

1. Platforma analityczna
Databricks to platforma analityczna oparta na Spark. Została założona przez twórców Sparka na uniwersytecie UC Berkeley w 2013, czyli już 8 lat na rynku. Databricks pracuje nad rozwojem Sparka, łącząc siły ze społecznością wpierającą ten projekt. Jako firma dodali więcej kodu do Sparka niż jakakolwiek inna organizacja. Ta firma płaci swoje rachunki dzięki Sparkowi, więc bardzo dbają o niego. Co sprawia, że Spark jest bardzo solidnym narzędziem wspierającym bardzo duże organizacje i skomplikowane rozwiązania.
Jako platforma analityczna służy ona dwóm głównym odbiorcom Inżynierom Danych i Analitykom. Inżynierowie mogą tworzyć skomplikowane procesy przetwarzania danych. Analitycy mają gotowe środowisko do wykonania skomplikowanych analiz, dzięki czemu maja ułatwioną pracę. Maja do dyspozycji środowisko programistyczne i możliwość wizualizacji co pozwala na obserwację wyników algorytmów np. nauczania maszynowego.
Ciekawostka dotycząca Spark na dzień publikacji.
| Total Lines : | 1,412,160 | Code Lines : | 893,685 | Percent Code Lines : | 63.3% | ||
| Number of Languages : | 14 | Total Comment Lines : | 340,556 | Percent Comment Lines : | 24.1% | ||
| Total Blank Lines : | 177,919 | Percent Blank Lines : | 12.6% |
2. Databricks działa w 4 największych chmurach.
Obecnie platforma ta jest dostępna w chmurze publicznej AWS, Azure, Google Cloud oraz Alibaba. Jest to dużym ułatwieniem dla programistów, jeśli znasz Spark i Databricks to możesz wspierać każdą firmę niezależnie od wyboru chmury publicznej.

3. Wspiera wiele języków
Masz do dyspozycji Scala, R, Python i SQL. Więc dla każdego znajdzie się narzędzie do pracy.
