić BroadCastThreshold do 200MB
- Sam broadcast możesz wymusić Hints
- Sprawdź w planie wykonania czy jest SortMergeJoin czy HashMergeJoin
- Użycie joinów haszujących (hash join) z broadcastem mniejszych tabel.
set spark.sql.autoBroadcastJoinThreshold = 209715200 (200MB)
set spark.databricks.adaptive.autoBroadcastJoinThreshold = 209715200 (200MB)
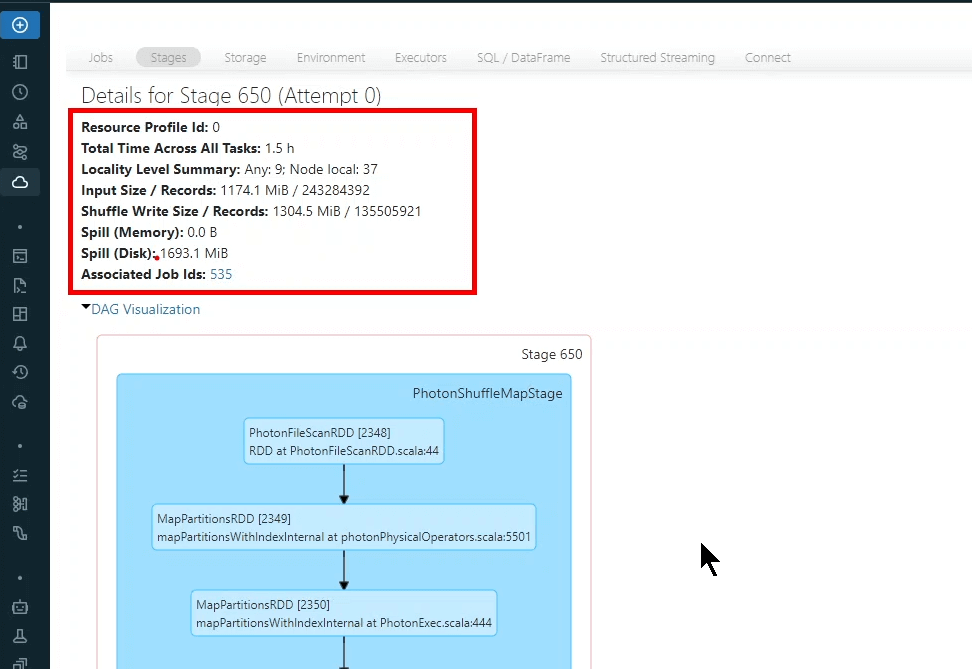
7. Przepełnienie danych (Data Spilling)
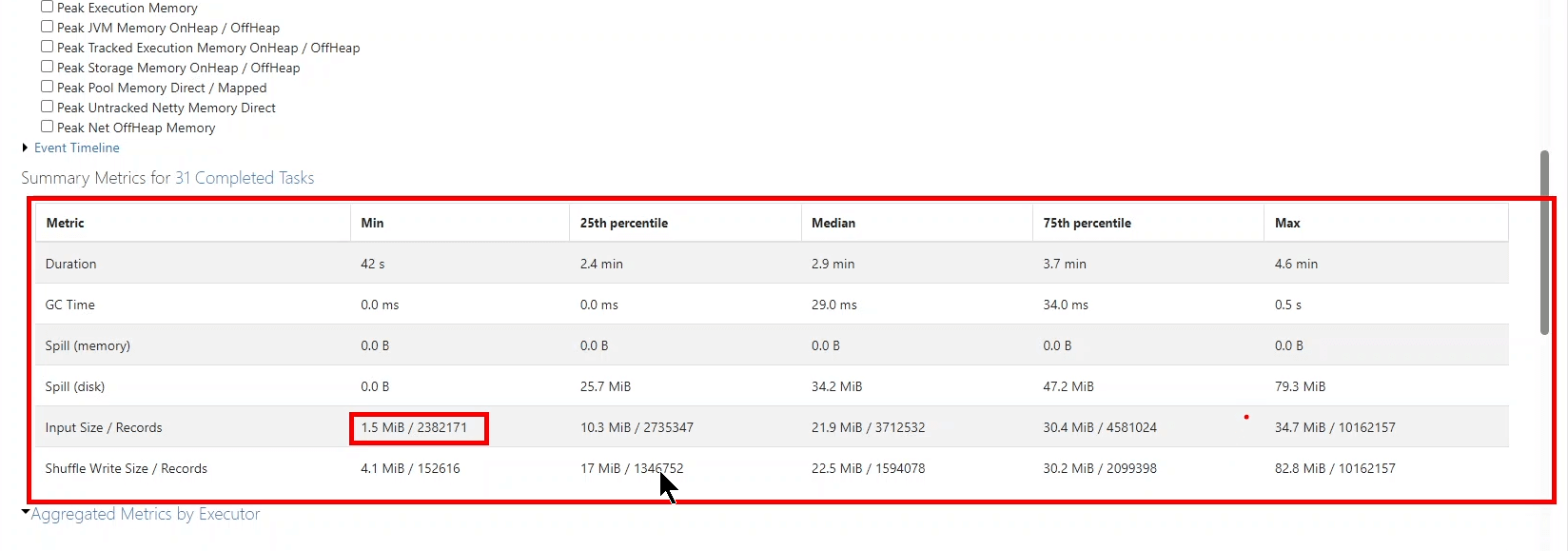
Jak to zwykle bywa zawsze jest winowajca, tak i w tym przypadku. Kiedy robisz jakieś joiny czy groupBy czy inne dziwne agregacje to Spark podczas Shuffle stworzy 200 partycji. W zależności o tego ile jest danych pojedyncze partycje mogą się różnić ich ilością. Jedna partycja może mieć 40MB a w druga 89MB. W takiej sytuacji taski (CPU) mogą dostać różne ilości danych. Jeśli pamięci jest za mało to będzie zmuszony zapisać dane na dysk. Jest to kosztowny proces ponieważ dane trzeba serializować i deserializować.
- Opis: Przepełnienie danych do dysku może znacząco wpłynąć na wydajność. Ważne jest zarządzanie pamięcią, aby minimalizować takie przepełnienia.
- Zalecenia:
- Adaptive Query Execution ustaw na auto
set spark.sql.shuffle.partitions=auto - Cache tabeli czyli załadowanie do pamięci spark.table(“table”).cache().count() sprawdź ile miejsca zajmuje tabela. Potem możesz dostroić
set spark.databricks.adaptive.autoOptimizeShuffle.preshufflePartitionSizeInBytes = 16777216żeby uzyskać mniejsza partycję może 16MB a może 8MB - Optymalizacja użycia pamięci poprzez odpowiednie ustawienia konfiguracji Spark. Zmiana Shuffle partition
- Adaptive Query Execution ustaw na auto
Każdy proces jest inny i w zależności od tego co się dzieje możesz potrzebować użyć kilku technik optymalizacji. Może wystarczy tylko jedna a może będziesz musiał przejść wszystkie 7. Pamiętaj po każdej zmianie musisz monitorować i notować obserwacje. Dzięki temu wyłapiesz co działa.