Oprócz notatników dla developerów jest dostępnych szereg narzędzi
Python
Dla developerów znających Python są trzy możliwości pracy z Databricks,
- Jupyter with Databricks Connect
- PyCharm with Databricks Connect
R
- RStudio on Databricks
- Shiny on Databricks
Scala
- IntelliJ with Databricks Connect
SQL
- Power BI Desktop
- Tableau Desktop
- Qlik
- Looker
- TIBCO
- SQL Workbench
4. Praca w notatnikach
Databricks daje Ci możliwość pracy z notatnikami. Jeśli jesteś analitykiem lub inżynierem danych i pracowałeś z notebookami Jupitera. To znajdziesz tu coś dla siebie. Ostatnio dodano opcje dark theme do wyglądu. Poniżej znajdziesz krótkie wideo o tym jak wygląda Databricks UI.
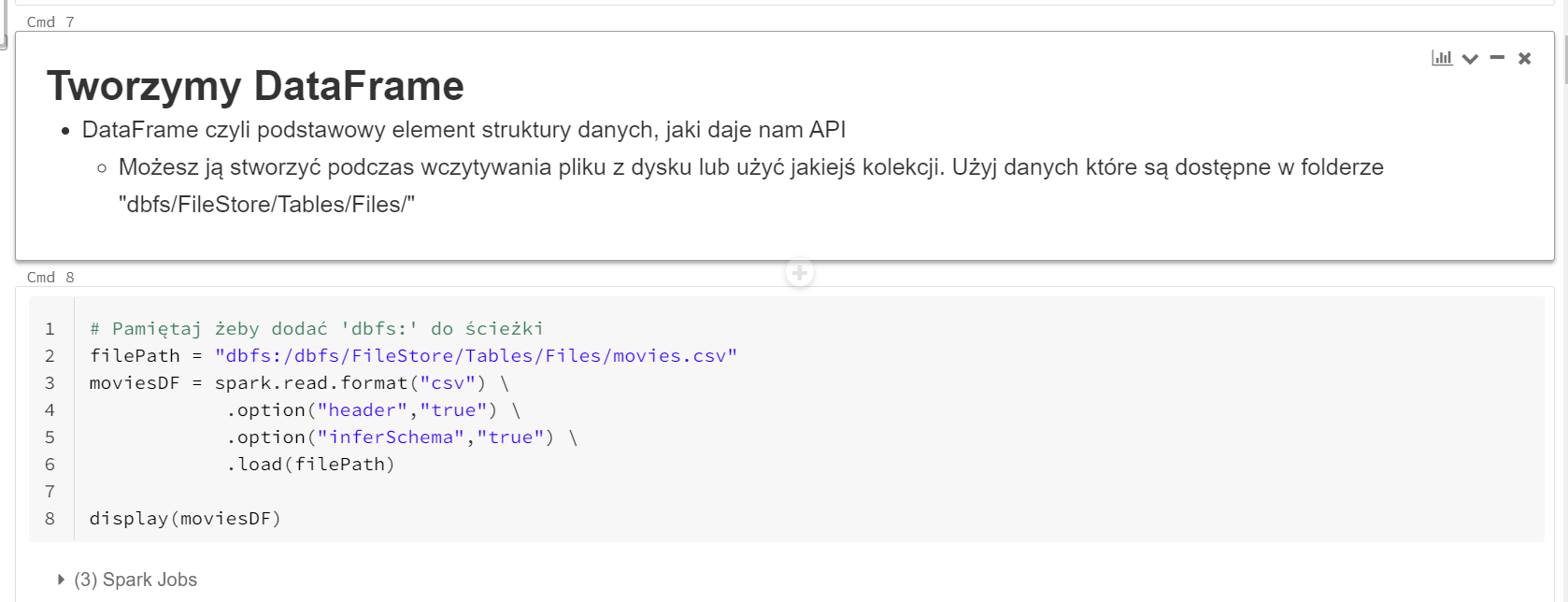
Pracując w środowisku Databricks, możesz wykonać wiele pracy, używając notatników. Każdy notatnik jest dostępny w przeglądarce. Masz tam dostęp do pojedynczych komórek. W każdej komórce możesz dodać wykonywalny kod, co upraszcza process testowania. Możesz uruchomić pojedyncze komórki lub wszystkie w danym notatniku. Oprócz tego masz możliwość budowania „workflow” czyli połączyć wiele notatników w logiczną całość. Dzięki tej funkcjonalności stworzysz bardzo wyrafinowany przepływ danych.
W notatnikach, możesz dodać opisy i notatki wyjaśniające co powinna wykonać każda komórka. Możesz użyć do tego „Markdown”.
Kolejną rewelacyjną funkcją notatników jest możliwość dzielenia się nimi. Możesz pobrać notatnik np. w formacie .HTML lub .dbc i wysłać go do kogo chcesz.
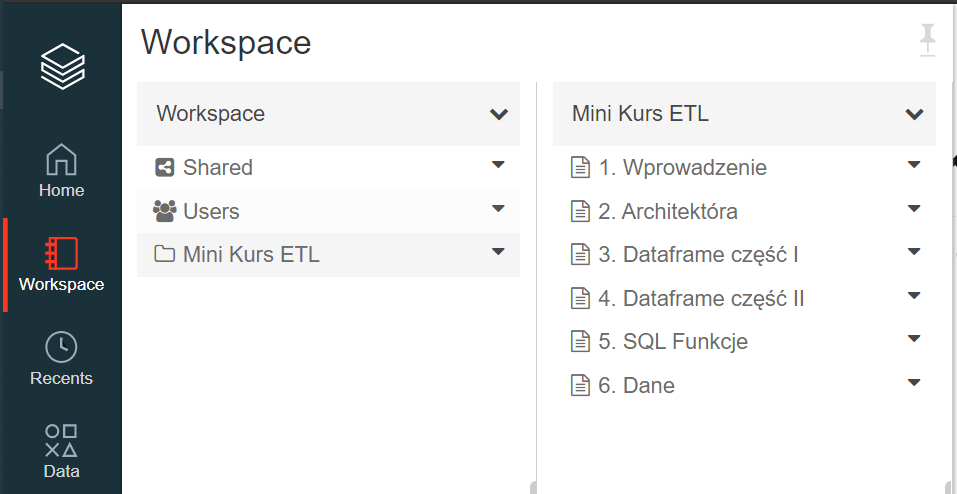
Foldery
Notatniki można zorganizować w foldery, Foldery mogą zawierać zasoby obszaru roboczego (workspace) tj. notatniki, biblioteki czy eksperymenty.
Notatnik możesz podłączyć do klastra, który sam tworzysz i dobrać do niego odpowiednie parametry. Takie jak, wielkość klastra, ilość wykonawców, ilość RAM czy wersję środowiska wykonawczego.
Integracja z Git
Każdy notatnik możesz połączyć z kontrolą wersji kodu Git.
Biblioteki
Dużo procesów możesz stworzyć w notatnikach. Jeśli potrzebujesz czegoś mocniejszego i poważniejszego, to możesz użyć bibliotek Scali lub Pythona i uruchomić je na swoim klastrze.
Biblioteki są to moduły, które poszerzają możliwości dostępnych funkcjonalności w środowisku Databricks. Biblioteki to kod, który tworzysz lokalnie, żeby przetwarzać dane zgodnie z wymaganiami twojego biznesu. Możesz je dodać do środowiska Databricks ręcznie lub zautomatyzować proces używając np. terraform lub innych rozwiązań, Azure DevOps. Kiedy zainstalujesz swoją bibliotekę na klastrze, będzie ona dostępna dla użytkowników lub aplikacji w workspace.
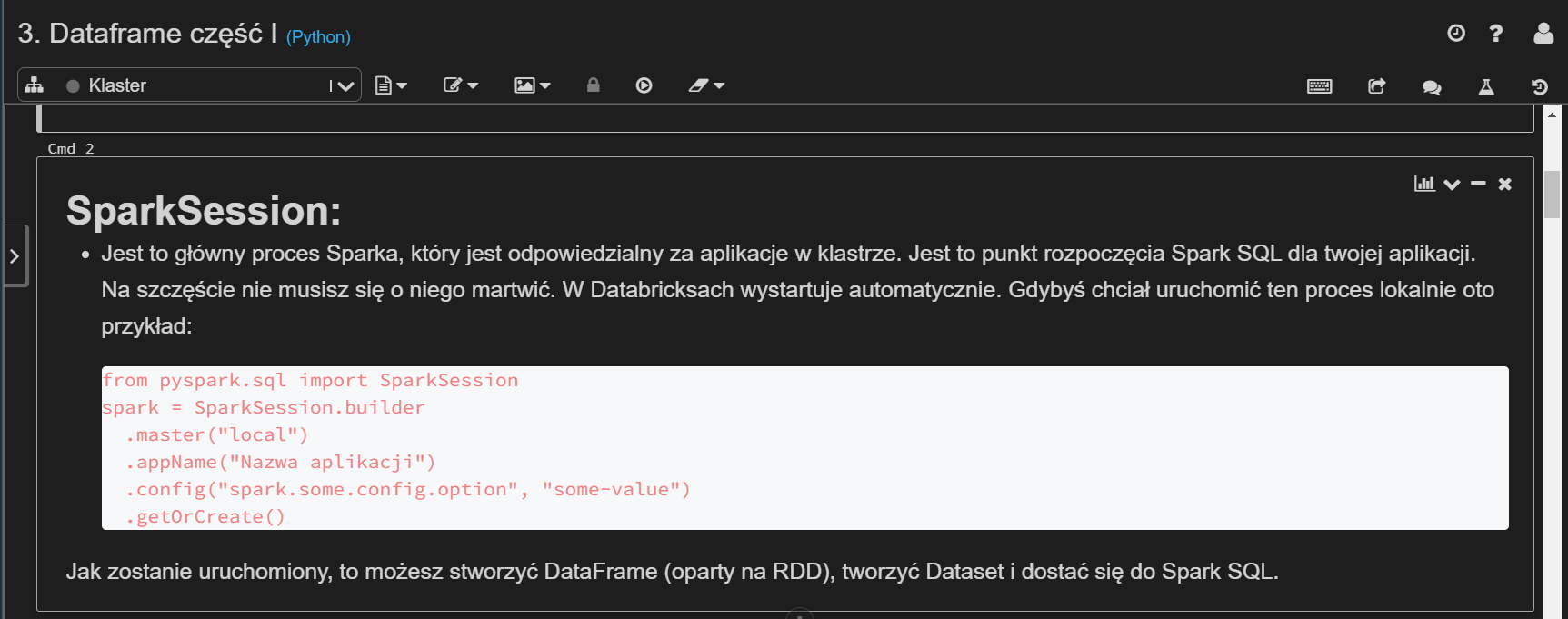
5. Nauczanie Maszynowe
W środowisku Databricks masz dostęp do biblioteki MLlib. Dzięki tej funkcjonalności możesz tworzyć eksperymenty i zarządzać MLflow z poziomu środowiska roboczego. MLlib to skalowalna biblioteka uczenia maszynowego składająca się z popularnych algorytmów, w tym klasyfikacji, regresji, grupowania, filtrowania zespołowego, redukcji wymiarowości i podstawowych elementów optymalizacyjnych.
Spark MLlib bezproblemowo integruje się z narzędziami Spark, takimi jak Spark SQL, Spark Streaming i DataFrames, i jest już gotowy do użycia w środowisku roboczym Databricks. Biblioteki można używać w językach Java, Scala i Python jako część aplikacji Spark.
6. Pełna automatyzacja środowisk w chmurze.
Dzięki temu, że jesteś w chmurze, masz możliwość zautomatyzowanie całego procesu przetwarzania danych. Databricks możesz podłączyć do innych usług chmury np. storage, bazy danych. i całą masę innych usług. Dzięki usłudze DevOps masz możliwość zarządzania całą infrastrukturą.
7. Zdalne uruchamianie kodu
Dzięki Databricks Connect masz możliwość uruchamiania kodu w swoim ulubionym środowisku IDE (IntelliJ, Eclipse, PyCharm, RStudio, Visual Studio), serwera notesów (Zeppelin, Jupyter) bezpośrednio na klastrze. Kiedy chcesz testować, debugować lub sprawdzić jak działa twoja aplikacja, uruchamiasz kod z poziomu IDE, który wykona się na klastrze, a nie w lokalnej sesji Spark. Jest bardzo ciekawe rozwiązanie, które niesamowicie ułatwia i usprawnia pracę.
Za pomocą aplikacji Databricks Connect można:
- Uruchamiaj zadania Spark na dużą skalę z dowolnej aplikacji języka Python, Java, Scala lub R. W dowolnym miejscu lub można teraz uruchamiać zadania Spark bezpośrednio z aplikacji bez konieczności instalowania wtyczek IDE.
- Przeszukaj i debuguj kod w swoim IDE nawet podczas pracy z klastrem zdalnym.
- Praca podczas tworzenia bibliotek. Nie trzeba ponownie uruchamiać klastra po modyfikacji biblioteki, ponieważ każda sesja klienta jest odizolowana od siebie w klastrze.
8. Przetwarzanie strumieniowe
Przetwarzanie strumieniowe to interfejs API Apache Spark, który umożliwia obliczenia dotyczące danych przesyłanych strumieniowo. Przykłady obejmują transakcje kartami bankowymi, logi aplikacji, dane urządzeń Internetu rzeczy (IoT), zdarzenia związane z grami wideo i wiele innych.
Silnik Spark SQL zadba o ciągłe lub przyrostowe przetwarzanie danych oraz uruchamianie i aktualizację wyniku w miarę napływu danych strumieniowych. Możesz użyć interfejsu API Dataset / Dataframe w Scali, Java, Python lub R do wyrażania agregacji strumieniowych, okien czasu i łączenia strumieni.
Przetwarzanie strumieniowe Spark składają się z dwóch części:
Źródło wejściowe, takie jak
- Kafka
- Azure Event Hub
- Pliki w systemie rozproszonym
- Gniazda TCP-IP
Miejsce docelowe (sink) takie jak
- Kafka
- Azure Event Hub
- Różne formaty plików
- Konsola systemowa
- Tabele Apache Spark (ujścia pamięci)
Kluczowe właściwości danych strumieniowych, z którymi Spark sobie poradzi:
- Dane pochodzące ze strumienia zazwyczaj nie są w żaden sposób uporządkowane
- Dane są przesyłane strumieniowo ze źródła do miejsca docelowego
- Strumień ma więcej danych niż da się przetworzyć
- Strumienie można łączyć ze sobą tworząc potok danych
- Strumienie nie muszą działać 24 godziny na dobę, 7 dni w tygodniu, można je uruchamiać okazjonalnie (logi).
9. Automatyzacja harmonogramu
Databricks daje Ci możliwość tworzenia zadań (Jobs). Jeśli chcesz, aby twój proces transformacji opary na notatnikach lub bibliotekach uruchamiał się automatycznie w wyznaczonym czasie, możesz to ustawić. Jobs czyli zadania dają Ci możliwość tworzenia harmonogramu wykonania notatników. Możesz ich użyć do automatyzacji procesów analizy i przetwarzania danych.
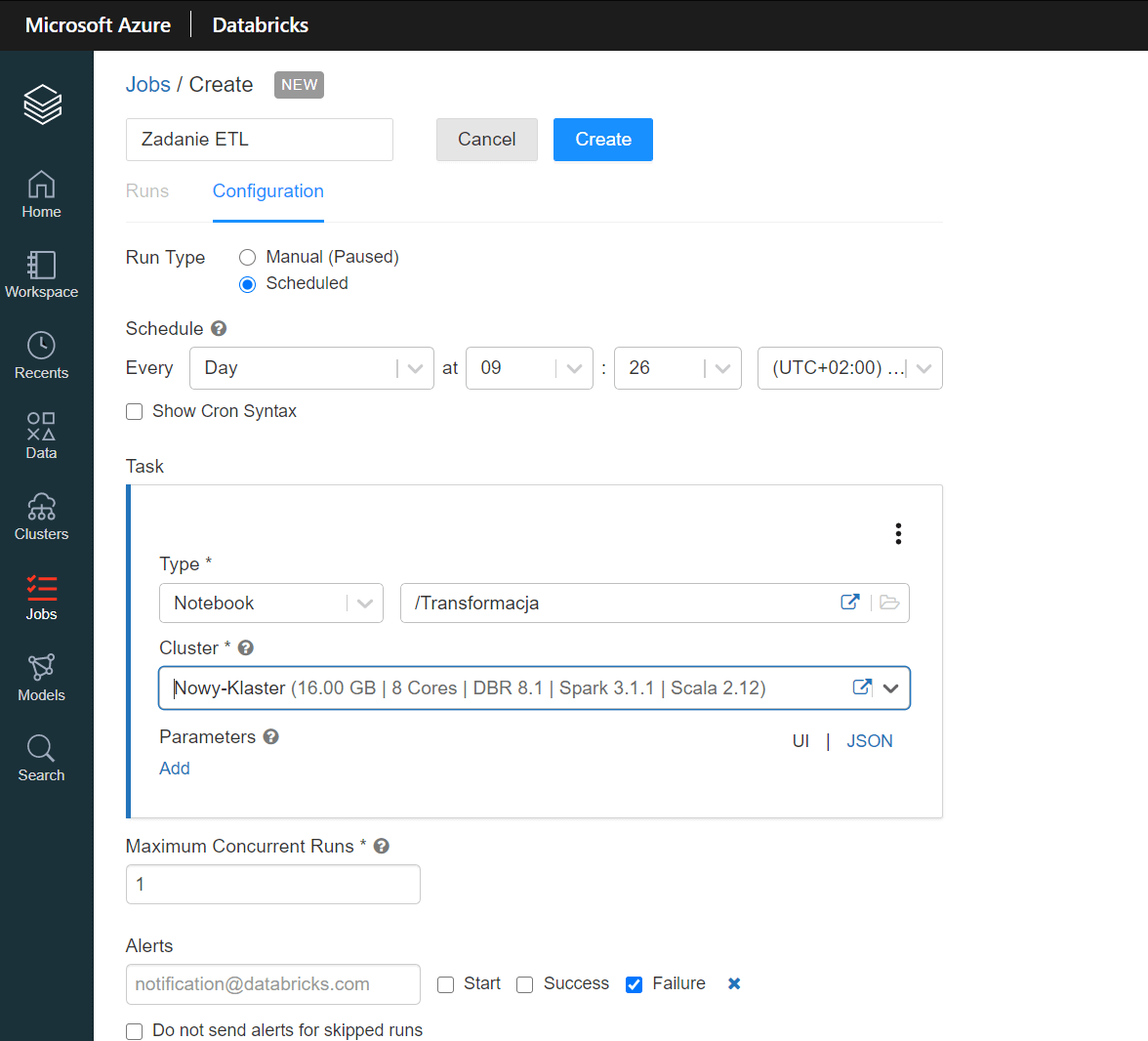
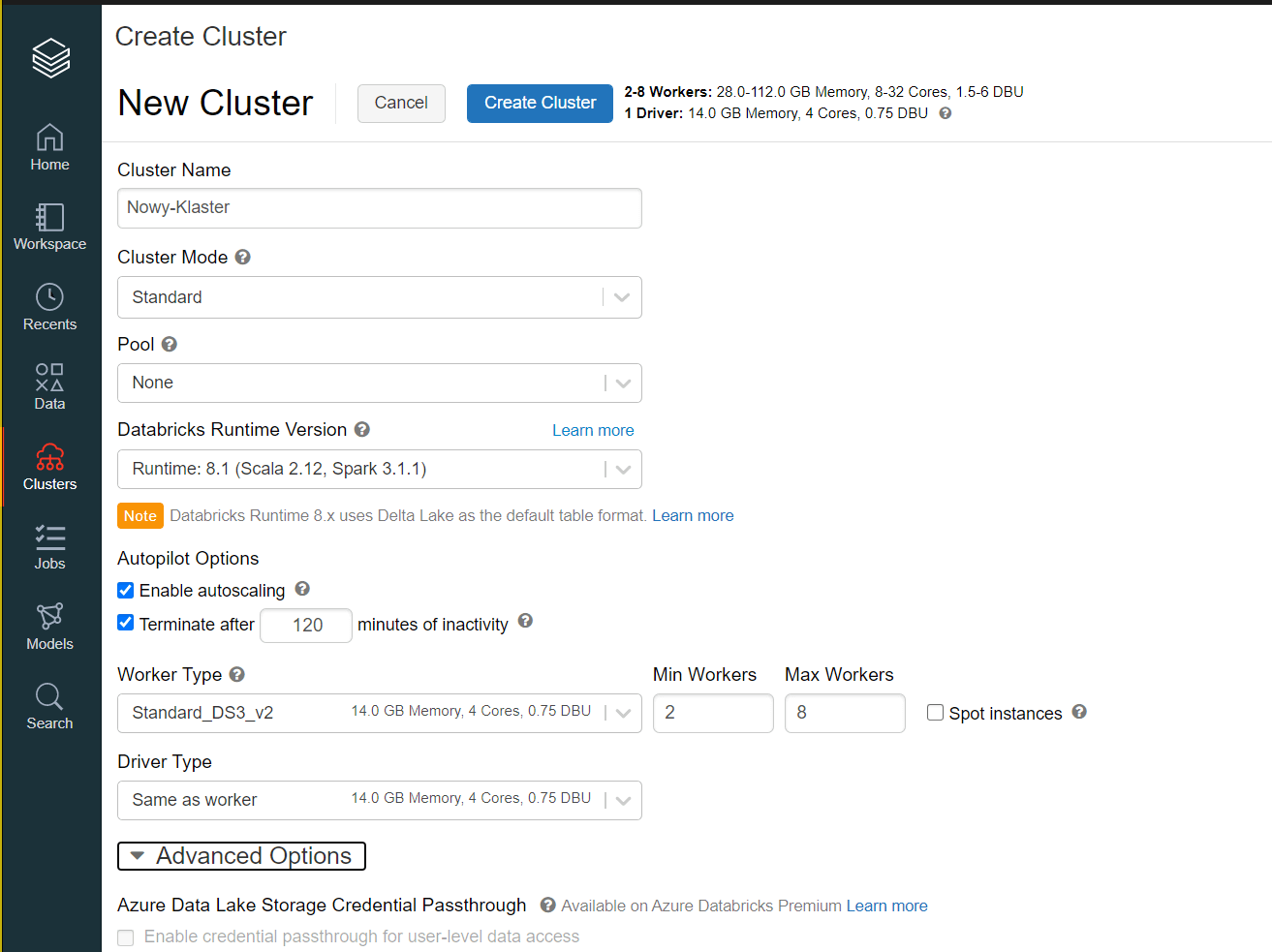
10. Klastry
Sam możesz decydować jaki klaster potrzebujesz. Databricks daje Ci możliwość wyboru mocy klastra, jaki aktualnie potrzebujesz. Jeśli chcesz żeby dobór jego mocy był automatyczny, to również masz taką możliwość.
Klaster to nic innego jak zestaw wirtualnych maszyn, które będą wykonywać twój kod. Możesz je konfigurować wedle własnych potrzeb i wymagań twojego rozwiązania. W Databricks masz dwa rodzaje klastrów „all-purpose clusters” i „job clusters„.
- Klastry All-purpose są tworzone ręcznie i używane łącznie z notatnikami.
- Klastry Job clusters są uruchamiane kiedy użytkownik ustawi harmonogram do wykonania notatnika.
11. Dane
Tabele
Dane możesz zapisać w tabelach i używając tradycyjnego SQL dokonać ich analizy lub transformacji. Dzięki tabelom możesz przetrzymywać dane ustrukturyzowane. Table możesz przetrzymywać w Amazon S3 lub Azure Blob Storage, w zależności jakiej chmury używasz. Każda tabela ma swój schemat przetrzymywany w lokalnym „Metastore”. W Databricks użytkownicy mogą konfigurować lokalizację schematów na zewnętrznym Metastores.
Dane
Użytkownicy mogą importować dane bezpośrednio do systemu plików Databricks „dbfs” lub użyć konta magazynu np. Azure Blob Storage. Apache Spark ma możliwość połączenia się z wieloma źródłami danych.
Delta Lake
Delta Lake to warstwa pamięci masowej, która zapewnia niezawodność, bezpieczeństwo i wydajność. Jest to dodatkowa funkcjonalność wspierające warstwę składowania danych. Bardzo dobrze sprawdza się w jeziorach danych (data lake). Jest w stanie obsłużyć zarówno przesyłanie strumieniowe, jak i operacje wsadowe (batch). Zastępując silosy danych pojedynczym miejscem przechowywania ustrukturyzowanych, częściowo ustrukturyzowanych i nieustrukturyzowanych danych. Delta Lake stanowi podstawę opłacalnego, wysoce skalowalnego Lakehouse.
Właściwości
- Wspiera transakcję ACID i wymuszanie schematu
- Wszystkie dane w Delta Lake są w formacie open source Apache Parquet. API są zgodne ze standardem obsługiwanym przez Apache Spark
- Współpracując z Apache Spark™, Delta Lake jest bardzo wydajnym narzędziem, które dobrze sie skaluje. Jest zoptymalizowane pod kątem procesów ETL.
- Bezpieczeństwo: Delta Lake osiada mechanism kontrolujący dostęp to danych a tym samym usprawnia zarządzanie dostępami.
- Możesz tworzyć procesy ETL bezpośrednio na danych
- Możesz uruchomić ładowanie danych bezpośrednio w data lake dla procesów business intelligence. Stanowi alternatywę dla tradycyjnych hurtowni danych.
Daj znać czy znasz Databricks i która z jego funkcji jest dla Ciebie najciekawsza ?